C#+Selenium抓取百度搜索结果前100网址
需求
爬取百度搜索某个关键字对应的前一百个网址。
实现方式
VS2017 + Chrome
.NET Framework + C# + Selenium(浏览器自动化测试框架)
环境准备
创建控制台应用程序,通过NuGet添加对Selenium的引用
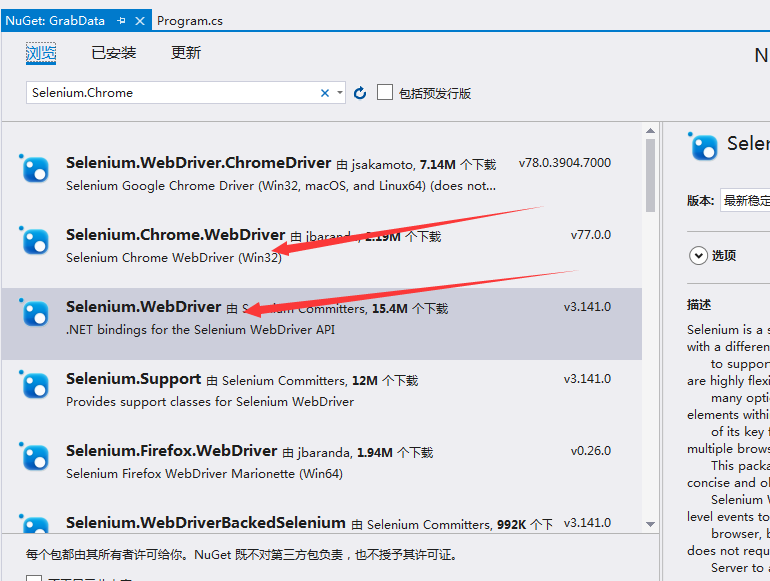
这里因为我用的Google浏览器,所以添加这两个的引用。
代码输出
static void GrabUrlByKeyWord(string keyWord)
{
//创建chrome驱动程序
IWebDriver webDriver = new ChromeDriver();
//跳至百度
webDriver.Navigate().GoToUrl("https://www.baidu.com");
//找到页面上的搜索框 输入关键字
webDriver.FindElement(By.Id("kw")).SendKeys(keyWord);
//点击搜索按钮
webDriver.FindElement(By.Id("su")).Click();
}
运行看一下效果先
static void Main(string[] args)
{
GrabUrlByKeyWord("香香瓜子");
}
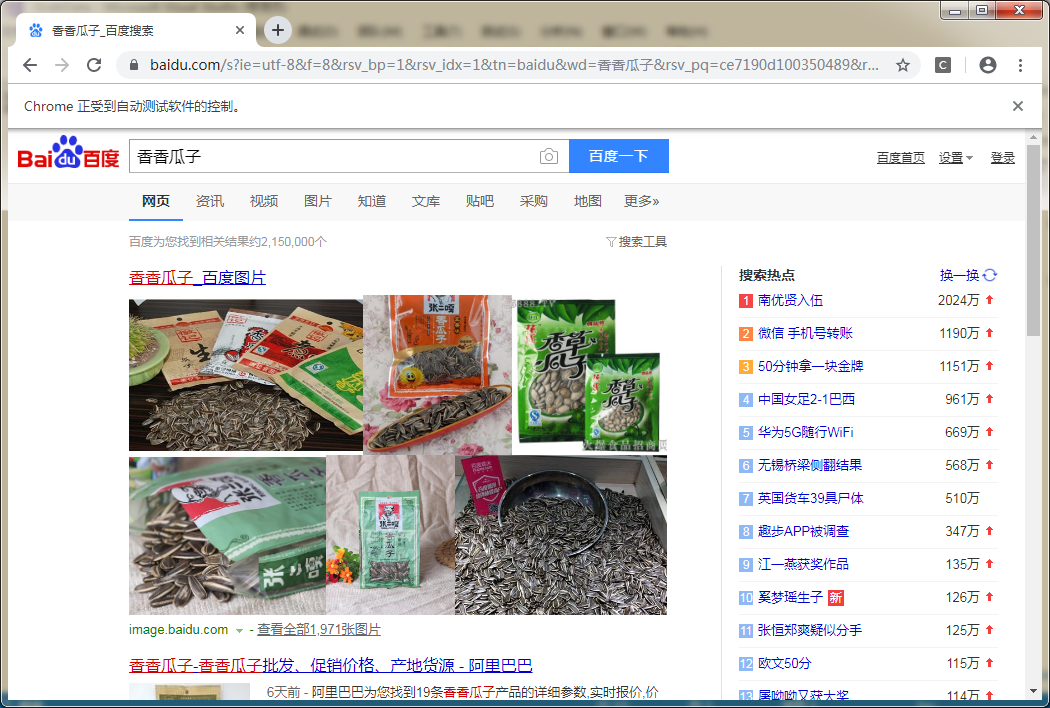
是不是感觉太简单了,这么快就来到目标页面了(这么想就太天真了。。)
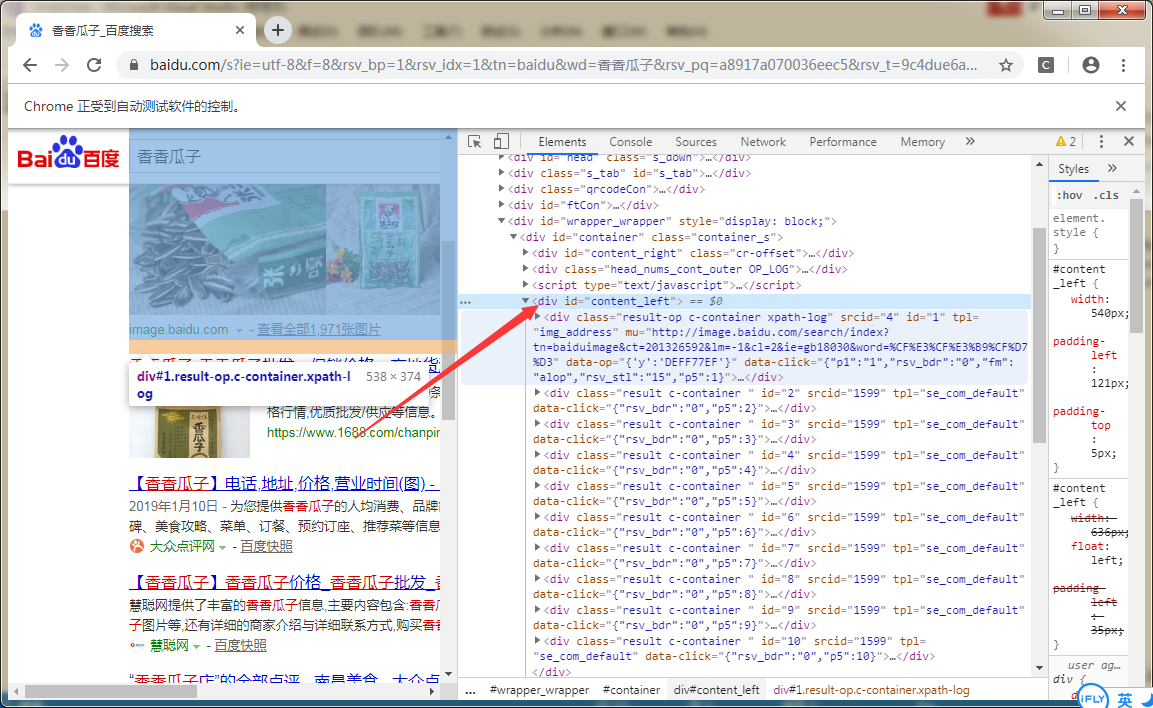
F12,观察发现搜索结果都在一个id为content_left的div中,进一步解刨
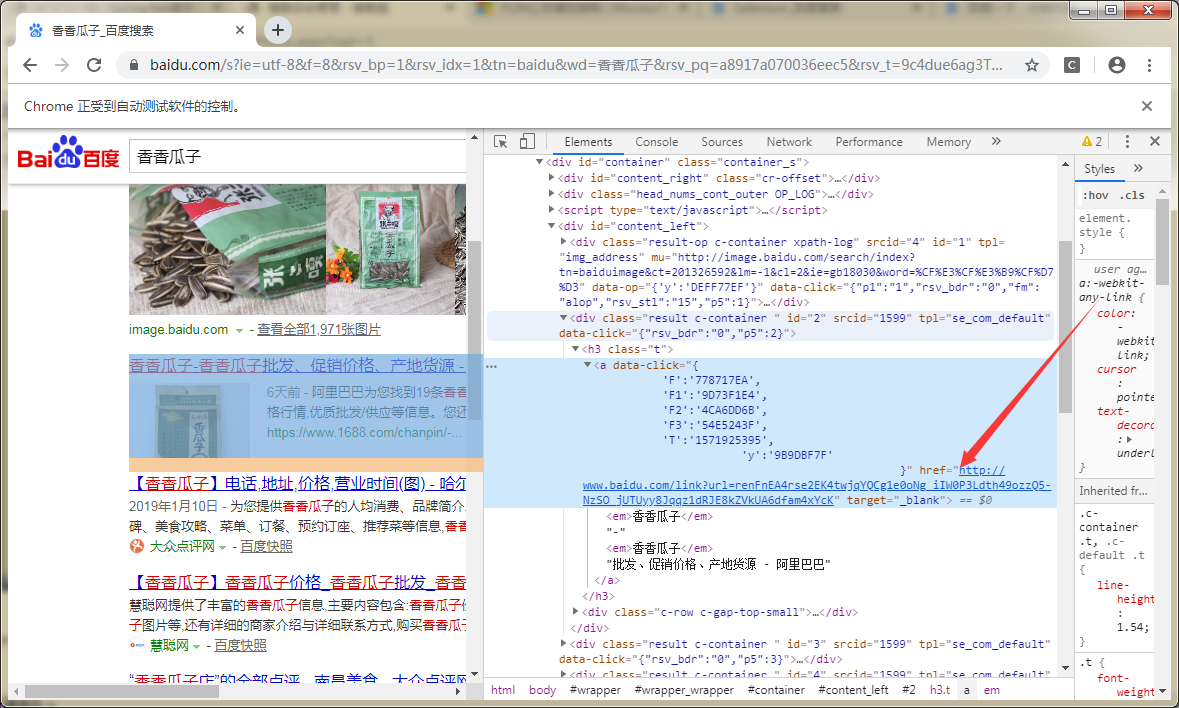
百度对目标做了中转,最关键的是它对目标url做了加密。。。
那么?问题来了,我们怎么获取到目标真实的网址呢?
当然,方法有很多:
①可以通过Selenium模拟真实操作,每个结果都点进去,获取地址栏的网址;(这样效率是不是太低了。。。)
②解密;(目前我还没有找到解密方法。。。)
③后台通过HttpClient发送请求,获取url;
......
......
......
把想说的思想总结一下:
使用HttpClient一个一个去请求的地址来获取真实地址的话,这样效率很低,
使用PLINQ并行查询 或 多线程 的话,效率变高了,但是它的执行顺序是不定的,
我们需要的结果又是排名的顺序,这时候可以把操作对象封装成不依赖顺序的model,
例如给model加一个rank排名属性,后期可以根据该属性进行处理。
贴一段来自Microsoft的文本:
虽然可以指示 PLINQ 暂留任何源序列的顺序,但这会对性能产生不利影响。 最佳做法是,尽量将查询的结构设计为不依赖顺序暂留。
C#+Selenium抓取百度搜索结果前100网址的更多相关文章
- selenium-java web自动化测试工具抓取百度搜索结果实例
selenium-java web自动化测试工具抓取百度搜索结果实例 这种方式抓百度的搜索关键字结果非常容易抓长尾关键词,根据热门关键词去抓更多内容可以用抓google,百度的这种内容容易给屏蔽,用这 ...
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
- 使用python抓取百度搜索、百度新闻搜索的关键词个数
由于实验的要求,需要统计一系列的字符串通过百度搜索得到的关键词个数,于是使用python写了一个相关的脚本. 在写这个脚本的过程中遇到了很多的问题,下面会一一道来. ps:我并没有系统地学习过pyth ...
- python爬取百度搜索结果ur汇总
写了两篇之后,我觉得关于爬虫,重点还是分析过程 分析些什么呢: 1)首先明确自己要爬取的目标 比如这次我们需要爬取的是使用百度搜索之后所有出来的url结果 2)分析手动进行的获取目标的过程,以便以程序 ...
- 关于python抓取google搜索结果的若干问题
关于python抓取google搜索结果的若干问题 前一段时间一直在研究如何用python抓取搜索引擎结果,在实现的过程中遇到了很多的问题,我把我遇到的问题都记录下来,希望以后遇到同样问题的童 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- selenium抓取动态网页数据
1.selenium抓取动态网页数据基础介绍 1.1 什么是AJAX AJAX(Asynchronouse JavaScript And XML:异步JavaScript和XML)通过在后台与服务器进 ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
随机推荐
- [Code] 变态之人键合一
目的也比较单纯,选一门语言,走向人键合一. 选了两本书作为操练场:<精通Python设计模式>.<Data Structure and Algorithm in Python> ...
- java数据结构——二叉树(BinaryTree)
前面我们已经学习了一些线性结构的数据结构和算法,接下来我们开始学习非线性结构的内容. 二叉树 前面显示增.删.查.遍历方法,完整代码在最后面. /** * 为什么我们要学习树结构. * 1.有序数组插 ...
- Spring Boot 2.x基础教程:使用Swagger2构建强大的API文档
随着前后端分离架构和微服务架构的流行,我们使用Spring Boot来构建RESTful API项目的场景越来越多.通常我们的一个RESTful API就有可能要服务于多个不同的开发人员或开发团队:I ...
- springboot WebMvcConfigurerAdapter替代
过时应用: @Configuration public class WebMvcConfig extends WebMvcConfigurerAdapter { @Override public vo ...
- Java8新特性——stream流
一.基本API初探 package java8.stream; import java.util.Arrays; import java.util.IntSummaryStatistics; impo ...
- Spring Boot认证:整合Jwt
背景 Jwt全称是:json web token.它将用户信息加密到token里,服务器不保存任何用户信息.服务器通过使用保存的密钥验证token的正确性,只要正确即通过验证. 优点 简洁: 可以通过 ...
- .Net Core 商城微服务项目系列(三):Ocelot网关接入Grafana监控
使用网关之后我们面临的一个问题就是监控,我们需要知道网关的实时状态,比如当前的请求吞吐量.请求耗费的时间.请求峰值甚至需要知道具体哪个服务的哪个方法花费了多少时间.网关作为请求的中转点是监控品牌的要塞 ...
- mybatis - 通用mapper
title: 玩转spring-boot-mybatis date: 2019-03-11 19:36:57 type: "mybatis" categories: mybatis ...
- springboot之本地缓存(guava与caffeine)
1. 场景描述 因项目要使用本地缓存,具体为啥不用redis等,就不讨论,记录下过程,希望能帮到需要的朋友. 2.解决方案 2.1 使用google的guava作为本地缓存 初步的想法是使用googl ...
- LitePal的聚合函数
传统的聚合函数用法 虽说是聚合函数,但它的用法其实和传统的查询还是差不多的,即仍然使用的是select语句.但是在select语句当中我们通常不会再去指定列名,而是将需要统计的列名传入到聚合函数当 ...