Netty源码分析 (九)----- 拆包器的奥秘
Netty 的解码器有很多种,比如基于长度的,基于分割符的,私有协议的。但是,总体的思路都是一致的。
拆包思路:当数据满足了 解码条件时,将其拆开。放到数组。然后发送到业务 handler 处理。
半包思路: 当读取的数据不够时,先存起来,直到满足解码条件后,放进数组。送到业务 handler 处理。
拆包的原理
在没有netty的情况下,用户如果自己需要拆包,基本原理就是不断从TCP缓冲区中读取数据,每次读取完都需要判断是否是一个完整的数据包
1.如果当前读取的数据不足以拼接成一个完整的业务数据包,那就保留该数据,继续从tcp缓冲区中读取,直到得到一个完整的数据包
2.如果当前读到的数据加上已经读取的数据足够拼接成一个数据包,那就将已经读取的数据拼接上本次读取的数据,够成一个完整的业务数据包传递到业务逻辑,多余的数据仍然保留,以便和下次读到的数据尝试拼接
netty中拆包的基类
netty 中的拆包也是如上这个原理,在每个SocketChannel中会一个 pipeline ,pipeline 内部会加入解码器,解码器都继承基类 ByteToMessageDecoder,其内部会有一个累加器,每次从当前SocketChannel读取到数据都会不断累加,然后尝试对累加到的数据进行拆包,拆成一个完整的业务数据包,下面我们先详细分析下这个类
看名字的意思是:将字节转换成消息的解码器。人如其名。而他本身也是一个入站 handler,所以,我们还是从他的 channelRead 方法入手。
channelRead 方法
我们先看看基类中的属性,cumulation是此基类中的一个 ByteBuf 类型的累积区,每次从当前SocketChannel读取到数据都会不断累加,然后尝试对累加到的数据进行拆包,拆成一个完整的业务数据包,如果不够一个完整的数据包,则等待下一次从TCP的数据到来,继续累加到此cumulation中
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter {
//累积区
ByteBuf cumulation;
private ByteToMessageDecoder.Cumulator cumulator;
private boolean singleDecode;
private boolean decodeWasNull;
private boolean first;
private int discardAfterReads;
private int numReads;
.
.
.
}
channelRead方法是每次从TCP缓冲区读到数据都会调用的方法,触发点在AbstractNioByteChannel的read方法中,里面有个while循环不断读取,读取到一次就触发一次channelRead
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof ByteBuf) {
// 从对象池中取出一个List
CodecOutputList out = CodecOutputList.newInstance();
try {
ByteBuf data = (ByteBuf) msg;
first = cumulation == null;
if (first) {
// 第一次解码
cumulation = data;//直接赋值
} else {
// 第二次解码,就将 data 向 cumulation 追加,并释放 data
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
// 得到追加后的 cumulation 后,调用 decode 方法进行解码
// 主要目的是将累积区cumulation的内容 decode 到 out数组中
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Throwable t) {
throw new DecoderException(t);
} finally {
// 如果累计区没有可读字节了,有可能在上面callDecode方法中已经将cumulation全部读完了,此时writerIndex==readerIndex
// 每读一个字节,readerIndex会+1
if (cumulation != null && !cumulation.isReadable()) {
// 将次数归零
numReads = 0;
// 释放累计区,因为累计区里面的字节都全部读完了
cumulation.release();
// 便于 gc
cumulation = null;
// 如果超过了 16 次,还有字节没有读完,就将已经读过的数据丢弃,将 readIndex 归零。
} else if (++ numReads >= discardAfterReads) {
numReads = 0;
//将已经读过的数据丢弃,将 readIndex 归零。
discardSomeReadBytes();
} int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
//循环数组,向后面的 handler 发送数据
fireChannelRead(ctx, out, size);
out.recycle();
}
} else {
ctx.fireChannelRead(msg);
}
}
- 从对象池中取出一个空的数组。
- 判断成员变量是否是第一次使用,将 unsafe 中传递来的数据写入到这个 cumulation 累积区中。
- 写到累积区后,在callDecode方法中调用子类的 decode 方法,尝试将累积区的内容解码,每成功解码一个,就调用后面节点的 channelRead 方法。若没有解码成功,什么都不做。
- 如果累积区没有未读数据了,就释放累积区。
- 如果还有未读数据,且解码超过了 16 次(默认),就对累积区进行压缩。将读取过的数据清空,也就是将 readIndex 设置为0.
- 调用 fireChannelRead 方法,将数组中的元素发送到后面的 handler 中。
- 将数组清空。并还给对象池。
下面来说说详细的步骤。
写入累积区
如果当前累加器没有数据,就直接跳过内存拷贝,直接将字节容器的指针指向新读取的数据,否则,调用累加器累加数据至字节容器
ByteBuf data = (ByteBuf) msg;
first = cumulation == null;
if (first) {
cumulation = data;
} else {
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
我们看看构造方法
protected ByteToMessageDecoder() {
this.cumulator = MERGE_CUMULATOR;
this.discardAfterReads = 16;
CodecUtil.ensureNotSharable(this);
}
可以看到 this.cumulator = MERGE_CUMULATOR;,那我们接下来看看 MERGE_CUMULATOR
public static final ByteToMessageDecoder.Cumulator MERGE_CUMULATOR = new ByteToMessageDecoder.Cumulator() {
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf buffer;
if (cumulation.writerIndex() <= cumulation.maxCapacity() - in.readableBytes() && cumulation.refCnt() <= 1) {
buffer = cumulation;
} else {
buffer = ByteToMessageDecoder.expandCumulation(alloc, cumulation, in.readableBytes());
}
buffer.writeBytes(in);
in.release();
return buffer;
}
};
MERGE_CUMULATOR是基类ByteToMessageDecoder中的一个静态常量,其重写了cumulate方法,下面我们看一下 MERGE_CUMULATOR 是如何将新读取到的数据累加到字节容器里的
netty 中ByteBuf的抽象,使得累加非常简单,通过一个简单的api调用 buffer.writeBytes(in); 便将新数据累加到字节容器中,为了防止字节容器大小不够,在累加之前还进行了扩容处理
static ByteBuf expandCumulation(ByteBufAllocator alloc, ByteBuf cumulation, int readable) {
ByteBuf oldCumulation = cumulation;
cumulation = alloc.buffer(oldCumulation.readableBytes() + readable);
cumulation.writeBytes(oldCumulation);
oldCumulation.release();
return cumulation;
}
扩容也是一个内存拷贝操作,新增的大小即是新读取数据的大小
将累加到的数据传递给业务进行拆包
当数据追加到累积区之后,需要调用 decode 方法进行解码,代码如下:
public boolean isReadable() {
//写的坐标大于读的坐标则说明还有数据可读
return this.writerIndex > this.readerIndex;
}
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
// 如果累计区还有可读字节,循环解码,因为这里in有可能是粘包,即多次完整的数据包粘在一起,通过换行符连接
// 下面的decode方法只能处理一个完整的数据包,所以这里循环处理粘包
while (in.isReadable()) {
int outSize = out.size();
// 上次循环成功解码
if (outSize > 0) {
// 处理一个粘包就 调用一次后面的业务 handler 的 ChannelRead 方法
fireChannelRead(ctx, out, outSize);
// 将 size 置为0
out.clear();//
if (ctx.isRemoved()) {
break;
}
outSize = 0;
}
// 得到可读字节数
int oldInputLength = in.readableBytes();
// 调用 decode 方法,将成功解码后的数据放入道 out 数组中
decode(ctx, in, out);
if (ctx.isRemoved()) {
break;
}
if (outSize == out.size()) {
if (oldInputLength == in.readableBytes()) {
break;
} else {
continue;
}
}
if (isSingleDecode()) {
break;
}
}
}
我们看看 fireChannelRead
static void fireChannelRead(ChannelHandlerContext ctx, List<Object> msgs, int numElements) {
if (msgs instanceof CodecOutputList) {
fireChannelRead(ctx, (CodecOutputList)msgs, numElements);
} else {
//将所有已解码的数据向下业务hadder传递
for(int i = 0; i < numElements; ++i) {
ctx.fireChannelRead(msgs.get(i));
}
}
}
该方法主要逻辑:只要累积区还有未读数据,就循环进行读取。
调用 decodeRemovalReentryProtection 方法,内部调用了子类重写的 decode 方法,很明显,这里是个模板模式。decode 方法的逻辑就是将累积区的内容按照约定进行解码,如果成功解码,就添加到数组中。同时该方法也会检查该 handler 的状态,如果被移除出 pipeline 了,就将累积区的内容直接刷新到后面的 handler 中。
如果 Context 节点被移除了,直接结束循环。如果解码前的数组大小和解码后的数组大小相等,且累积区的可读字节数没有变化,说明此次读取什么都没做,就直接结束。如果字节数变化了,说明虽然数组没有增加,但确实在读取字节,就再继续读取。
如果上面的判断过了,说明数组读到数据了,但如果累积区的 readIndex 没有变化,则抛出异常,说明没有读取数据,但数组却增加了,子类的操作是不对的。
如果是个单次解码器,解码一次就直接结束了,如果数据包一次就解码完了,则下一次循环时 in.isReadable()就为false,因为 writerIndex = this.readerIndex 了
所以,这段代码的关键就是子类需要重写 decode 方法,将累积区的数据正确的解码并添加到数组中。每添加一次成功,就会调用 fireChannelRead 方法,将数组中的数据传递给后面的 handler。完成之后将数组的 size 设置为 0.
所以,如果你的业务 handler 在这个地方可能会被多次调用。也可能一次也不调用。取决于数组中的值。
解码器最主要的逻辑:
将 read 方法的数据读取到累积区,使用解码器解码累积区的数据,解码成功一个就放入到一个数组中,并将数组中的数据一次次的传递到后面的handler。
清理字节容器
业务拆包完成之后,只是从累积区中取走了数据,但是这部分空间对于累积区来说依然保留着,而字节容器每次累加字节数据的时候都是将字节数据追加到尾部,如果不对累积区做清理,那么时间一长就会OOM,清理部分的代码如下
finally {
// 如果累计区没有可读字节了,有可能在上面callDecode方法中已经将cumulation全部读完了,此时writerIndex==readerIndex
// 每读一个字节,readerIndex会+1
if (cumulation != null && !cumulation.isReadable()) {
// 将次数归零
numReads = 0;
// 释放累计区,因为累计区里面的字节都全部读完了
cumulation.release();
// 便于 gc
cumulation = null;
// 如果超过了 16 次,还有字节没有读完,就将已经读过的数据丢弃,将 readIndex 归零。
} else if (++ numReads >= discardAfterReads) {
numReads = 0;
//将已经读过的数据丢弃,将 readIndex 归零。
discardSomeReadBytes();
}
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
//循环数组,向后面的 handler 发送数据
fireChannelRead(ctx, out, size);
out.recycle();
}
- 如果累积区没有可读数据了,将计数器归零,并释放累积区。
- 如果不满足上面的条件,且计数器超过了 16 次,就压缩累积区的内容,压缩手段是删除已读的数据。将 readIndex 置为 0。还记得 ByteBuf 的指针结构吗?
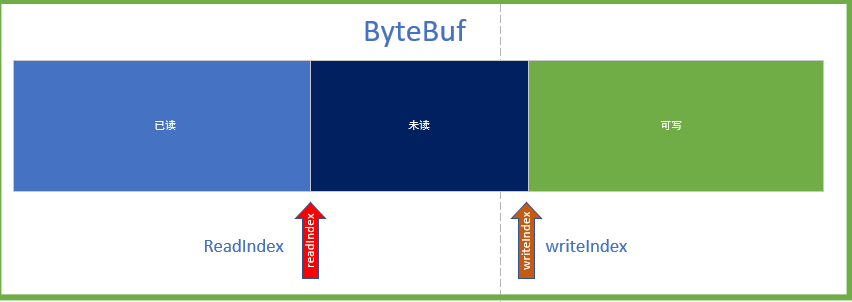
public ByteBuf discardSomeReadBytes() {
this.ensureAccessible();
if (this.readerIndex == 0) {
return this;
} else if (this.readerIndex == this.writerIndex) {
this.adjustMarkers(this.readerIndex);
this.writerIndex = this.readerIndex = 0;
return this;
} else {
//读指针超过了Buffer容量的一半时做清理工作
if (this.readerIndex >= this.capacity() >>> 1) {
//拷贝,从readerIndex开始,拷贝this.writerIndex - this.readerIndex 长度
this.setBytes(0, this, this.readerIndex, this.writerIndex - this.readerIndex);
//writerIndex=writerIndex-readerIndex
this.writerIndex -= this.readerIndex;
this.adjustMarkers(this.readerIndex);
//将读指针重置为0
this.readerIndex = 0;
}
return this;
}
}
我们看到discardSomeReadBytes 主要是将未读的数据拷贝到原Buffer,重置 readerIndex 和 writerIndex
我们看到最后还调用 fireChannelRead 方法,尝试将数组中的数据发送到后面的 handler。为什么要这么做。按道理,到这一步的时候,数组不可能是空,为什么这里还要这么谨慎的再发送一次?
如果是单次解码器,就需要发送了,因为单词解码器是不会在 callDecode 方法中发送的。
总结
可以说,ByteToMessageDecoder 是解码器的核心所做,Netty 在这里使用了模板模式,留给子类扩展的方法就是 decode 方法。
主要逻辑就是将所有的数据全部放入累积区,子类从累积区取出数据进行解码后放入到一个 数组中,ByteToMessageDecoder 会循环数组调用后面的 handler 方法,将数据一帧帧的发送到业务 handler 。完成这个的解码逻辑。
使用这种方式,无论是粘包还是拆包,都可以完美的实现。
Netty 所有的解码器,都可以在此类上扩展,一切取决于 decode 的实现。只要遵守 ByteToMessageDecoder 的约定即可。
Netty源码分析 (九)----- 拆包器的奥秘的更多相关文章
- 【转】netty源码分析之LengthFieldBasedFrameDecoder
原文:https://www.jianshu.com/p/a0a51fd79f62 拆包的原理 关于拆包原理的上一篇博文 netty源码分析之拆包器的奥秘 中已详细阐述,这里简单总结下:netty的拆 ...
- 【Netty源码分析】发送数据过程
前面两篇博客[Netty源码分析]Netty服务端bind端口过程和[Netty源码分析]客户端connect服务端过程中我们分别介绍了服务端绑定端口和客户端连接到服务端的过程,接下来我们分析一下数据 ...
- 【Netty源码分析】客户端connect服务端过程
上一篇博客[Netty源码分析]Netty服务端bind端口过程 我们介绍了服务端绑定端口的过程,这一篇博客我们介绍一下客户端连接服务端的过程. ChannelFuture future = boos ...
- netty源码分析之揭开reactor线程的面纱(二)
如果你对netty的reactor线程不了解,建议先看下上一篇文章netty源码分析之揭开reactor线程的面纱(一),这里再把reactor中的三个步骤的图贴一下 reactor线程 我们已经了解 ...
- netty源码分析之二:accept请求
我在前面说过了server的启动,差不多可以看到netty nio主要的东西包括了:nioEventLoop,nioMessageUnsafe,channelPipeline,channelHandl ...
- Netty源码分析(前言, 概述及目录)
Netty源码分析(完整版) 前言 前段时间公司准备改造redis的客户端, 原生的客户端是阻塞式链接, 并且链接池初始化的链接数并不高, 高并发场景会有获取不到连接的尴尬, 所以考虑了用netty长 ...
- Netty源码分析第1章(Netty启动流程)---->第1节: 服务端初始化
Netty源码分析第一章: Server启动流程 概述: 本章主要讲解server启动的关键步骤, 读者只需要了解server启动的大概逻辑, 知道关键的步骤在哪个类执行即可, 并不需要了解每一步的 ...
- Netty源码分析第1章(Netty启动流程)---->第2节: NioServerSocketChannel的创建
Netty源码分析第一章: Server启动流程 第二节:NioServerSocketChannel的创建 我们如果熟悉Nio, 则对channel的概念则不会陌生, channel在相当于一个通 ...
- Netty源码分析第1章(Netty启动流程)---->第3节: 服务端channel初始化
Netty源码分析第一章:Netty启动流程 第三节:服务端channel初始化 回顾上一小节的initAndRegister()方法: final ChannelFuture initAndRe ...
- Netty源码分析第1章(Netty启动流程)---->第4节: 注册多路复用
Netty源码分析第一章:Netty启动流程 第四节:注册多路复用 回顾下以上的小节, 我们知道了channel的的创建和初始化过程, 那么channel是如何注册到selector中的呢?我们继 ...
随机推荐
- 信安周报-第02周:SQL基础
信安之路 第02周 Code:https://github.com/lotapp/BaseCode/tree/master/safe 前言 本周需要自行研究学习的任务贴一下: 1.概念(推荐) 数据库 ...
- spring cloud 断路器 Hystrix
一.微服务架构中使用断路器的原因 二.代码实现 1.在Ribbon中使用短路器 1.1.引入依赖 <dependency> <groupId>org.springframewo ...
- .Net Mvc过滤器观察者模式记录网站报错信息
基本介绍: 观察者模式是一种对象行为模式.它定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新.在观察者模式中,主题是通知的发布者,它发出通知时并不 ...
- go 学习笔记之是否支持以及如何实现继承
熟悉面向对象的小伙伴们可能会知道封装,继承和多态是最主要的特性,为什么前辈们会如此看重这三种特性,真的那么重要吗? 什么是封装 什么是封装,封装有什么好处以及怎么实现封装? 相信大多数小伙伴们都有自己 ...
- Python中模块与包的导入(朴实易懂版的总结)
这几天,被python包与模块的导入问题,折磨的不行,以前想的很简单,其实不然,经查资料研究,特总结如下: 基本注意点 模块:一般指一个py文件:包:含有许多py文件的文件夹,含有 或不含有(Pyth ...
- mybatis多表查询之多对多关系查询的实现-xml方式
Mybatis对于多对多关系下的查询提供了集合(collection)的概念来解决,collection属性是resultMap高级结果映射的子集,首先,在本例中我们使用的是集合元素来解决多对多的查询 ...
- C#代码实现IoC(控制反转)设计,以及我对IoC的理解
一. 什么是IoC 当在A类中要使用B类的时候,我们一般都是采用new的方式来实例化B类,这样一来这两个类就有很强的依赖关系,不符合低耦合的设计思想.这时候我们可以通过一个中间容器来实例化对象,需要的 ...
- Unity Shader 卡通渲染 基于退化四边形的实时描边
从csdn转移过来,顺便把写过的文章改写一下转过来. 一.边缘检测算法 3D模型描边有两种方式,一种是基于图像,即在所有3D模型渲染完成一张图片后,对这张图片进行边缘检测,最后得出描边效果.一种是基于 ...
- 【数据库】MySQL 函数大全包含示例(涵盖了常用如时间、数字、字符串处理、数据流函数的和一些冷门的)
ps:博客园markdown不能自动生成列表,更好的阅读体验可访问我的个人博客http://www.isspark.com/archives/mysqlFunctionDesc 数学函数(Mathem ...
- Oracle - 获取当前周别函数
CREATE OR REPLACE FUNCTION GET_WEEK (V_RQ in DATE) return varchar2 as str varchar2(); str1 varchar2( ...