java.util.HashMap的简单介绍
1. java.util.HashMap的底层实现是数组+链表。
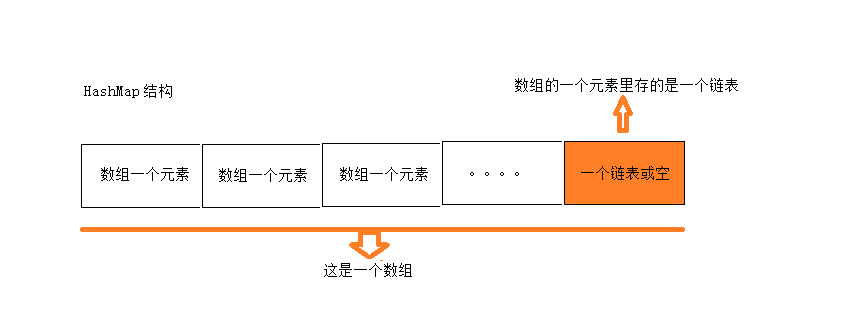
2. 简介put(key, value)方法的执行过程:
1)通过key值,使用散列算法计算出来一个hash值,用来确定该元素需要存储到数组中的哪个位置(index)。
2)根据计算出来的位置(index),可以查看该位置是否被占用:
2.1)如果位置(index)未被占用,将(key\value)封装成一个节点,保存到该位置。
2.2)如果位置(index)被占用,使用key和链表中的节点一一比较:
---->如果链表中不存在该key,将(key/value)封装成节点添加到该链表中。
---->如果链表中已存在该key,替换该key对应节点的value值。
3. 简介get(key)方法的执行过程:
1)通过key的hash值可以计算出当前元素所在链表存储在数组中的位置(index)。
2)通过key值和链表中的节点一一比较,可以得到key值对应的元素。
4. 可以看出:
1)key的hashCode方法很重要。因为要根据hashCode的值计算该元素要存在数组中的那个位置(index)。
2)key的equals方法很重要。因为要根据equals方法来比较,数组某个位置的链表中是否已包含该元素(节点)。
所以:
key/value一旦存入到map当中,不能再去改变key的值。
一旦改变了key的值(比如说改变key中某个用来生成hashCode的属性),就不能根据这个key来找到元素存在数组中的位置了。
5. 一般做法:
1)需要重写key对象类的hashCode方法。最好用可以唯一标识该对象的属性来生成hashCode。
2)需要重写key对象的equals方法。可以用唯一标识的一个或多个属性来重写equals方法。如果不重写equals方法,对象比较时,会比较在内存中的地址。
一小段代码:
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry; import org.junit.Before;
import org.junit.Test; public class TestMap { Map<User, Integer> map;
User user1;
User user2;
User user3; @Before
public void before() {
map = new HashMap<User, Integer>();
user1 = new User("320381", "zhangSan", 20);
user2 = new User("320382", "LiSi", 22);
user3 = new User("320383", "Wangwu", 25); map.put(user1, 1);
map.put(user2, 2);
map.put(user3, 3);
} // 先看看map里都有什么
@Test
public void test1() {
System.out.println(map);
// {320383-Wangwu=3, 320381-zhangSan=1, 320382-LiSi=2}
} // 改变了key值,再执行删除操作,删不掉了
@Test
public void test2() {
user1.setIdCardNo("320384");
map.remove(user1);
System.out.println(map);
// {320383-Wangwu=3, 320384-zhangSan=1, 320382-LiSi=2}
} // 遍历map-方法1
@Test
public void test3() {
for (User user : map.keySet()) {
System.out.println(user);
System.out.println(map.get(user));
}
} // 遍历map-方法2
@Test
public void test4() {
for (Entry<User, Integer> en : map.entrySet()) {
System.out.println(en.getKey());
System.out.println(en.getValue());
}
}
} class User {
private String IdCardNo;
private String name;
private int age; public User() {
super();
} public User(String idCardNo, String name, int age) {
super();
IdCardNo = idCardNo;
this.name = name;
this.age = age;
} // 重写了hashCode方法
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((IdCardNo == null) ? 0 : IdCardNo.hashCode());
return result;
} // 重写了equals方法
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
User other = (User) obj;
if (IdCardNo == null) {
if (other.IdCardNo != null)
return false;
} else if (!IdCardNo.equals(other.IdCardNo))
return false;
return true;
} // 重写了toString方法
public String toString() {
return IdCardNo + "-" + name;
}
// getters/setters(略) }
java.util.HashMap的简单介绍的更多相关文章
- java.util.HashMap和java.util.HashTable (JDK1.8)
一.java.util.HashMap 1.1 java.util.HashMap 综述 java.util.HashMap继承结构如下图 HashMap是非线程安全的,key和value都支持nul ...
- JDK1.8源码(七)——java.util.HashMap 类
本篇博客我们来介绍在 JDK1.8 中 HashMap 的源码实现,这也是最常用的一个集合.但是在介绍 HashMap 之前,我们先介绍什么是 Hash表. 1.哈希表 Hash表也称为散列表,也有直 ...
- java:警告:[unchecked] 对作为普通类型 java.util.HashMap 的成员的put(K,V) 的调用未经检查
java:警告:[unchecked] 对作为普通类型 java.util.HashMap 的成员的put(K,V) 的调用未经检查 一.问题:学习HashMap时候,我做了这样一个程序: impor ...
- 模拟java.util.Collection一些简单的用法
/* 需求:模拟java.util.Collection一些简单的用法! 注意:java虚拟机中并没有泛型类型的对象.泛型是通过编译器执行一个被称为类型擦除的前段转换来实现的. 1)用泛型的原生类型替 ...
- Mabitis 多表查询(一)resultType=“java.util.hashMap”
1.进行单表查询的时候,xml标签的写法如下 进行多表查询,且无确定返回类型时 xml标签写法如下: <select id="Volume" parameterType=&q ...
- 解决Apache CXF 不支持传递java.sql.Timestamp和java.util.HashMap类型问题
在项目中使用Apache开源的Services Framework CXF来发布WebService,CXF能够很简洁与Spring Framework 集成在一起,在发布WebService的过程中 ...
- LinkedHashMap和HashMap的比较使用 由于现在项目中用到了LinkedHashMap,并不是太熟悉就到网上搜了一下。 ? import java.util.HashMap; impo
LinkedHashMap和HashMap的比较使用 由于现在项目中用到了LinkedHashMap,并不是太熟悉就到网上搜了一下. import java.util.HashMap; import ...
- 关于spring mybateis 定义resultType="java.util.HashMap"
关于spring mybateis 定义resultType="java.util.HashMap" List<HashMap<String, Object>& ...
- org.apache.ibatis.builder.IncompleteElementException: Could not find result map java.util.HashMap
这样的配置有问题吗? <select id="getFreightCollectManagementList" resultMap="java.util.HashM ...
随机推荐
- db2调优
系统上线两个月左右,请IBM工程师对数据库进行了一次调优,主要收获感觉有以下几点: 1,应用服务器一定要与数据库服务器分开 2,如果存在多个数据库,一定要硬盘分开(io忙) 3,每个数据库的数据与日志 ...
- 一段用c#操作datatable的代码
using System; using System.Collections.Generic; using System.Data; using System.Data.SqlClient; usin ...
- Hadoop化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- (58)Wangdao.com第九天_JavaScript 对象的基本操作
对象的基本操作 创建对象 var 对象名 = new Object(); // new 函数; 称为构造函数,专门用来创建对象的函数 var god = 给对象增加属性 删除对象 ...
- 关于VIM自动缩进失效(filetype indent on无效)的详细分析
关于VIM自动缩进失效(filetype indent on无效)的详细分析 set filetype=xml filetype indent on 执行对齐命令:ggvG
- 快速排序partition过程常见的两种写法+快速排序非递归实现
这里不详细说明快速排序的原理,具体可参考here 快速排序主要是partition的过程,partition最常用有以下两种写法 第一种: int mypartition(vector<int& ...
- Swift udp实现根据端口号监听广播数据(利用GCDAsyncUdpSocket实现)
有个小需求,app需要监听pc广播的数据: 代码实现思路: 使用三方库:CocoaAsyncSocket 1.开启udp监听: udpSocket.beginReceiving() 2.读取udp的数 ...
- 物联网架构成长之路(5)-EMQ插件配置
1. 前言 上一小结说了插件的创建,这一节主要怎么编写代码,以及具体流程之类的.2. 增加一句Hello World 修改 ./deps/emq_plugin_wunaozai/src/emq_plu ...
- 最简单的基于FFmpeg的AVfilter样例(水印叠加)
===================================================== 最简单的基于FFmpeg的AVfilter样例系列文章: 最简单的基于FFmpeg的AVfi ...
- 【Big Data - ELK】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticSearch,一款基于Apache Lucene的开源分布式搜索引擎)中便于查找和分析,在研究 ...