二、HDFS(架构、读写、NN)
一、HDFS定义
HDFS (Hadooop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合走来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
二、HDFS优缺点
2.1、优点
1) 高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性。
- 某一个副本丢失后,它可以自动恢复。
2) 适合处理大数据
- 数据规模:能够处理数据规模达GB、TB、甚至PB级别的数据;
- 文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3) 可构建在廉价机器上,通过多副本机制,提高可靠性。
2.2 缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的
2)无法高效的对大量小文件进行存储
- 存储大量小文件的话,它会占用NameNode大量的内存来存储和目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3)不支持并发写入、文件随机修改。
- 一个文件只能有一个写,不允许多个线程同时写
- 仅支持数据append(追加),不支持文件的随机修改。
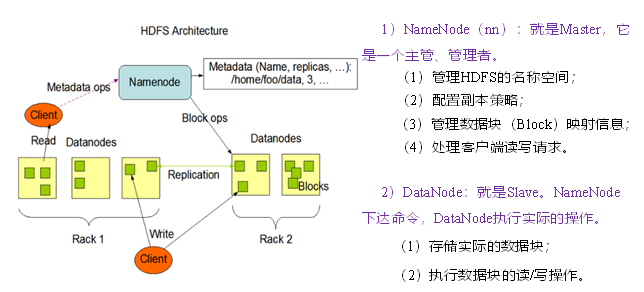
三、HDFS组成架构

四、HDFS写数据流程(参考)
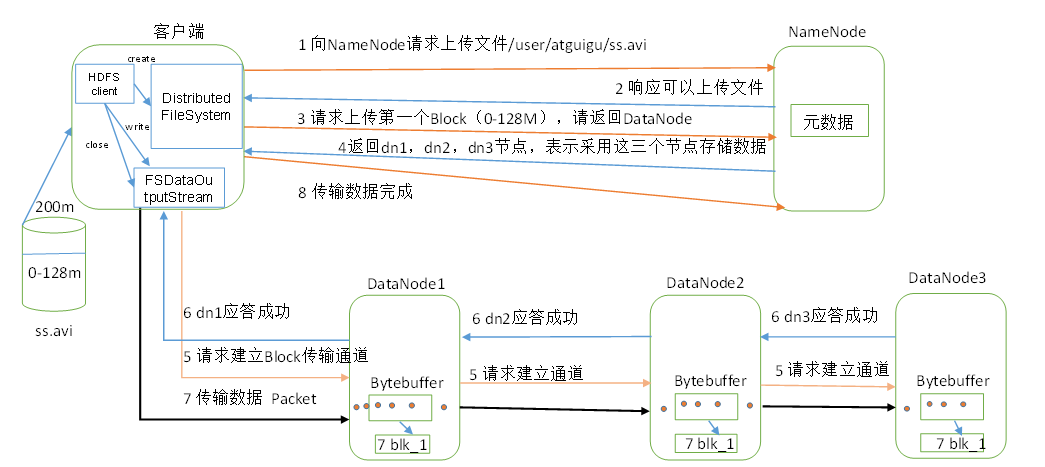
1.Client调用DistributedFileSystem对象的create方法,创建一个文件输出流(FSDataOutputStream)对象。
2.通过DistributedFileSystem对象与Hadoop集群的NameNode进行一次RPC远程调用,在HDFS的Namespace中创建一个文件条目(Entry),该条目没有任何的Block。
3.通过FSDataOutputStream对象,向DataNode写入数据,数据首先被写入FSDataOutputStream对象内部的Buffer中,然后数据被分割成一个个Packet数据包。
4.以Packet最小单位,基于Socket连接发送到按特定算法选择的HDFS集群中一组DataNode(正常是3个,可能大于等于1)中的一个节点上,在这组DataNode组成的Pipeline上依次传输Packet。
5.这组DataNode组成的Pipeline反方向上,发送ack,最终由Pipeline中第一个DataNode节点将Pipeline ack发送给Client。
6.完成向文件写入数据,Client在文件输出流(FSDataOutputStream)对象上调用close方法,关闭流。
7.调用DistributedFileSystem对象的complete方法,通知NameNode文件写入成功。
在向HDFS中写数据的时候,当写某一副本时出错怎么处理?
1.首先会关闭管线。
2.将已经发送到管道中但是没有收到确认的数据包重新写回数据队列,这样无论哪个节点发生故障,都不会发生数据丢失。这个过程是在确认队列中将未收到确认的数据包删除,写回到数据队列。
3.然后当前正常工作的数据节点将会被赋予一个新的版本号(利用namenode中租约的信息可以获得最新的时间戳版本),这样故障节点恢复后由于版本信息不对,故障DataNode恢复后会被删除。
4.在当前正常的datanode中根据租约信息选择一个主DataNode,并与其他正常DataNode通信,获取每个DataNode当前数据块的大小,从中选择一个最小值,将每个正常的DataNode同步到该大小。然后重新建立管道。
5.在管线中删除故障节点,并把数据写入管线中剩下的正常的DataNode,即新的管道。
6.当文件关闭后,namenode发现副本数量不足时会在另一个节点上创建一个新的副本。
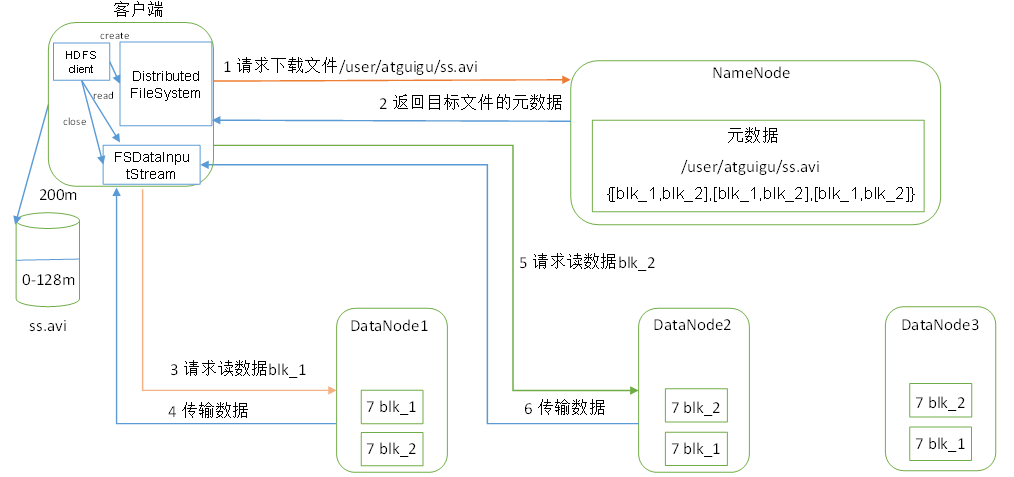
五、HDFS读数据流程
1.初始化FileSystem,然后客户端用FileSystem的open函数打开文件
2.FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
3.FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用FSDI的read()函数开始读取数据。
4.FSDataInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端。
5.当此数据块读取完毕时,FSDataInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
6.当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
7.在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
8.失败的数据节点会被记录,此后不再连接。
六、NN和2NN工作机制 (Fsimage 与 EditLog定义及合并过程)
fsimage文件:即命名空间映像文件,是内存中的元数据在硬盘上的checkpoint,包含文件系统中的所有目录和文件inode的序列化信息。
edits:文件系统的写操作首先把它记录在edit中。
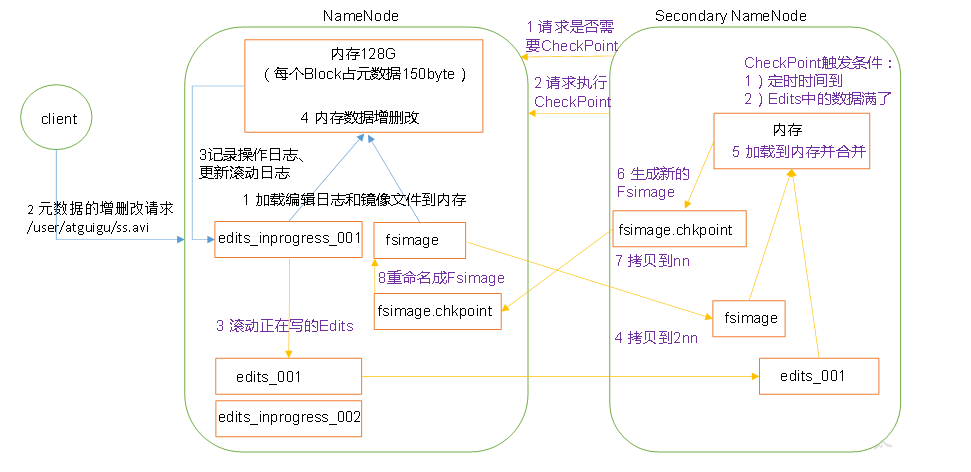
合并过程:
1.secondary namenode通过周期性(五分钟),通过getEditLog获取editlog大小,当其达到合并的大小时通过RollEditLog方法进行合并。
2.namenode停止使用edits文件,并生成一个新的临时的edits.new文件。
3.Secondarynamenode通过namenode内建的Http服务器,以get的方式获取edits与fsimage文件。Get方法中携带着fsimage与edits的路径。
4.Secondaryname将fsimage载入内存并逐一执行edits中的操作,生成新的fsimage文件。
5.执行结束后,会向namenode发送http请求,告知namenode合并结束,namenode通过http post的方式获取新fsimage文件。
6.Namenode更新fsimage文件中记录检查点执行的时间,并改名为fsimage文件。
7.Edit.new文件更名为edit文件。
注:由此可知namenode 与 secondarynamenode 有着相似的内存需求,因为secondarynamenode也会将fsimage载入内存,因此secondarynamenode需要运行在一台专门机器上。
七、DataNode工作机制
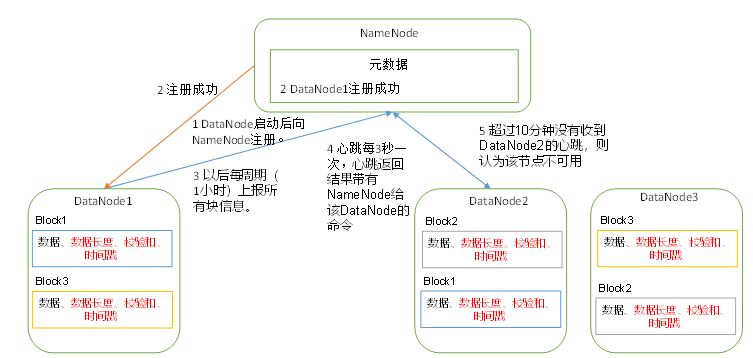
1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
二、HDFS(架构、读写、NN)的更多相关文章
- 大数据技术hadoop入门理论系列之二—HDFS架构简介
HDFS简单介绍 HDFS全称是Hadoop Distribute File System,是一个能运行在普通商用硬件上的分布式文件系统. 与其他分布式文件系统显著不同的特点是: HDFS是一个高容错 ...
- 06_Hadoop分布式文件系统HDFS架构讲解
mr 计算框架 假如有三台机器 统领者master 01 02 03 每台机器都有过滤的应用程序 移动数据 01机== 300M >mr 移动计算 java程序传递给各个机器(mr) ...
- HDFS 架构简述
HDFS 架构简述 Hadoop分布式文件系统(HDFS)是一个分布式的文件系统,运行在廉价的硬件上.它与现有的分布式文件系统有很多相似之处.然而与其他的分布式文件系统的差异也是显着的.HDFS是高容 ...
- 深入理解Hadoop之HDFS架构
Hadoop分布式文件系统(HDFS)是一种分布式文件系统.它与现有的分布式文件系统有许多相似之处.但是,与其他分布式文件系统的差异是值得我们注意的: HDFS具有高度容错能力,旨在部署在低成本硬件上 ...
- hadoop之hdfs架构详解
本文主要从两个方面对hdfs进行阐述,第一就是hdfs的整个架构以及组成,第二就是hdfs文件的读写流程. 一.HDFS概述 标题中提到hdfs(Hadoop Distribute File Syst ...
- 小记---------Hadoop读、写文件步骤,HDFS架构理解
Hadoop 是一个开源框架,可编写和运行分布式应用处理大规模数据 Hadoop框架的核心是HDFS 和 MapReduce HDFS是分布式文件系统(存储) MapReduce是分布式数据处理模型和 ...
- 2、Hdfs架构设计与原理分析
文章目录 1.Hadoop架构 2.HDFS体系架构 2.1NameNode 2.1.1元数据信息 2.1.2NameNode文件操作 2.1.3NameNode副本 2.1.4NameNode心跳机 ...
- HDFS的读写流程——宏观与微观
HDFS的读写流程--宏观与微观 HDFS:分布式文件系统,负责存放数据 分布式文件系统:就是将我们的数据放到多台电脑上存储. 写数据:就是将客户端上的数据上传到HDFS 宏观过程 客户端向HDFS发 ...
- HDFS 架构解析
本文以 Hadoop 提供的分布式文件系统(HDFS)为例来进一步展开解析分布式存储服务架构设计的要点. 架构目标 任何一种软件框架或服务都是为了解决特定问题而产生的.还记得我们在 <分布式存储 ...
- HDFS概述(1)————HDFS架构
概述 Hadoop分布式文件系统(HDFS)是一种分布式文件系统,用于在普通商用硬件上运行.它与现有的分布式文件系统有许多相似之处.然而,与其他分布式文件系统的区别很大.HDFS具有高度的容错能力,旨 ...
随机推荐
- git零基础快速入门实战,重点讲解,在实际生产中整合idea对版本、分支的管理等
1.什么是版本管理 (多人协作)项目中常见的问题: 代码放在什么地方 ?? 同步(到服务器),代码的冲突问题 ?? 服务器访问权限问题 ?? (代码)服务器内容修改的细节 ?? 项目版本的发布 ?? ...
- python生产者和消费者模式实现(二)多进程方式
import timeimport randomfrom multiprocessing import Process, Queue # 生产者def producer(q, i): food = ' ...
- Django框架(二十四)-- Django rest_framework-路由控制与响应器
一.路由控制 # 1.基本路由: url(r'^publish/$', views.PublishView.as_view()), # 2.半自动路径:views.PublishView.as_vie ...
- Jetbrain系列编辑器设置忽略目录(node_moudles)
使用Vue 或React开发,或者nodejs开发,用Idea/Webstrom 打开项目的时候,Updating Indexes到node_moudles目录的时候 会很慢很慢很慢.... 可以设置 ...
- 开始认识java
1.java发展历史 1991年 詹姆斯·高斯林 (James Gosling) SUN公司Green项目(消费类电子产品) Oak ...
- Vue 动态粒子特效(vue-particles)
图上那些类似于星座图的点和线 是由vue-particles生成的,不仅自己动,而且能与用户鼠标事件产生互动. 是非常炫的一种动态特效 可以在Vue项目中使用,需要安装第三方依赖 使用步骤 1. 安装 ...
- vue-cli2 打包
npm run build 打包安装 相当于静态资源 解决vue-cli项目打包出现空白页和路径错误的问题 路径错误的问题解决方式: 打开config文件夹下的 index.js 找到如下图所示区域: ...
- mysql group by 的用法解析
1. group by的常规用法 group by的常规用法是配合聚合函数,利用分组信息进行统计,常见的是配合max等聚合函数筛选数据后分析,以及配合having进行筛选后过滤. 聚合函数max se ...
- FineUIPro v6.0.0 大版本更新,快来围观!
本月末(2019-09-20),我们会发布激动人心的 FineUI v6.0.0 版本,这个版本将带来一系列的重要更新! 在列举新版本特性之前,我们先来回顾下每次发布大版本的关键时间点: v1.0.0 ...
- 【Java语言特性学习之四】常用集合
java中常见的数据结构