Python+Selenium - Web自动化测试(二):元素定位
前言
前面已经把环境搭建好了,现在开始使用 Selenium 中的 Webdriver 框架编写自动化代码脚本,我们常见的在浏览器中的操作都会有相对应的类方法,这些方法需要定位才能操作元素,不同网页的元素也不同,可以根据自己情况选择使用不同的类方法。下面开始学习元素定位;
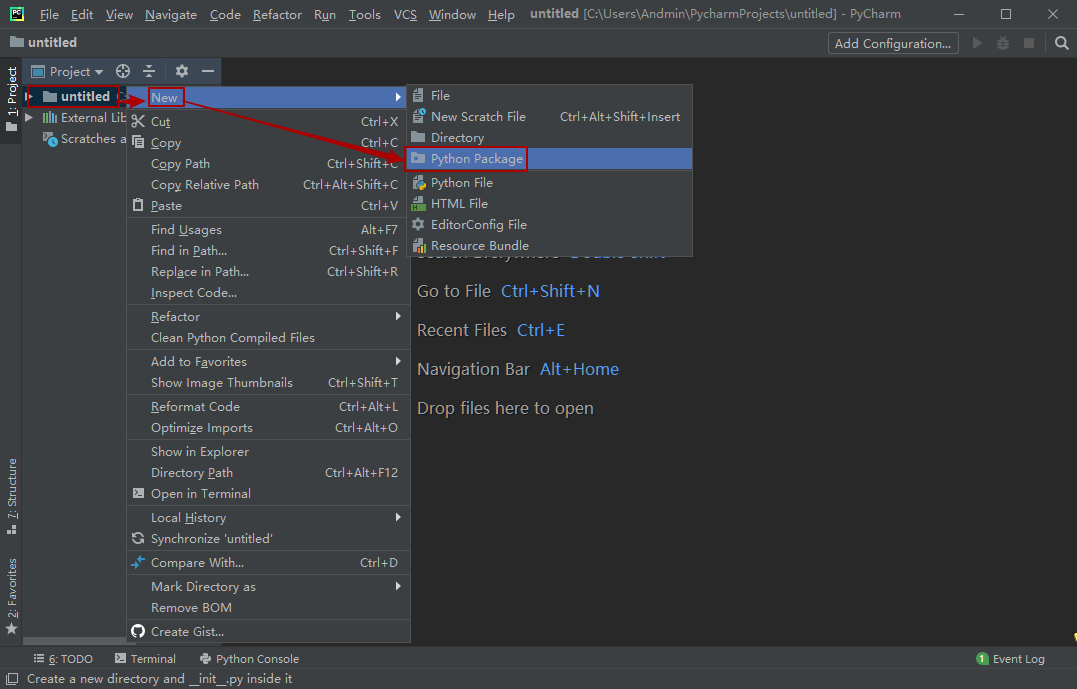
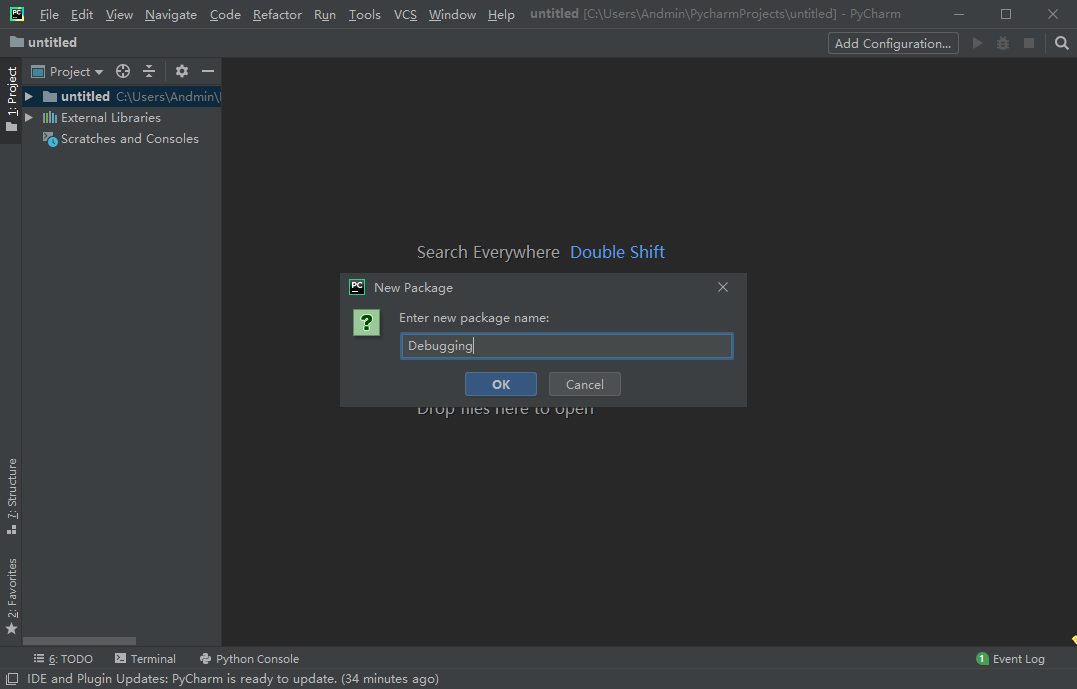
第一步在项目文件夹中创建一个Python包文件夹:
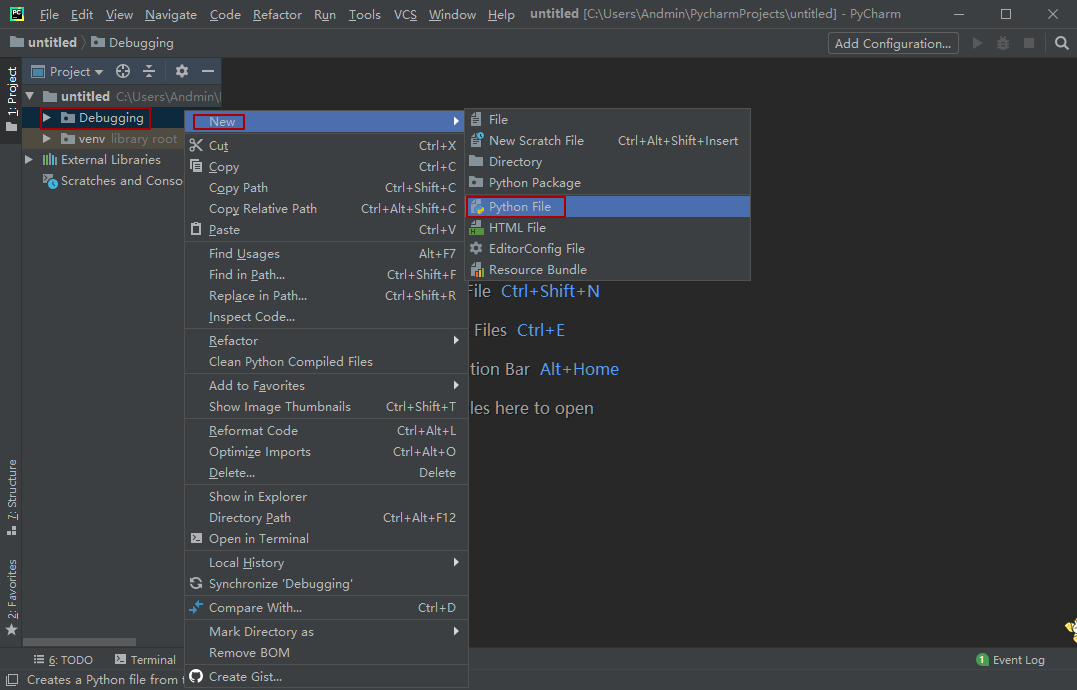
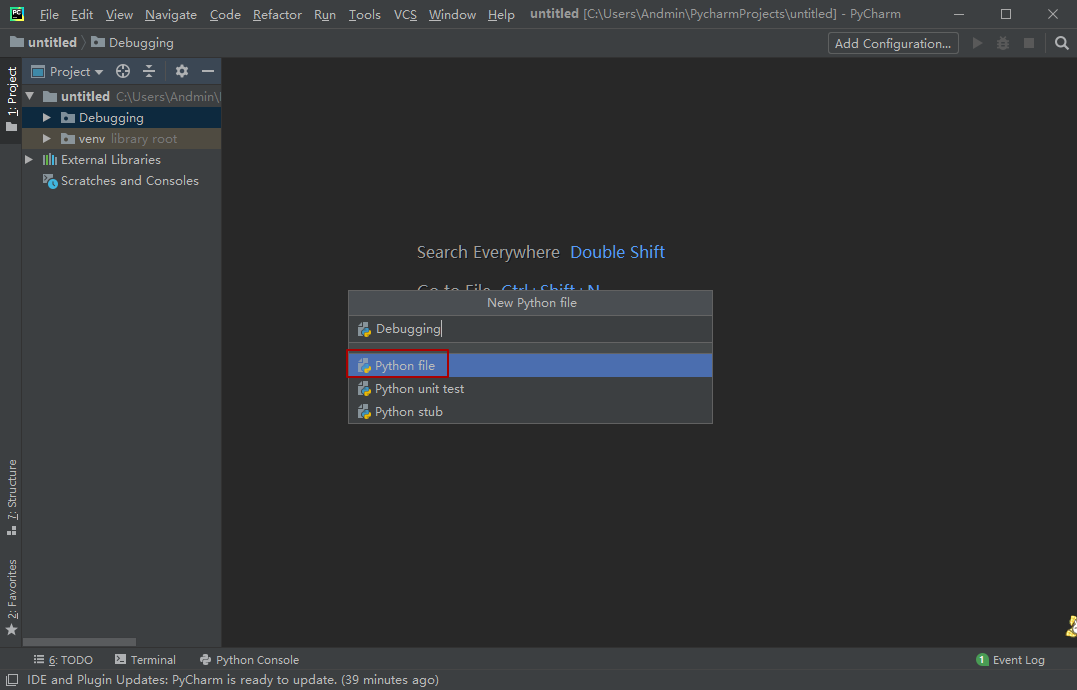
第二步New一个后缀为.py的Python文件写一段代码,先感受一下代码吧!写完以后Ctrl+Shift+F10运行代码:

# -*- coding:utf-8 –*-
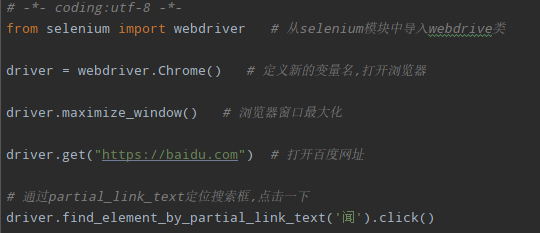
from selenium import webdriver # 从selenium模块中导入webdrive类 driver = webdriver.Chrome() # 定义新的变量名,打开浏览器 driver.maximize_window() # 浏览器窗口最大化 driver.get("https://baidu.com") # 打开百度网址 # 定位百度首页的搜索框,然后在搜索框中输入Selenium
driver.find_element_by_id('kw').send_keys('Selenium')
# 定位百度首页的百度一下,然后点击一下
driver.find_element_by_id('su').click()
浏览不同的网页元素也不同,可以选择使用最合适你的情况的方法使用,下面介绍Selenium其中的16种定位方法:
WebDriver8种基本元素定位方式:
id定位:find_element_by_id(self, id_)
name定位:find_element_by_name(self, name)
class定位:find_element_by_class_name(self, name)
tag定位:find_element_by_tag_name(self, name)
link定位:find_element_by_link_text(self, link_text)
partial_link定位:find_element_by_partial_link_text(self, link_text)
xpath定位:find_element_by_xpath(self, xpath)
css定位:find_element_by_css_selector(self, css_selector)
这8种其实和上面的8种一样的只不过后者是以复数形式出现(这些复数定位方法会返回一个列表的值):
id复数定位:find_elements_by_id(self, id_)
name复数定位:find_elements_by_name(self, name)
class复数定位:find_elements_by_class_name(self, name)
tag复数定位:find_elements_by_tag_name(self, name)
link复数定位:find_elements_by_link_text(self, text)
partial_link复数定位:find_elements_by_partial_link_text(self, link_text)
xpath复数定位:find_elements_by_xpath(self, xpath)
css复数定位:find_elements_by_css_selector(self, css_selector)
8种基本定位介绍,掌握这8种基本可以横着走了!
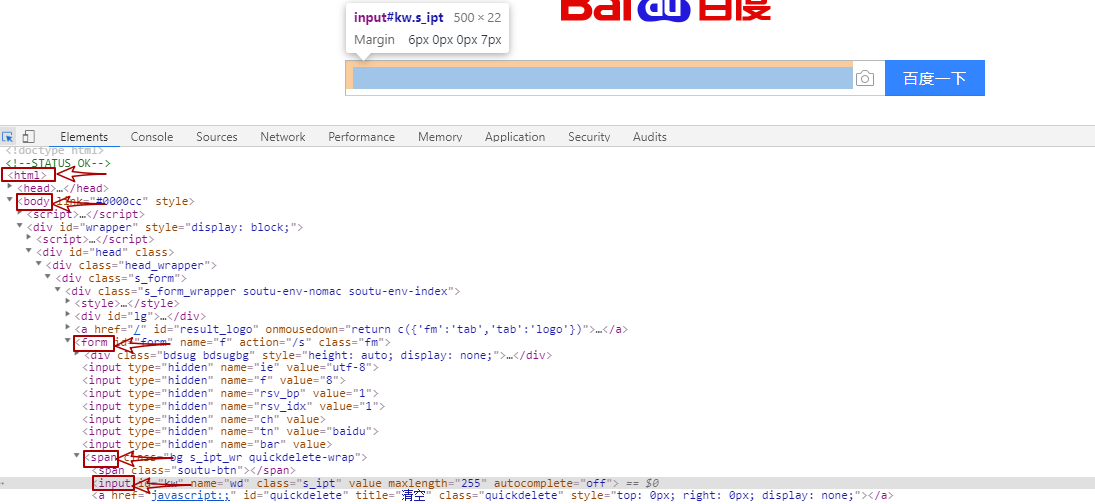
以百度为例这张图是百度输入框的,一眼看过去就看到了三种定位方式:
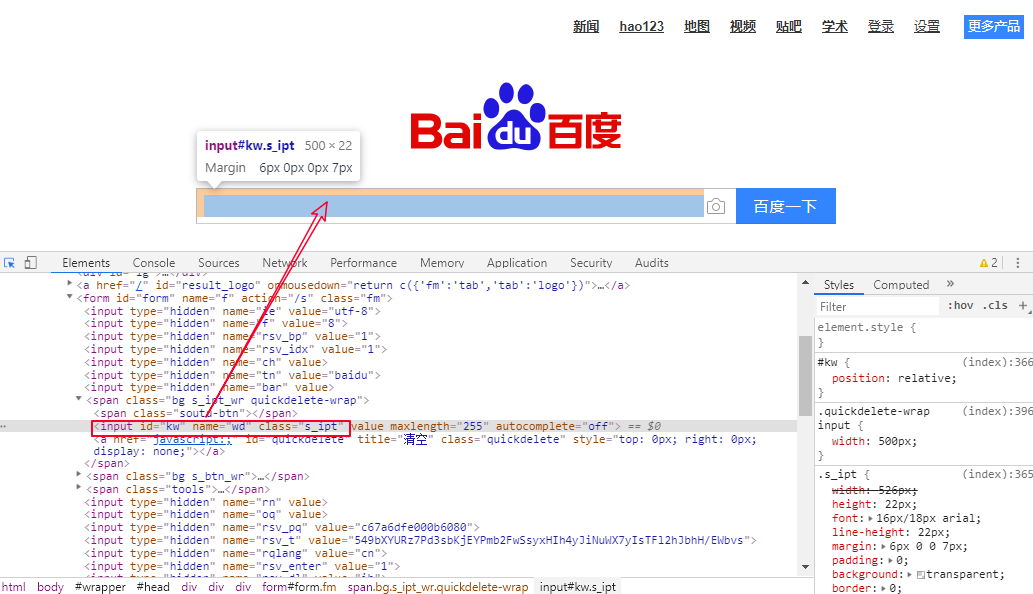
1. 通过id定位:

driver.find_element_by_id('kw').send_keys('Selenium')
2. 通过name定位:
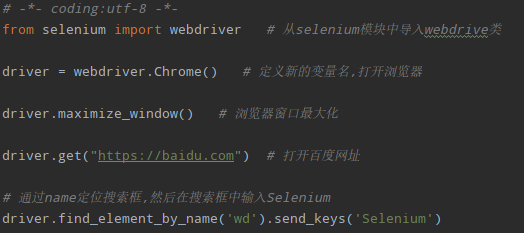
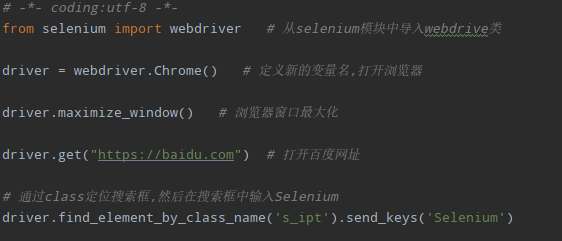
3. 通过class定位:
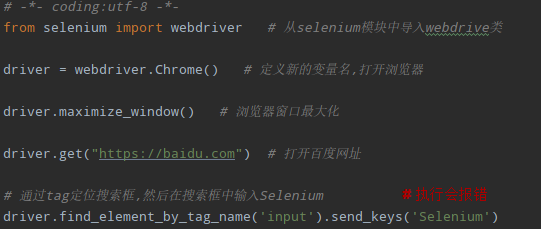
4. 通过tag定位:
tag其实是通过标签名去定位的,一般情况下一个页面会存在大量相同的标签名这种定位方式不是很实用,所以用的也就比较少;
5. 通过link_text定位:
HTML代码中以a标签开头的一般是超链接元素的标记可以使用link_text可以精准匹配;

6. 通过partial_link_text定位:
这种定位方式和上面的一样也是通过HTML的a标签定位,唯一不同的这种方式是模糊匹配,当超链接名称过长时,这时候可以使用模糊匹配方式,截取其中一部分字符串就可以了;
7. 通过xpath定位:
xpath是XML路径语言,它可以用来确定xml文档中的节点元素位置,通过元素的路径来完成对元素的查找。HTML就是XML的一种实现方式,可以自行选择绝对路径和相对路径作为匹配的路径
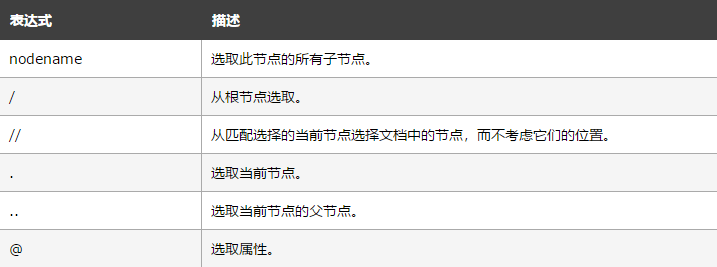
双斜杠(//) = 相对路径,可以选择任何一个节点作为起始点
单斜杆(/) = 绝对路径,就是从网页代码的html开始一层一层找
(*)= 匹配任何元素节点;(@*)= 匹配任何属性节点
xpath可以使用id,name,class元素进行定位:
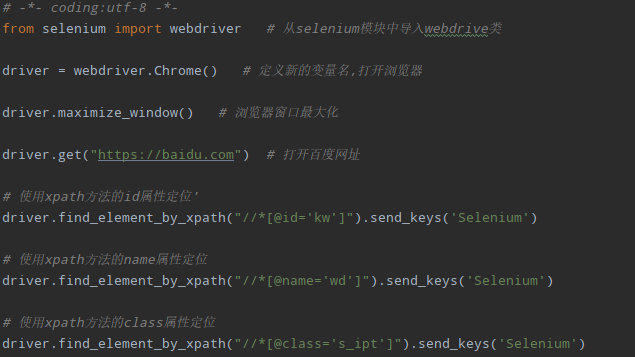
# 使用xpath方法的id属性定位
driver.find_element_by_xpath("//*[@id='kw']").send_keys('Selenium')# 使用xpath方法的name属性定位
driver.find_element_by_xpath("//*[@name='wd']").send_keys('Selenium')# 使用xpath方法的class属性定位
driver.find_element_by_xpath("//*[@class='s_ipt']").send_keys('Selenium')除了使用class,id,name定位,也可以手动选取节点来进行定位:
# 使用 // 选取当前节点
driver.find_element_by_xpath("//input[@id='kw']").send_keys('Selenium')# 使用 // 选取父节点
driver.find_element_by_xpath("//span[@class='bg s_ipt_wr quickdelete-wrap']/input").send_keys('Selenium')# 使用 // 选取爷节点
driver.find_element_by_xpath("//form[@id='form']/span[1]/input").send_keys('Selenium')使用绝对路径定位代码会很长,有其中一个元素发生变化就会失效。还有就是程序在运行的时候会检索会比较慢,剥丝抽茧一层层的找会很慢,不建议使用;

driver.find_element_by_xpath('html/body/div[1]/div[1]/div/div[1]/div/form/span[1]/input').send_keys('Selenium')
8. 通过css定位:
- css也颇为强大xpath可以干的事css也可以干,css的语法更为简洁,更为高效。而相对初学者xpath看起来更直观,更好理解;
( ps:css的写法相对有些特殊,需要对css有一定的了解才能理解写法 )
# 使用 css 通过 id 定位
driver.find_element_by_css_selector('#kw').send_keys('Selenium')# 使用 css 通过 class 定位
driver.find_element_by_css_selector('.s_ipt').send_keys('Selenium')# 使用 css 通过 name 定位
driver.find_element_by_css_selector("[name='wd']").send_keys('Selenium')# 使用 css 通过 autocomplete 定位
driver.find_element_by_css_selector("[autocomplete='off']").send_keys('Selenium') - css除了使用元素的属性定位也可以和xpath一样使用层级关系进行定位:
# 使用 css 通过 标签定位
driver.find_element_by_css_selector('input').send_keys('Selenium')
# 使用 css 标签属性定位
driver.find_element_by_css_selector('input.s_ipt').send_keys('Selenium')
driver.find_element_by_css_selector('input#kw').send_keys('Selenium')
## 层级关系
driver.find_element_by_css_selector("input[id='kw']").send_keys('Selenium')
driver.find_element_by_css_selector("input[name='wd']").send_keys('Selenium')
driver.find_element_by_css_selector("input[autocomplete='off']").send_keys('Selenium')
# 层级关系
driver.find_element_by_css_selector("form#form>span>input").send_keys('Selenium')
driver.find_element_by_css_selector("form.fm>span>input").send_keys('Selenium')
driver.find_element_by_css_selector("form[name='f']>span>input").send_keys('Selenium')
本章说的是8种基本定位的方法,学会了8种基本可以满足日常使用了,其中xpath和css的定位方法远远不止我写的几种,想要深入了解xpath、css、复数定位的请访问Selenium的官方网站浏览相关的说明文档或者自行上度娘查找学习。
"记录"是见证成长;"成长"则意味着蜕变;“变",创造无限可能。
Python+Selenium - Web自动化测试(二):元素定位的更多相关文章
- python + selenium相关事件和元素定位
女友由于工作上的失误,将公司RDM中的某一字段的2000条数据给删除了.....就算是重新添加字段,但是与其他数据的关联性已经不在了.由于每天的数据修改量大,有关部门不愿意恢复数据库,因此只能一条条的 ...
- web自动化测试(java)---元素定位
和python类似,java-selenium也提供了很多种元素定位的方法,具体如下: findElement(By.id()) findElement(By.name()) findElement( ...
- python selenium web自动化测试完整项目实例
问题: 好多想不到的地方,中间经历了一次重构,好蛋疼: xpath定位使用的不够熟练,好多定位问题,只能靠强制等待解决: 存在功能重复的方法,因为xpath定位不同,只能分开写,有时间可以继续优化: ...
- Python+Selenium - Web自动化测试(一):环境搭建
清单列表: Python 3x Selenium Chrome Pycharm 一.Python的安装: Python官网下载地址:https://www.python.org/ 1. 进入官网地址 ...
- python+selenium 环境搭建以及元素定位
在给公司同事给培训了WEB自动化框架,现在和大家分享交流下
- [小北De编程手记] : Lesson 03 - Selenium For C# 之 元素定位
无论哪一种自动化测试的驱动框架(基于B/S,桌面应用,还是手机App).都应当具有一套优秀的元素定位技术.通常的自动化测试流程也可以简单的归结为是一个从被测试程序中识别或是定位元素以及执行操作和验证元 ...
- Selenium webdriver 学习总结-元素定位
Selenium webdriver 学习总结-元素定位 webdriver提供了丰富的API,有多种定位策略:id,name,css选择器,xpath等,其中css选择器定位元素效率相比xpath要 ...
- 关于selenium的8种元素定位
selenium中有八种元素定位,分别是:id,name,class_name,tag_name,link_text.partial_link_text.xpath.css 简单的定位可以用 id.n ...
- Python+selenium学习(二) selenium 定位不到元素
转载:https://www.cnblogs.com/tarrying/p/9681991.html tarrying selenium的三种等待时间 //隐式等待(20秒以内没哥一段时间就会去找元素 ...
随机推荐
- CF1195C Basketball Exercise (dp + 贪心)
题解出处:https://www.luogu.org/problemnew/solution/CF1195C 很水的一道C题……目测难度在黄~绿左右.请各位切题者合理评分. 注意到可以选择的球员编号是 ...
- C# backgroundwork的使用方法
引言:在 WinForms 中,有时要执行耗时的操作,在该操作未完成之前操作用户界面,会导致用户界面停止响应.解决的方法就是新开一个线程,把耗时的操作放到线程中执行,这样就可以在用户界面上进行其它操作 ...
- 关于Spring的JDBC连接mysql(与传统jdbc比较)
Spring的jdbc与Hibernate,Mybatis相比较,功能不是特别强大,但是在小型项目中,也到还是比较灵活简单. 首先可以看看一下传统的jdbc是如何操作的呢 传统JDBC 首先呢先要创建 ...
- python的发展史
python的发展史 1989年,被称为龟叔的Guido在为ABC语言写插件时,产生了写一个简洁又实用的编程语言的想法,并开始着手编写.因为其喜欢Monty Python喜剧团,所以将其命名为pyth ...
- get解决乱码的方式
//自定义的解决乱码方式
- MYSQL 时间轴数据 获取同一天数据的前3条
创建表数据 CREATE TABLE `praise_info` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID', `pic_id` va ...
- 续集:白菜的内涵,更新nand分区为ubifs,替换overlay
在上一篇真千兆路由的极限之OPENWRT MAKE, 某品牌白菜价QCA9558/QCA9880/QCA8337N纯种组合OS搭建时记中附带了128M nand的空间图示,在ar71xx profil ...
- Java集合系列(一)List集合
List的几种实现的区别与联系 List主要有ArrayList.LinkedList与Vector几种实现. ArrayList底层数据结构是数组, 增删慢.查询快; 线程不安全, 效率高; 不可以 ...
- Spring条件注解@Conditional
@Conditional是Spring4新提供的注解,它的作用是根据某个条件创建特定的Bean,通过实现Condition接口,并重写matches接口来构造判断条件.总的来说,就是根据特定条件来控制 ...
- Go中的fmt几种输出的区别和格式化方式
在日常使用fmt包的过程中,各种眼花缭乱的print是否让你莫名的不知所措呢,更让你茫然的是各种格式化的占位符..简直就是噩梦.今天就让我们来征服格式化输出,做一个会输出的Goer. fmt.Prin ...