Pandas 分组聚合
# 导入相关库
import numpy as np
import pandas as pd
创建数据
index = pd.Index(data=["Tom", "Bob", "Mary", "James", "Andy", "Alice"], name="name")
data = {
"age": [18, 30, 35, 18, np.nan, 30],
"city": ["Bei Jing ", "Shang Hai ", "Guang Zhou", "Shen Zhen", np.nan, " "],
"sex": ["male", "male", "female", "male", np.nan, "female"],
"income": [3000, 8000, 8000, 4000, 6000, 7000]
}
user_info = pd.DataFrame(data=data, index=index)
user_info
"""
age city sex income
name
Tom 18.0 Bei Jing male 3000
Bob 30.0 Shang Hai male 8000
Mary 35.0 Guang Zhou female 8000
James 18.0 Shen Zhen male 4000
Andy NaN NaN NaN 6000
Alice 30.0 female 7000
"""
.groupby()拆分数据
该方法提供的是分组聚合步骤中的拆分功能,能根据索引或字段对数据进行分组
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
参数解释:
- by:接收list,string,mapping或generator。用于确定进行分组的依据。无默认
- axis:接收int。表示操作的轴向,默认对列进行操作。默认为0
- level:接收int或者索引名。代表标签所在级别。默认为None
- as_index:接收boolearn。表示聚合后的聚合标签是否以DataFrame索引形式输出。默认为True
- sort:接收boolearn。表示是否对分组依据分组标签进行排序。默认为True
- group_keys:接收boolearn。表示是否显示分组标签的名称。默认为True
- squeeze:接收boolearn。表示是否在允许的情况下对返回数据进行降维。默认为False
by参数说明
- 如果传入的是一个函数则对索引进行计算并分组。
- 如果传入的是一个字典或者Series则字典或者Series的值用来做分组依据。
- 如果传入一个NumPy数组则数据的元素作为分组依据。
- 如果传入的是字符串或者字符串列表则使用这些字符串所代表的字段作为分组依据。
常用的描述性统计方法
用groupby方法分组后的结果并不能直接查看,而是被存在内存中,输出的是内存地址。实际上分组后的数据对象GroupBy类似Series与DataFrame,是pandas提供的一种对象。GroupBy对象常用的描述性统计方法如下
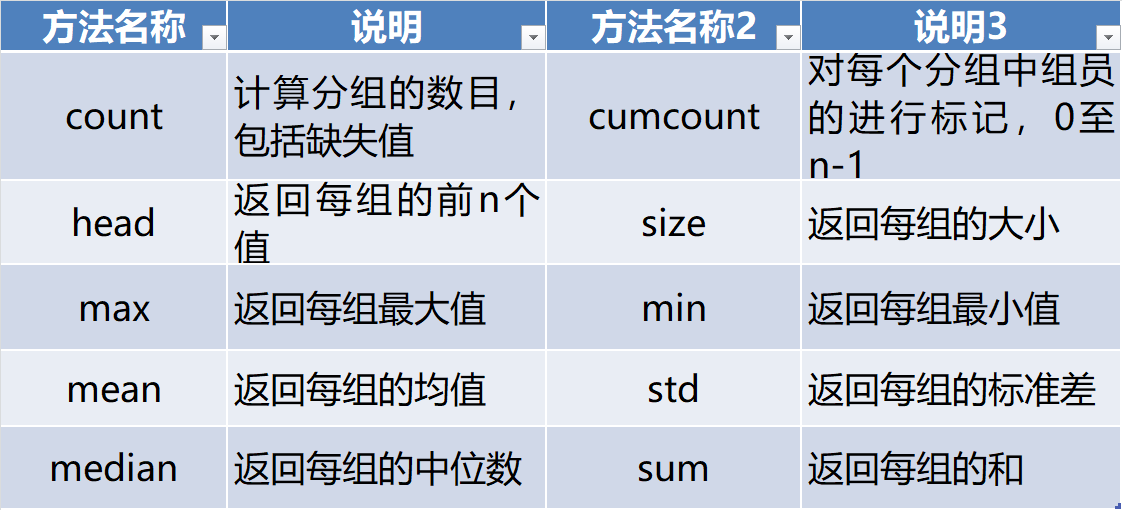
# 根据性别分组,计算收入列各组的平均值
hh = user_info[['sex','income']].groupby('sex')
hh.mean()

将对象分割成组
在进行分组统计前,首先要做的就是进行分组
# 依据性别来分组
grouped = user_info.groupby(user_info["sex"])
grouped.groups # 更简洁的方式:
# 依据性别来分组
user_info.groupby("sex").groups
# 先按照性别来分组,再按照年龄进一步分组
user_info.groupby(["sex", "age"]).groups
关闭排序
默认情况下,groupby 会在操作过程中对数据进行排序。如果为了更好的性能,可以设置 sort=False
grouped = user_info.groupby(["sex"], sort=False)
grouped.groups
选择列
在使用 groupby 进行分组后,可以使用切片 [] 操作来完成对某一列的选择
grouped = user_info.groupby("sex")
grouped
遍历分组
在对数据进行分组后,可以进行遍历
单个字段分组遍历
grouped = user_info.groupby("sex")
for name, group in grouped:
print("name: {}".format(name))
print("group: {}".format(group))
print("--------------")
"""
name: female
group: age city sex income
name
Mary 35.0 Guang Zhou female 8000
Alice 30.0 female 7000
--------------
name: male
group: age city sex income
name
Tom 18.0 Bei Jing male 3000
Bob 30.0 Shang Hai male 8000
James 18.0 Shen Zhen male 4000
"""
多个字段分组遍历
grouped = user_info.groupby(["sex", "age"])
for name, group in grouped:
print("name: {}".format(name))
print("group: {}".format(group))
print("--------------") """
name: ('female', 30.0)
group: age city sex income
name
Alice 30.0 female 7000
--------------
name: ('female', 35.0)
group: age city sex income
name
Mary 35.0 Guang Zhou female 8000
--------------
name: ('male', 18.0)
group: age city sex income
name
Tom 18.0 Bei Jing male 3000
James 18.0 Shen Zhen male 4000
--------------
name: ('male', 30.0)
group: age city sex income
name
Bob 30.0 Shang Hai male 8000
"""
选择一个组
.get_group ()
分组后,我们可以通过 get_group 方法来选择其中的某一个组
grouped = user_info.groupby("sex")
grouped.get_group("male")
user_info.groupby(["sex", "age"]).get_group(("male", 18))
聚合
分组的目的是为了统计,统计的时候需要聚合,所以我们需要在分完组后来看下如何进行聚合。常见的一些聚合操作有:计数、求和、最大值、最小值、平均值等。得到的结果是
一个以分组名作为索引的结果对象。
想要实现聚合操作,一种方式就是调用 agg 方法。
.agg()
DataFrame.agg(func, axis=0, *args, **kwargs)
参数解释:
- func:接收list、dict、function。表示应用于每行/每列的函数。无默认
- axis:接收0或1。代表操作的轴向。默认为0
# 获取不同性别下所包含的人数
grouped = user_info.groupby("sex")
grouped["age"].agg(len)
# 获取不同性别下包含的最大的年龄
grouped = user_info.groupby("sex")
grouped["age"].agg(np.max)
如果是根据多个键来进行聚合,默认情况下得到的结果是一个多层索引结构
grouped = user_info.groupby(["sex", "age"])
rs = grouped.agg(len)
rs
"""
city income
sex age
female 30.0 1 1
35.0 1 1
male 18.0 2 2
30.0 1 1
避免出现多层索引
.reset_index()
对包含多层索引的对象调用 reset_index 方法
rs.reset_index()
参数 as_index=False
在分组时,设置参数 as_index=False
grouped = user_info.groupby(["sex", "age"], as_index=False)
grouped["income"].agg(max)
.describe()查看数据情况
Series 和 DataFrame 都包含了 describe 方法,我们分组后一样可以使用 describe 方法来查看数据的情况。
grouped = user_info.groupby("sex")
grouped.describe().reset_index()
一次应用多个聚合操作
得到多个统计结果
有时候进行分组后,不单单想得到一个统计结果,有可能是多个
# 统计出不同性别下的收入的总和和平均值
grouped = user_info.groupby("sex")
grouped["income"].agg([np.sum, np.mean]).reset_index()
统计结果重命名
如果想将统计结果进行重命名,可以传入字典
grouped = user_info.groupby("sex")
grouped["income"].agg([np.sum, np.mean]).rename(columns={"sum": "income_sum", "mean": " income_mean"})
对 DataFrame 列应用不同的聚合操作
有时候可能需要对不同的列使用不同的聚合操作
# 统计不同性别下人群的年龄的均值以及收入的总和
grouped.agg({"age": np.mean, "income": np.sum}).rename(columns={"age": "age_mean", "income": "income_sum"}).reset_index()
transform 操作
前面进行聚合运算的时候,得到的结果是一个以分组名作为索引的结果对象。虽然可以指定 as_index=False ,但是得到的索引也并不是元数据的索引。如果我们想使用原数组的索引的话, 就需要进行 merge 转换
transform 方法简化了这个过程,它会把 func 参数应用到所有分组,然后把结果放置到原数组的 索引上(如果结果是一个标量,就进行广播)
# 通过 agg 得到的结果的索引是分组名
grouped = user_info.groupby("sex")
grouped["income"].agg(np.mean) # 通过 transform 得到的结果的索引是原始索引,它会将得到的结果自动关联上原始的索引 grouped = user_info.groupby("sex")
grouped["income"].transform(np.mean)
可以看到,通过 transform 操作得到的结果的长度与原来保持一致
apply 操作
apply 会将待处理的对象拆分成多个片段,然后对各片段调用传入的函数,最后尝试用pd.concat() 把结果组合起来。func 的返回值可以是 Pandas 对象或标量,并且数组对象的大小不限。
# 使用 apply 来完成上面的聚合
grouped = user_info.groupby("sex")
grouped["income"].apply(np.mean) # 统计不同性别最高收入的前 n 个值
def f1(ser, num=2):
return ser.nlargest(num).tolist()
grouped["income"].apply(f1) # 获取不同性别下的年龄的均值
def f2(df):
return df["age"].mean()
grouped.apply(f2)
Pandas 分组聚合的更多相关文章
- Python Pandas分组聚合
Pycharm 鼠标移动到函数上,CTRL+Q可以快速查看文档,CTR+P可以看基本的参数. apply(),applymap()和map() apply()和applymap()是DataFrame ...
- Pandas 分组聚合 :分组、分组对象操作
1.概述 1.1 group语法 df.groupby(self, by=None, axis=0, level=None, as_index: bool=True, sort: bool=True, ...
- pandas分组聚合案例
美国2012年总统候选人政治献金数据分析 导入包 import numpy as np import pandas as pd from pandas import Series,DataFrame ...
- DataAnalysis-Pandas分组聚合
title: Pandas分组聚合 tags: 数据分析 python categories: DataAnalysis toc: true date: 2020-02-10 16:28:49 Des ...
- pandas分组和聚合
Pandas分组与聚合 分组 (groupby) 对数据集进行分组,然后对每组进行统计分析 SQL能够对数据进行过滤,分组聚合 pandas能利用groupby进行更加复杂的分组运算 分组运算过程:s ...
- Pandas分组运算(groupby)修炼
Pandas分组运算(groupby)修炼 Pandas的groupby()功能很强大,用好了可以方便的解决很多问题,在数据处理以及日常工作中经常能施展拳脚. 今天,我们一起来领略下groupby() ...
- Atitit 数据存储的分组聚合 groupby的实现attilax总结
Atitit 数据存储的分组聚合 groupby的实现attilax总结 1. 聚合操作1 1.1. a.标量聚合 流聚合1 1.2. b.哈希聚合2 1.3. 所有的最优计划的选择都是基于现有统计 ...
- ORACLE字符串分组聚合函数(字符串连接聚合函数)
ORACLE字符串连接分组串聚函数 wmsys.wm_concat SQL代码: select grp, wmsys.wm_concat(str) grp, 'a1' str from dual un ...
- SSRS 系列 - 使用带参数的 MDX 查询实现一个分组聚合功能的报表
SSRS 系列 - 使用带参数的 MDX 查询实现一个分组聚合功能的报表 SSRS 系列 - 使用带参数的 MDX 查询实现一个分组聚合功能的报表 2013-10-09 23:09 by BI Wor ...
随机推荐
- Docker 为非root用户授权
Docker 为非root用户授权: 当运行docker pull busybox时候,会提示sky用户无法调用docker. 那么应该把sky用户加入docker用户组,不过在添加的时候,又提示了如 ...
- Java 学习笔记之 线程安全
线程安全: 线程安全的方法一定是排队运行的. public class SyncObject { synchronized public void methodA() { try { System.o ...
- link 和 @import 的区别是什么?
link语法结构: <link href="url" rel="stylesheet" type="text/css"> @im ...
- 二次函数,为什么a>0就可以知道开口向上.
最近自考. 学习高等数学. 学习高等数学过程中发现高中数学不会,,于是乎开始补高中数学. 学习高中数学过程中又发现初中数学有的不会,,于是乎开始补初中数学.. 可怕(→_→). 今天遇到一个二次函数, ...
- 05-04 scikit-learn库之主成分分析
目录 scikit-learn库之主成分分析 一.PCA 1.1 使用场景 1.2 代码 1.3 参数 1.4 属性 1.5 方法 二.KernelPCA 三.IncrementalPCA 四.Spa ...
- jsonp与cors跨域解析
1.浏览器的同源安全策略 没错,就是这家伙干的,浏览器只允许请求当前域的资源,而对其他域的资源表示不信任.那怎么才算跨域呢? 请求协议http,https的不同 域domain的不同 端口port的不 ...
- Python3程序设计指南:01 过程型程序设计快速入门
大家好,从本文开始将逐渐更新Python教程指南系列,为什么叫指南呢?因为本系列是参考<Python3程序设计指南>,也是作者的学习笔记,希望与读者共同学习. .py文件中的每个估计都是顺 ...
- Python 3.8.0 正式版发布,新特性初体验
北京时间 10 月 15 日,Python 官方发布了 3.8.0 正式版,该版本较 3.7 版本再次带来了多个非常实用的新特性. 赋值表达式 PEP 572: Assignment Expressi ...
- nm 命令能够显示目标文件中重载函数的名字改变(C++)
#include <stdio.h> #include <iostream> using std::cout; using std::endl; //这里的两个不同的add函数 ...
- python2与3实际中遇到的区别
1.type(1/2) python2是向下取整,0,为int:python3是正常除法,0.5,为float 2.