为什么使用B+Tree索引?
什么是索引?
索引是一种数据结构,具体表现在查找算法上。
索引目的
提高查询效率
【类比字典和借书】
如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的。
去图书馆借书也是一样,如果你要借某一本书,一定是先找到对应的分类科目,再找到对应的编号,这是生活中活生生的例子,通用索引,可以加快查询速度,快速定位。
数据结构——树
树
二叉树
每个节点最多含有两个子树的树称为二叉树。
二叉查找树ADT Tree
左子树的键值小于根的键值,右子树的键值大于根的键值。
平衡二叉树AVL Tree
在符合二叉查找树的条件下,还满足任何节点的两个子树的高度最大差为1。
BTree
BTree也称为平衡多路查找树
B-Tree是为磁盘等外存储设备设计的一种平衡查找树。
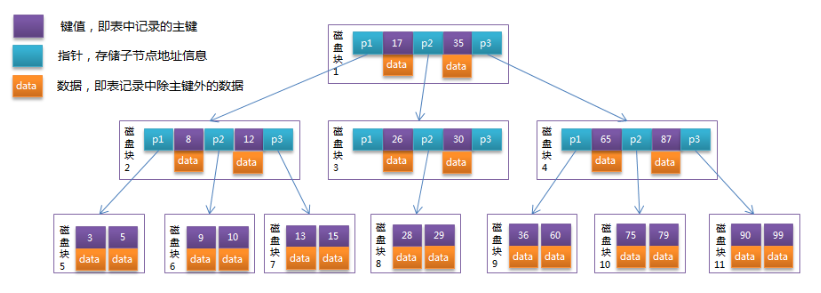
B+Tree
B+Tree是在B-Tree基础上的一种优化
- 非叶子结点只存储键值信息,不存储数据
- 所有的叶子结点都有一个链指针
- 数据记录都存放在叶子结点中
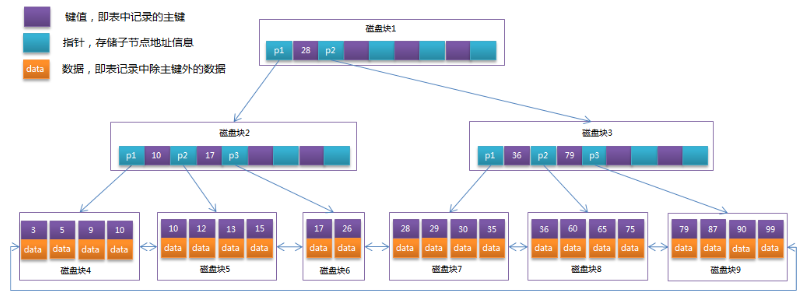
MySQL默认使用B+Tree索引
索引本身也很大,所以存储在磁盘中,需要加载到内存中执行。
故:索引结构优劣标准:磁盘I/O次数
BTree是为了充分利用磁盘预读功能而创建出来的一种数据结构。
局部性原理和磁盘预读
局部性原理:当一个数据被用到,其附近的数据很可能会马上用到
磁盘预读:由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入主存。
为什么平衡二叉树无法利用磁盘预读功能而BTree可以?
平衡二叉树也称为红黑数,在逻辑上是平衡二叉树,但是在物理存储上使用的是数组,逻辑上相近的节点可能在物理上相差很远。
BTree如何利用磁盘预读功能?
将节点大小设为等于一个页,BTree新建节点时,也是按照页为单位申请,同时计算机存储分配也是按页对齐,那么一个节点只需一次IO就可以读取全部节点数据。
【如果节点大小和BTree大小不对齐,那么同一页节点可能需要两次IO读取】
综上所述,用B-Tree作为索引结构效率是非常高的。
为什么B+Tree比BTree更适合作为索引结构?
BTree解决了磁盘IO的问题但没有解决元素遍历复杂的问题。
B+Tree的叶子节点用链指针相连,极大提高区间访问速度。【比如查询50到100的记录,查出50后,顺着指针遍历即可】
为什么使用B+Tree索引?的更多相关文章
- 论 数据库 B Tree 索引 在 固态硬盘 上 的 离散存储
传统的做法 , 数据库 的 B Tree 索引 在 磁盘上是 顺序存储 的 , 这是考虑到 磁盘 机械读写 的 特性 . 实际上 , B Tree 是一个 树形结构 , 可以采用 链式 存储 , 就是 ...
- Mysql的B+ Tree索引
为什么要使用索引? 最简单的方式实现数据查询:全表扫描,即将整张表的数据全部或者分批次加载进内存,由于存储的最小单位是块或者页,它们是由多行数据组成,然后逐块逐块或者逐页逐页地查找,这样查找的速度非常 ...
- MYSQL之B+TREE索引原理
1.什么是索引? 索引:加速查询的数据结构. 2.索引常见数据结构 顺序查找: 最基本的查询算法-复杂度O(n),大数据量此算法效率糟糕. 二叉树查找:(binary tree search): O( ...
- MYSQL的B+Tree索引树高度如何计算
前一段被问到一个平时没有关注到有关于MYSQL索引相关的问题点,被问到一个表有3000万记录,假如有一列占8位字节的字段,根据这一列建索引的话索引树的高度是多少? 这一问当时就被问蒙了,平时这也只关注 ...
- mysql--->B+tree索引的设计原理
1.什么是数据库的索引 每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不 ...
- Mysql B-Tree和B+Tree索引
Mysql B-Tree和B+树索引 Mysql加快数据查找使用B-Tree数据结构存储索引数据,InnoDB存储引擎实际使用B+Tree.下面首先介绍下B-Tree和B+Tree的区别: 一.B树和 ...
- Oracle复合B*tree索引branch block内是否包含非先导列键值?
好久不碰数据库底层细节的东西,前几天,一个小家伙跑来找我,非要说复合b*tree index branch block中只包含先导列键值信息,并不包含非先导列键值信息,而且还dump了branch b ...
- mysql B+Tree索引
原文地址:http://blog.codinglabs.org/articles/theory-of-mysql-index.html 数据结构及算法基础 索引的本质 MySQL官方对索引的定义为:索 ...
- C# 链表 二叉树 平衡二叉树 红黑树 B-Tree B+Tree 索引实现
链表=>二叉树=>平衡二叉树=>红黑树=>B-Tree=>B+Tree 1.链表 链表结构是由许多节点构成的,每个节点都包含两部分: 数据部分:保存该节点的实际数据. 地 ...
随机推荐
- 以阿里IoT开发物联网和应用平台
1. 链接物联网的概念 物联网(The Internet of Things,简称IOT)是指通过 各种信息传感器.射频识别技术.全球定位系统.红外感应器.激光扫描器等各种装置与技术,实时采集任何需要 ...
- LoRaWAN_stack移植笔记 (二)_GPIO
stm32相关的配置 由于例程使用的主控芯片为STM32L151C8T6,而在本设计中使用的主控芯片为STM32L051C8T6,内核不一样,并且Cube库相关的函数接口及配置也会有不同,所以芯片的驱 ...
- go语言实现分布式对象存储系统之单体对象存储
对象存储 基本概念 主流存储类型分为三种:块存储.文件存储以及对象存储 NAS(文件存储):Network Attached storage,提供了存储功能和文件系统的网络服务器,客户端可以访问NAS ...
- Nginx介绍与反向代理
Nginx的产生 没有听过Nginx?那么一定听过它的"同行"Apache吧!Nginx同Apache一样都是一种WEB服务器.基于REST架构风格,以统一资源描述符(Unifor ...
- Java IO体系之RandomAccessFile浅析
Java IO体系之RandomAccessFile浅析 一.RandomAccessFile综述: 1.1RandomAccessFile简介 RandomAccessFile是java Io体系中 ...
- 通过sql命令建表 和 主外键约束以及其他约束
create table命令 create table dept ( dept_id int primary key, dept_name ) not null, dept_address ) ) c ...
- softRestTemplate 2
@SuppressWarnings("unchecked") public User getUser(String id,String name) { Soft ...
- PyTorch : torch.nn.xxx 和 torch.nn.functional.xxx
PyTorch : torch.nn.xxx 和 torch.nn.functional.xxx 在写 PyTorch 代码时,我们会发现一些功能重复的操作,比如卷积.激活.池化等操作.这些操作分别可 ...
- POJ 3164 Command Network 最小树形图 朱刘算法
=============== 分割线之下摘自Sasuke_SCUT的blog============= 最 小树形图,就是给有向带权图中指定一个特殊的点root,求一棵以root为根的有向生成树T, ...
- CodeForces 948B Primal Sport
Primal Sport 题意:2个人玩游戏, 每次轮到一个人选择一个比当前值小的素数, 然后在找到比素数的倍数中最小的并且不小于当前数的一个数. 现在这个游戏玩了2轮, 现在想找到最小的那个起点X0 ...