用深度学习做命名实体识别(六)-BERT介绍
什么是BERT?
BERT,全称是Bidirectional Encoder Representations from Transformers。可以理解为一种以Transformers为主要框架的双向编码表征模型。所以要想理解BERT的原理,还需要先理解什么是Transformers。
Transformers简单来说是一个将一组序列转换成另一组序列的黑盒子,这个黑盒子内部由编码器和解码器组成,编码器负责编码输入序列,然后解码器负责将编码器的输出转换为另一组序列。具体可以参考这篇文章《想研究BERT模型?先看看这篇文章吧!》
这里需要注意的是,BERT使用的Transformers中在表示位置信息时,没有使用Positional Encoding,而是使用了Positional Embedding,所以位置信息是训练出来的,并且为了让模型能同时考虑到单词左边和右边的上下文信息,BERT使用了双向Transformers的架构。而由于位置信息是采用的embedding的方式,所以对序列的最大长度就有所限制了,受限于训练时最大序列的长度,这里BERT预训练模型的最大序列长度是512.也就是说如果训练样本超过了长度,就需要采用截断或者其他方式以保证序列的长度在512以内。
BERT能做什么?
- 文本推理
给定一对句子,预测第二个句子和第一个句子的关系:蕴含、矛盾、中性。 - 问答
给定问题和短文,从短文预测出对应span作为答案。 - 文本分类
比如对电影评论做情感预测。 - 文本相似度匹配
输入两个句子,计算语义相似度。 - 命名实体识别
给定一个句子,输出句子中特定的实体,比如人名、地址、时间等。
怎么使用BERT?
BERT有2种用法:
feature-based
直接使用BERT预训练模型提取出文本序列的特征向量。比如文本相似度匹配。fine-tuning
在预训练模型层上添加新的网络;冻结预训练模型的所有层,训练完成后,放开预训练模型的所有层,联合训练解冻的部分和添加的部分。比如文本分类、命名实体识别等。
为什么BERT能做到这些?
BERT在训练的时候采用了无监督的方式,其主要采用2种策略来得到对序列的表征。
MLM
为了训练一个深度双向表征,作者简单的随机mask一些百分比的输入tokens,然后预测那些被mask掉的tokens。这一步称为“masked LM”(MLM),在一些文献中,被称为完型填空任务(Cloze task)。mask掉的tokens对应的最后的隐藏层向量喂给一个输出softmax,像在标准的LM中一样。在实验中,作者为每个序列随机mask掉了15%的 tokens。尽管这允许作者获得双向预训练模型,其带来的负面影响是在预训练和微调模型之间创造了不匹配,因为[MASK]符号不会出现在微调阶段。所以要想办法让那些被mask掉的词的原本的表征也被模型学习到,所以这里作者采用了一些策略:
假设原句子是“my dog is hairy”,作者在3.1节 Task1中提到,会随机选择句子中15%的tokens位置进行mask,假设这里随机选到了第四个token位置要被mask掉,也就是对hairy进行mask,那么mask的过程可以描述如下:
- 80% 的时间:用[MASK]替换目标单词,例如:my dog is hairy --> my dog is [MASK] 。
- 10% 的时间:用随机的单词替换目标单词,例如:my dog is hairy --> my dog is apple 。
- 10% 的时间:不改变目标单词,例如:my dog is hairy --> my dog is hairy 。 (这样做的目的是使表征偏向于实际观察到的单词。)
上面的过程,需要结合训练过程的epochs来理解,每个epoch表示学完了一遍所有的样本,所以每个样本在多个epochs过程中是会重复输入到模型中的,知道了这个概念,上面的80%,10%,10%就好理解了,也就是说在某个样本每次喂给模型的时候,用[MASK]替换目标单词的概率是80%;用随机的单词替换目标单词的概率是10%;不改变目标单词的概率是10%。
有的介绍BERT的文章中,讲解MLM过程的时候,将这里的80%,10%,10%解释成替换原句子被随机选中的15%的tokens中的80%用[MASK]替换目标单词,10%用随机的单词替换目标单词,10%不改变目标单词。这个理解是不对的。
然后,作者在论文中谈到了采取上面的mask策略的好处。大致是说采用上面的策略后,Transformer encoder就不知道会让其预测哪个单词,或者说不知道哪个单词会被随机单词给替换掉,那么它就不得不保持每个输入token的一个上下文的表征分布(a distributional contextual representation)。也就是说如果模型学习到了要预测的单词是什么,那么就会丢失对上下文信息的学习,而如果模型训练过程中无法学习到哪个单词会被预测,那么就必须通过学习上下文的信息来判断出需要预测的单词,这样的模型才具有对句子的特征表示能力。另外,由于随机替换相对句子中所有tokens的发生概率只有1.5%(即15%的10%),所以并不会影响到模型的语言理解能力。
NSP
许多下游任务,比如问答,自然语言推理等,需要基于对两个句子之间的关系的理解,而这种关系不能直接通过语言建模来获取到。为了训练一个可以理解句子间关系的模型,作者为一个二分类的下一个句子预测任务进行了预训练,这些句子对可以从任何单语言的语料中获取到。特别是,当为每个预测样例选择一个句子对A和B,50%的时间B是A后面的下一个句子(标记为IsNext), 50%的时间B是语料库中的一个随机句子(标记为NotNext)。图1中,C用来输出下一个句子的标签(NSP)。
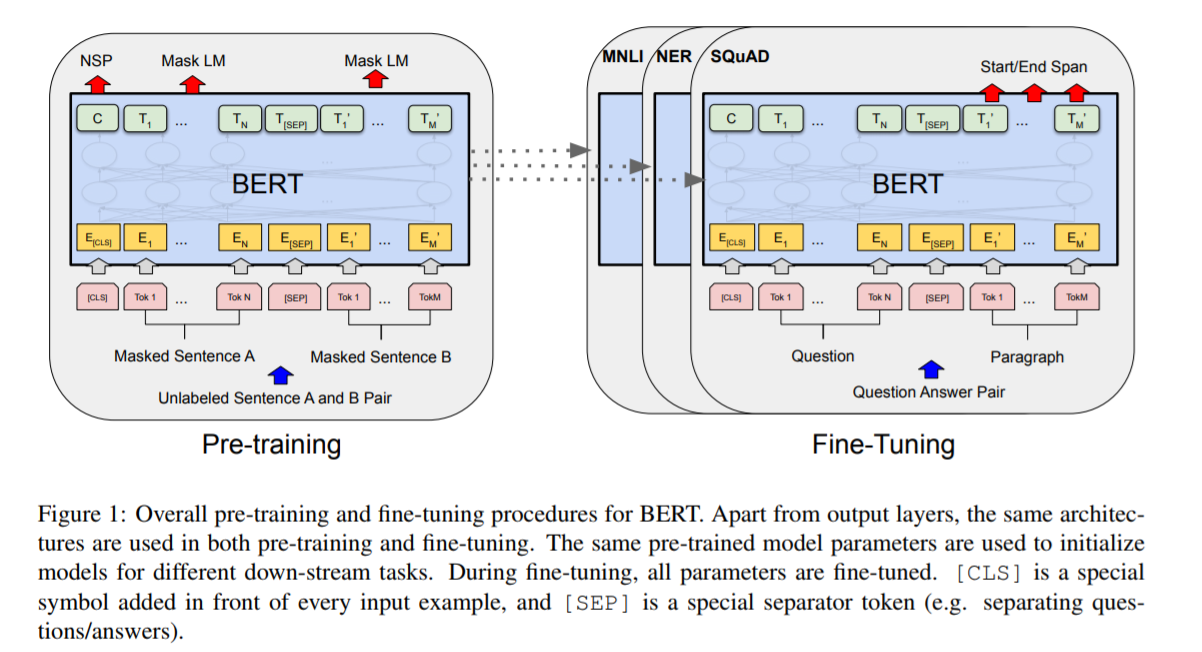
”下个句子预测“的任务的例子:
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
还有哪些模型可以做到这些,它们和BERT的区别是什么?
论文中作者提到了另外的两个模型,分别是OpenAI GPT和ELMo。
图3展示了这3个模型架构的对比:
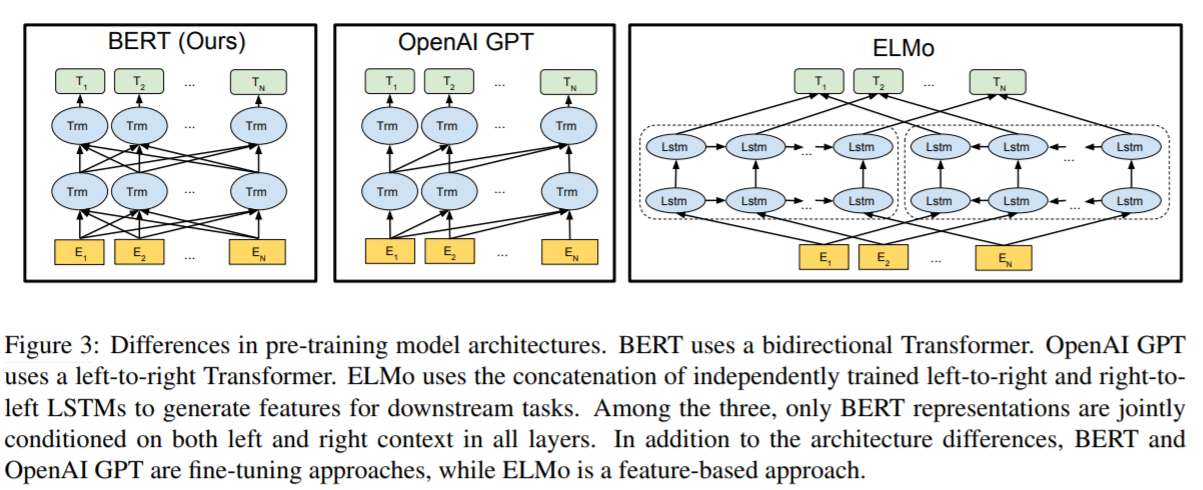
- BERT使用了双向的Transformer架构,预训练阶段使用了MLM和NSP。
- OpenAI GPT使用了left-to-right的Transformer。
- ELMo分别使用了left-to-right和right-to-left进行独立训练,然后将输出拼接起来,为下游任务提供序列特征。
上面的三个模型架构中,只有BERT模型的表征在每一层都联合考虑到了左边和右边的上下文信息。另外,除了架构不同,还要说明的一点是:BERT和OpenAI GPT是基于fine-tuning的方法,而ELMo是基于feature-based的方法。
更多细节
请阅读原论文,或者参考笔者的这篇文章《BERT论文解读》。
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。
用深度学习做命名实体识别(六)-BERT介绍的更多相关文章
- 用深度学习做命名实体识别(七)-CRF介绍
还记得之前介绍过的命名实体识别系列文章吗,可以从句子中提取出人名.地址.公司等实体字段,当时只是简单提到了BERT+CRF模型,BERT已经在上一篇文章中介绍过了,本文将对CRF做一个基本的介绍.本文 ...
- 用深度学习做命名实体识别(二):文本标注工具brat
本篇文章,将带你一步步的安装文本标注工具brat. brat是一个文本标注工具,可以标注实体,事件.关系.属性等,只支持在linux下安装,其使用需要webserver,官方给出的教程使用的是Apac ...
- NLP入门(五)用深度学习实现命名实体识别(NER)
前言 在文章:NLP入门(四)命名实体识别(NER)中,笔者介绍了两个实现命名实体识别的工具--NLTK和Stanford NLP.在本文中,我们将会学习到如何使用深度学习工具来自己一步步地实现N ...
- 用CRF做命名实体识别(一)
用CRF做命名实体识别(二) 用CRF做命名实体识别(三) 用BILSTM-CRF做命名实体识别 博客园的markdown格式可能不太方便看,也欢迎大家去我的简书里看 摘要 本文主要讲述了关于人民日报 ...
- 用CRF做命名实体识别(二)
用CRF做命名实体识别(一) 用CRF做命名实体识别(三) 一. 摘要 本文是对上文用CRF做命名实体识别(一)做一次升级.多添加了5个特征(分别是词性,词语边界,人名,地名,组织名指示词),另外还修 ...
- 使用CRF做命名实体识别(三)
摘要 本文主要是对近期做的命名实体识别做一个总结,会给出构造一个特征的大概思路,以及对比所有构造的特征对结构的影响.先给出我最近做出来的特征对比: 目录 整体操作流程 特征的构造思路 用CRF++训练 ...
- 手把手教你用深度学习做物体检测(五):YOLOv1介绍
"之前写物体检测系列文章的时候说过,关于YOLO算法,会在后续的文章中介绍,然而,由于YOLO历经3个版本,其论文也有3篇,想全面的讲述清楚还是太难了,本周终于能够抽出时间写一些YOLO算法 ...
- 手把手教你用深度学习做物体检测(七):YOLOv3介绍
YOLOv3 论文:< YOLOv3: An Incremental Improvement > 地址: https://arxiv.org/pdf/1804.02767.pdfyolov ...
- NLP入门(八)使用CRF++实现命名实体识别(NER)
CRF与NER简介 CRF,英文全称为conditional random field, 中文名为条件随机场,是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机 ...
随机推荐
- HDU-6333 Problem B. Harvest of Apples 莫队
HDU-6333 题意: 有n个不同的苹果,你最多可以拿m个,问有多少种取法,多组数据,组数和n,m都是1e5,所以打表也打不了. 思路: 这道题要用到组合数的性质,记S(n,m)为从n中最多取m个的 ...
- HDU1814Peaceful Commission求2-sa最小字典序
#include <iostream> #include <cstdio> #include <vector> #include <cstring> # ...
- ZOJ-3964 Yet Another Game of Stones
Yet Another Game of Stones 题意: Alice 和 Bob 在进行取石子游戏, 现在一共有n堆石子, 每堆石头有ai个, 然后每堆石头有一个bi属性, 如果bi == 0, ...
- hdu 2615 Division(暴力)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2615 题解:挺简单的暴力枚举,小小的分治主要是看没人写题解就稍微写一下 #include <io ...
- zoj - 4059 Kawa Exam scc + dsu
Kawa Exam 题解:先scc把图变成树, 然后对于这若干棵树在进行dsu的操作. dsu就是先找到最大的子树放在一边,然后先处理小的子树,最后处理大的子树.无限递归. 重要的一点就是 是否重新添 ...
- [译]Introduction to Concurrency in Spring Boot
当我们使用springboot构建服务的时候需要处理并发.一种错误的观念认为由于使用了Servlets,它对于每个请求都分配一个线程来处理,所以就没有必要考虑并发.在这篇文章中,我将提供一些建议,用于 ...
- 带你深入了解NPM——NPM初学者指南
前段时间,我们邀请了我们“城内”(葡萄城)资深开发工程师刘涛为大家分享了一次干货满满的关于Electron线上公开课,在课程过程中有不少同学对于NPM的概念和用法有一些疑问,所以这次我们希望通过这篇文 ...
- Day005_Linux基础之文件权限
test.sh 举例: [oldboy@luffy001 ~]$ ls -l test.sh -rw-r--r-- 1 oldboy ops 0 Nov 14 10:42 test.sh 该文件权 ...
- Navicat Premium基本使用
Navicat Premium基本使用 转自:https://blog.csdn.net/Yangchenju/article/details/80633055 Navicat Premium基本使用 ...
- 基于Python的多线程与多进程
1.I/O密集型与计算密集型 多进程适用于I/O密集型 多进程适用于计算密集型 2.没有sleep(T)的多个死循环只能用多进程 3.模块介绍: 1)threading模块(_thread模块已淘汰) ...