Oracle 查询(SELECT)语句(一)
Ø 简介
本文介绍 Oracle 中查询(SELECT)语句的使用,在 SQL 中 SELECT 语句是相对内容较多的,也是相对比较复杂一点的,所以这里拿出来单独学习。
首先,我们先来理一下思路,我们知道查询通常包含以下内容:
Ø 查询指定的表和列
Ø 根据指定的条件查询,即 WHERE 条件
Ø 查询数据去重,即 DISTINCT 子句
Ø 查询数据聚合,即 COUNT()、MAX()、MIN() 等
Ø 按条件输出,即 CASE WHEN THEN 子句
Ø 排序(ORDER BY)
Ø 分组(GROUP BY)与分组过滤(HAVING)
Ø 多表连接(INNER JOIN、LEFT JOIN 等)
Ø 子查询(SELECT 子查询、WHERE 子查询等)
Ø 其他
好了,既然知道了有这些查询功能,下面我们就一一突破,准备了以下内容:
1. 准备数据
2. SELECT 语法
3. 基本用法
4. WHERE 条件
5. 聚合查询
6. CASE WHEN THEN 子句
7. 排序
8. 分组与分组过滤
1. 准备数据
1) 创建表结构
CREATE TABLE JNUser (
UserId NUMBER(10) NOT NULL ,
Name VARCHAR2(8) NOT NULL ,
Sex NUMBER(3) NOT NULL , --性别(0 女,1 男,2 未知)
Age NUMBER(5) NOT NULL ,
Birthday DATE NOT NULL ,
City VARCHAR2(6) NOT NULL ,
IdNumber CHAR(18) NOT NULL ,
Salary FLOAT ,
Remarks VARCHAR2(4000) NOT NULL ,
PRIMARY KEY (UserId),
CONSTRAINT UQ_JNUser_IdNumber UNIQUE (IdNumber),
CONSTRAINT CK_JNUser_Sex CHECK (Sex >= 0 AND Sex <= 2)
);
CREATE TABLE JNOrder (
OrderId NUMBER(10) NOT NULL ,
UserId NUMBER(10) NOT NULL ,
OrderNo VARCHAR2(16) NOT NULL ,
TotalAmount FLOAT NOT NULL ,
OrderDate DATE NOT NULL ,
Remarks VARCHAR2(4000) ,
PRIMARY KEY (OrderId),
CONSTRAINT UQ_JNOrder_OrderNo UNIQUE (OrderNo)
);
2) 插入数据
INSERT ALL
--用户数据
INTO JNUser VALUES(1, '孙器璇', 2, 17, to_date('2002/11/18', 'yyyy/mm/dd'), '北京', '17730094858437637X', 10400, 'hello')
INTO JNUser VALUES(2, '周器璇', 0, 22, to_date('1966/05/12', 'yyyy/mm/dd'), '武汉', '534668342907162757', 15000, '用户2')
INTO JNUser VALUES(3, '张二娃', 1, 24, to_date('1967/01/24', 'yyyy/mm/dd'), '杭州', '36935324879542561X', 7600, '大家好,我是张二娃')
INTO JNUser VALUES(4, '陈悴', 2, 22, to_date('1984/10/11', 'yyyy/mm/dd'), '武汉', '585823614699788016', 7100, '你好,贵姓?')
INTO JNUser VALUES(5, '钱悴', 2, 58, to_date('1961/10/21', 'yyyy/mm/dd'), '深圳', '449489822531507067', 15320, 'hello 张二娃')
INTO JNUser VALUES(6, '张无忌', 1, 61, to_date('1988/02/24', 'yyyy/mm/dd'), '杭州', '385929993868497572', 17800, '哈啰,我是张无忌')
INTO JNUser VALUES(7, '张大彪', 1, 24, to_date('1995/05/16', 'yyyy/mm/dd'), '上海', '466484458398445233', 1200, '我说了,我是彪爷')
INTO JNUser VALUES(8, '冯小二', 1, 29, to_date('1976/09/28', 'yyyy/mm/dd'), '广州', '40016865591929392X', 5700, '客观,吃点莫子?')
INTO JNUser VALUES(9, 'DBA', 2, 32, to_date('1997/04/28', 'yyyy/mm/dd'), '上海', '488500420672587475', 16000, '小崽子们,你们好,我是 DBA')
INTO JNUser VALUES(10, '陈双', 0, 18, to_date('1995/02/07', 'yyyy/mm/dd'), '武汉', '942310204386191671', 10343, '我是双儿')
--订单数据
INTO JNOrder VALUES(1, 2, '58977924501badf7', 2620, to_date('2019/06/10', 'yyyy/mm/dd'), '又是双十一,我卖完再剁手啦')
INTO JNOrder VALUES(2, 3, '316626433f743978', 1115, to_date('2019/08/19', 'yyyy/mm/dd'), '其他没什么,就是想买')
INTO JNOrder VALUES(3, 4, '8698789361c78946', 1734, to_date('2019/03/16', 'yyyy/mm/dd'), '')
INTO JNOrder VALUES(4, 5, '58716471589e3df2', 897, to_date('2019/11/13', 'yyyy/mm/dd'), ' ')
INTO JNOrder VALUES(5, 8, '5583165337e0ee25', 2097, to_date('2019/01/21', 'yyyy/mm/dd'), '我已下单,快点发货,老板')
INTO JNOrder VALUES(6, 8, '395799340826d6f2', 304, to_date('2019/02/27', 'yyyy/mm/dd'), ' ')
INTO JNOrder VALUES(7, 3, '887799782996b3f1', 1246, to_date('2019/09/20', 'yyyy/mm/dd'), '老板,给我来个好看的包装盒,我要送老丈人')
INTO JNOrder VALUES(8, 8, '39482046468266d6', 306, to_date('2019/02/28', 'yyyy/mm/dd'), NULL)
SELECT * FROM DUAL;
COMMIT;
2. SELECT 语法
SELECT <列名1> [<,列名2>]… FROM <表名或视图名>
[WHERE <条件表达式>]
[GROUP BY <列名1> [HAVING <条件表达式>]
[ORDER BY <列名1> [ASC | DESC]]
说明:如果输出所有列,可以指定为"*"。这里简单阐述下(SELECT * 与 SELECT 所有列)的一些区别:
|
比较项 |
SELECT * |
SELECT 指明所有列 |
结论 |
|
1. 执行效率 |
需要检索表中的所有列名 |
不需要检索列名 |
后者效率略高 |
|
2. 后续新增字段 |
原程序会直接将新字段查出 |
需要重新更改程序中的 SQL 语句 |
视业务情况而定 |
|
3. 难易程度 |
比较便捷 |
比较麻烦 |
前者有优势 |
|
4. 字段较多时(比如一两百多个) |
减少网络流量 |
增加网络流量 |
前者有优势(可忽略的) |
提示:如有其他看法,欢迎讨论。
3. 基本语法
1) 查询所有列
SELECT * FROM JNUser;
SELECT * FROM JNOrder;
2) 查询指定列
SELECT UserId, Name FROM JNUser;
3) 定义别名
SELECT UserId 用户Id, Name 用户名, Age AS "性 别", U.City FROM JNUser U;
说明:
1. 表别名不能使用 AS 关键字;定义别名后可使用或不使用;
2. 列别名可使用或不使用 AS 关键字;别名包含特殊字符时,采用""双引号括起来。
4) 算数运算符(+、-、*、/)
SELECT Salary, Salary + 200, Salary - 200, Salary * 12, Salary / 30 FROM JNUser;
5) 比较运算符(>、>=、<、<=、=、!= | <>)
SELECT * FROM JNUser WHERE City <> '上海'; --或者使用 !=
6) 列连接
SELECT UserId || ' - ' || Name || ' - ' || City AS UserDesc FROM JNUser;
7) 构建表达式
SELECT ('SELECT * FROM ' || TABLE_NAME || ';') AS SEL FROM ALL_TABLES WHERE OWNER = 'USER01';
8) 数据去重
SELECT DISTINCT Age, City FROM JNUser;
说明:去除每列相同的数据行,只返回一行
4. WHERE 条件
1) 复合条件
SELECT * FROM JNUser WHERE Salary > 10000; --查出工资大于10000的用户
SELECT * FROM JNUser WHERE Sex = 0 AND Salary > 10000; --查出性别为女性,且工资大于10000的用户
SELECT * FROM JNUser WHERE (Sex = 0 OR Sex = 2) AND Salary > 10000; --查出性别为女性或者未知,且工资大于10000的用户
2) IN 子句
IN 子句表示取出值包含在给出的值范围内的记录。
SELECT * FROM JNUser WHERE City IN('武汉', '上海', '北京') ORDER BY City; --查出所在城市在武汉、上海、北京的用户,并按城市升序排序
3) BETWEEN 子句
BETWEEN 子句表示取出值在起始值与结束值之间的记录,且包含起始值与结束值(它是包头包围的)。
SELECT * FROM JNUser WHERE Salary BETWEEN 10400 AND 16000; --查出工资在10400(包含)至16000(包含)之间的用户
4) LIKE 模糊匹配
SELECT * FROM JNUser WHERE Remarks LIKE 'h%'; --查出备注以 h 开头的用户(注意:匹配时区分大小写)
SELECT * FROM JNUser WHERE Remarks LIKE '%好%'; --查出备注中包含“好”字的用户
SELECT * FROM JNUser WHERE Name LIKE '张__'; --查出姓张的,并且名为2个字的用户
注意:在实际应用场景中不到万不得已,尽量避免使用 LIKE 模糊查询,因为使用模糊的字段就不能使用索引了,影响查询效率。
5) 使用&变量
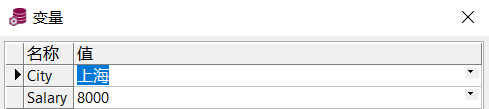
SELECT * FROM JNUser WHERE City = '&City' AND Salary > &Salary;
说明:该查询方式只适合在 PL/SQL Developer 中使用,提供一个条件参数占位符,用于在窗口中输入参数值。
5. 聚合查询
聚合函数是 Oracle 提供内置函数,用于计算某一列的聚合计算(如:数量、平均值等)
SELECT COUNT(*) AS COUNT FROM JNUser WHERE City = '上海'; --统计有多少上海用户,*可以改为数字1
SELECT MAX(SALARY) AS MAX FROM JNUser WHERE City = '上海'; --查询上海用户最高薪资
SELECT MIN(SALARY) AS MIN FROM JNUser WHERE City = '上海'; --查询上海用户最低薪资
SELECT SUM(SALARY) AS SUM FROM JNUser WHERE City = '上海'; --查询上海用户总薪资
SELECT AVG(SALARY) AS AVG FROM JNUser WHERE City = '上海'; --查询上海用户平均薪资
6. CASE WHEN THEN 子句
CASE WHEN THEN 定义在 SELECT 与 FROM 之间,用于判断当条件符合 WHEN 时,就返回 THEN 对应的值,否则返回 ELSE 中的值。
1) 第一种写法
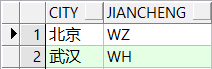
SELECT City, (CASE City WHEN '上海' THEN 'SH' WHEN '武汉' THEN 'WH' ELSE 'WZ' END) AS JianCheng FROM JNUser;
2) 第二种写法
SELECT City, (CASE WHEN City = '上海' THEN 'SH' WHEN City = '武汉' THEN 'WH' ELSE 'WZ' END) AS JianCheng FROM JNUser;
7. 排序
排序采用 ORDER BY 子句,包含升序(ASC)和降序(DESC)排序方式。
SELECT * FROM JNUser ORDER BY Salary; --ASC 升序排序(默认排序方式)
SELECT * FROM JNUser ORDER BY Salary DESC; --DESC 降序排序
SELECT * FROM JNUser ORDER BY Sex ASC, Salary DESC; --首先按性别升序排序,再按薪资降序排序

SELECT * FROM JNUser WHERE Sex = 1 ORDER BY 4 ASC; --查出男性用户所有用户,并按照第4列(AGE)升序排序
8. 分组与分组过滤
分组采用 GROUP BY 子句,注意:包含分组的 SELECT 输出列中只能包含,分组的列和聚合计算的列。GRUOUP BY 分组后还可以跟条件子句,即 HAVING,通常用于聚合计算过滤。
1) 查出工资大于8000的用户,每个性别各占的数量,并按性别倒序排序
SELECT Sex, COUNT(1) AS Count FROM JNUser
WHERE Salary > 8000
GROUP BY Sex
ORDER BY Sex DESC;
2) 查出工资大于8000的用户,每个性别的平均工资大于13000,并按性别倒序排序
SELECT Sex, AVG(Salary) AS Avg FROM JNUser
WHERE Salary > 8000
GROUP BY Sex
HAVING AVG(Salary) > 13000
ORDER BY Sex DESC;
Oracle 查询(SELECT)语句(一)的更多相关文章
- Microsoft SqlServer2008技术内幕:T-Sql语言基础-读书笔记-单表查询SELECT语句元素
1.select语句逻辑处理顺序: FORM WHERE GROUP BY HAVING SELECT OVER DISTINCT TOP ORDER BY 总结: 2.FORM子句的表名称应该带上数 ...
- mysql 查询select语句汇总
数据准备: 创建表: create table students( id int unsigned primary key auto_increment not null, name varchar( ...
- Oracle中Select语句完整的执行顺序
oracle Select语句完整的执行顺序: .from 子句组装来自不同数据源的数据: .where 子句基于指定的条件对记录行进行筛选: .group by子句将数据划分为多个分组: .使用聚集 ...
- 基于SQL和PYTHON的数据库数据查询select语句
#xiaodeng#python3#基于SQL和PYTHON的数据库数据查询语句import pymysql #1.基本用法cur.execute("select * from biao&q ...
- SQL_2_查询Select语句的使用
查询一词在SQL中并不是很恰当,在SQL中查询除了向数据库提出问题之外,还可以实现下面的功能: 1>建立或删除一个表 2>插入.修改.或删除一个行或列 3>用一个特定的命令从几个表中 ...
- oracle查询字符集语句
(1)查看字符集(三条都是等价的) 复制代码 代码如下: select * from v$nls_parameters where parameter='NLS_CHARACTERSET'sel ...
- oracle查询相关语句
1,查询表空间使用情况select a.a1 表空间名称,c.c2 类型,c.c3 区管理,b.b2/1024/1024 表空间大小M,(b.b2-a.a2)/1024/1024 已使用M,subst ...
- Oracle数据库select语句
select * from EMp--all data in EMP table select * from EMP where ename in('SMITH')--the data where e ...
- Oracle下select语句
先看scott下自带的emp表 empno:编号 ename:名字 Job:职位 mgr:上级编号 hiredate:入职时间 sal:薪水 comm:奖金 deptno:部门编号 部门表dep ...
随机推荐
- 在 ASP.NET Core 中使用 ApplicationPart 的简单示例
1. 项目截图: 2. 代码 <Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <TargetFra ...
- Docker - 快速入门(一)
概念 下面这三个概念一开始可能不好理解,等大家跟着博客把例子做完了,再回头来看应该就能理解了. docker image # docker镜像 镜像就是一个只读的模板.镜像可以用来创建Docker容 ...
- node.js的async和await
一.async和await是什么 ES2017 标准引入了 async 函数,使得异步操作变得更加方便,async其实本质是Generator函数的语法糖 async表示函数里有异步操作 await表 ...
- java基础(11):接口、多态
1. 接口 1.1 接口概念 接口是功能的集合,同样可看做是一种数据类型,是比抽象类更为抽象的”类”. 接口只描述所应该具备的方法,并没有具体实现,具体的实现由接口的实现类(相当于接口的子类)来完成. ...
- python基础(5):格式化输出、基本运算符、编码问题
1. 格式化输出 现在有以下需求,让⽤户输入name, age, job,hobby 然后输出如下所⽰: ------------ info of Alex Li ----------- Name : ...
- RandomAccessFile实现简易记事本工具操作
package seday03; import java.io.IOException; import java.io.RandomAccessFile; import java.util.Scann ...
- Linux网络——修改配置文件
Linux网络——修改配置文件 摘要:本文主要学习了如何通过修改配置文件来设置网络参数. 配置文件 通过修改系统的配置文件为系统设置网络参数,这种方式的优点是可以永久保存,计算机重启后仍然生效.缺点是 ...
- MD5哈希算法及其原理
- MD5功能 MD5算法对任意长度的消息输入,产生一个128位(16字节)的哈希结构输出.在处理过程中,以512位输入数据块为单位. - MD5用途及特征 MD5通常应用在以下场景: 1.防篡改,保 ...
- 【LeetCode】198. 打家劫舍
打家劫舍 你是一个专业的小偷,计划偷窃沿街的房屋.每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警. 给定 ...
- Mysql—数据类型详解
在MySQL中常用数据类型主要分为以下几类:数值类型.字符串类型.日期时间类型. 数值类型 字符串类型 日期时间类型 数据类型 字节数 取值范围 格式 备注 year 1 1901~2 ...