MySQL优化之索引原理(二)
一,前言
上一篇内容说到了MySQL存储引擎的相关内容,及数据类型的选择优化。下面再来说说索引的内容,包括对B-Tree和B+Tree两者的区别。
1.1,什么是索引
索引是存储引擎用于快速找到记录的一种数据结构, 对性能的提升有很大的帮助,尤其当表中数量较大的情况下,索引正确的使用可以对性能提升几个数量级。
但是索引经常被忽略,不恰当的索引对性能可能还会带来负面效果。
1.2,什么时候添加索引
主键自动建立主键索引(唯一索引)
where字句中的列,频繁作为查询字段的列
表连接关联的列
排序用到的列
索引的基数越大(选择性大),索引的效率就越高
什么叫基数越大,比如手机号,每个列都具有不同的值,非常好区别,这个就适合建立索引,而性别这样的字段,因为只有两个值,以不适合建立索引,就是区分度高低的问题。
1.3,不适合添加索引
- 表中数据太少
- 频繁修改的字段
- 数据重复且分布平均的字段
1.4,索引的分类
单值索引:即一个索引只包含单个列,一个表可以有多个单列索引。
唯一索引:索引列的值必须唯一,但是允许有空值。
复合索引:即一个索引包含多个列。
全文索引:使用fulltext创建全文索引。
在旧版MySQL中全文索引只能用在MyISAM表格的char、varchar和text的字段上。新版的MySQL5.6.24上InnoDB引擎也加入了全文索引。
使用方式:
- 创建索引:create [unique|fulltext] index 索引名 on 表名 (属性名[长度][asc|desc])。
- 删除索引:drop index 索引名 on 表名。
- 查看索引:show index from 表名。
具体使用方式这里就不详细说明,接下来就说说关于索引的实现原理,Tree,B-Tree,B+Tree。
二,Tree
在总结B-Tree和B+Tree之前,先看看最基本的二叉树结构吧,因为前两种树结构够可以算是二叉树的变种。
二叉树是n(n>=0)个结点的有限集合,该集合或者为空集(称为空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树组成。
二叉树的特点:
- 每个结点最多有两颗子树,所以二叉树中不存在度大于2的结点。
- 左子树和右子树是有顺序的,次序不能任意颠倒。
- 从根节点出发,左子树都是比根节点小的,而右子树都是比根节点大的。
因此对于较平衡的二叉树的查找性能,是几乎接近于二分查找的,但是如果存入的数据都比根节点小,或者都比根节点大,则会出现以下情况。
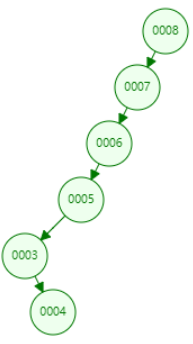
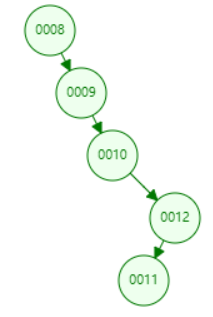
这两种情况分别是左斜树和右斜树,上述情况毫无疑问在二叉树搜索时,效率是非常低的。因为它已经失去了树的结构,不管是查询节点,还是添加删除等,都是对每个节点依次遍历,直到查出目标节点为止。
另外还有一点也是很重要,如果二叉树的字节点或多,一百万,一千万,甚至上亿数据。对于较大数据量的二叉树,会将其保存在磁盘中,那么问题来了。如果要查询的数据在树的底层,那么就势必会造成多次的磁盘IO,而磁盘IO的读取比内存读取的速度要低100倍左右。这种情况下,不管是从性能来说,还是效率这都不是一个好的结果。
接着再说B-Tree结构,是二叉树的一种升级版。
三,B-Tree
B树又被成为平衡多路查找树。
- 树中每个结点最多含有m个节点(且m>2)。
- 除根结点和叶子结点外,其它每个结点至少有[m / 2,m]个孩子。
- 若根结点不是叶子结点,则至少有2个孩子(特殊情况:整棵树只有一个根节点)。
- 所有叶子结点都出现在同一层。
在B-Tree或者B+Tree中,都会存在一个关于度的概念,也就是上面提到的m值。什么是度,可以说是我们自定义的一个阈值,当节点数量达到这个阈值时,树的结构便会发生变化,此时便转变成B-Tree结构。
现在,设定度(m)为3,首先我们先插入两个节点:
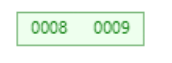
发现在B树结构中,当插入9节点时,并没有成为8节点的右子树,这是为什么。首先在于这就是B树的结构特点,没有成为8节点的右子树是不是就减少了树的层级深度。其次就是我们设定B树的度为3,接着将再添加10节点,看有什么变化。
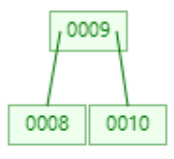
这个时候已经达到最大值3,那么根据二叉树的结构特点,将9提升为根节点,8和10分别为9的左右子节点。
继续添加6
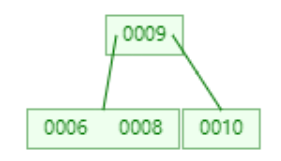
添加11
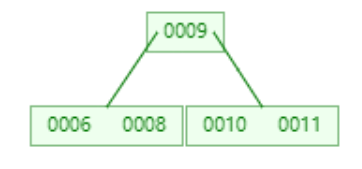
添加15
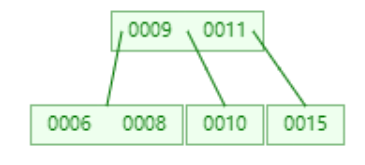
分析:
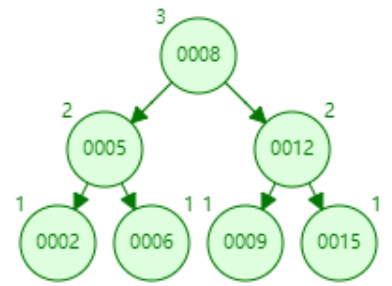
1,当添加11完成时,叶子节点全部都达到了度为2,而添加15时,由于比根节点9大,所以添加到右子树中。则右子树变成0010,0011,0015。显然达到我们设定的阈值,根据以上规则,将0011提升为根节点。
2,从图中可以看出,9的左边都是比根节点小,9到11之间都是大于9小于11的,最后11的右边都是大于11的。
3,最后我们再添加5,我们先来分析下结构会如何变化,5小于9,所以会在左边,变成005,006,008,这个时候节点数量变成3,根据规则006应该提升为根节点。但是根节点又会变成006,009,0011,同样达到阈值,那么将009再提升为根节点。最终结果如图:
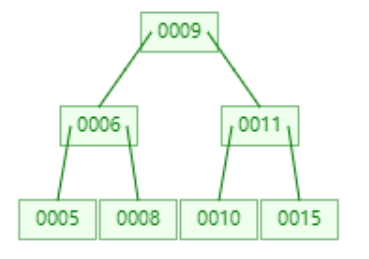
以上就是B-Tree的原理总结,那么这与二叉树有什么区别呢。最直观的就是树的层级变少了,同样也不会出现左右斜树的情况。
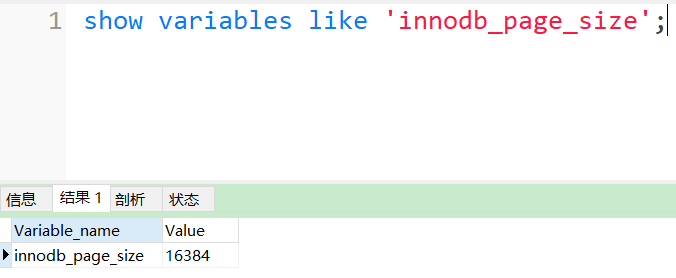
在InnoDB存储引擎中有页(Page)的概念,页就是磁盘管理的最小单位。InnoDB存储引擎中默认每个页的大小为16KB。并且可通过参数innodb_page_size将页的大小设置为4K、8K、16K。
在B-Tree中,每个节点都会携带一个key信息,用于保存该数据在表中的位置,同时也会将数据保存到节点中。当节点不是叶子节点时,父节点会携带对象的指针指向其子节点在磁盘中的位置。根据磁盘存储的页大小,如果每个叶子节点都携带较多的信息,那么在磁盘中占用的空间资源也会越多。显然这不是一个好的现象,因此就出现B-Tree的优化版,B+Tree。
四,B+Tree
InnoDB存储引擎就是用B+Tree实现其索引结构。
在B+Tree结构中,每一层非叶子节点只存储key值信息,而叶子节点只存放数据信息。这种结构不仅节省磁盘的空间,对节点的查询效率也大大提高了很多。
除此之外,非叶子节点的key最终会全部出现在叶子节点上, 这么说很抽象,请看演示效果。
首先添加7,8两个节点。
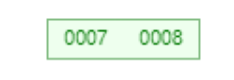
接着添加9节点。

同样度达到了3,将8提升为根节点。但是与B-Tree不同的是,在叶子节点中也存在8节点,这就是B+Tree结构的特点,然后再添加10节点。
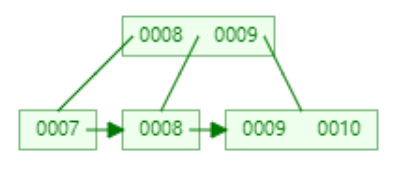
以此类推,在最后的叶子节点中,整个树中的key都在存在,那么这与B-Tree有什么区别呢。每个节点中没有数据存储,只有key值信息,在磁盘中会存储更多的数据。
五,总结
思考一个问题:
对于查询效率最快的数据结构,哈希表的效率要比树状结构快的多,那么MySQL存储引擎为什么不采用哈希表结构存储数据,原因就是哈希表是不能进行范围查找。
本篇博客并没有讲述对索引使用的优化,只系统阐述了MySQL索引的底层机制,那么使用索引优化,查询优化,库表结构优化会在最后一篇博客中全部分享完。
以上内容均是自主学习总结,如有错误欢迎留言指正。
感谢阅读!
MySQL优化之索引原理(二)的更多相关文章
- mysql 优化之索引的使用
mysql 优化之索引的使用 1:MySQL 索引简介: MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度. 打个比方,如果合理的设计且使用索引的MySQL ...
- MySQL的InnoDB索引原理详解
摘要 本篇介绍下Mysql的InnoDB索引相关知识,从各种树到索引原理到存储的细节. InnoDB是Mysql的默认存储引擎(Mysql5.5.5之前是MyISAM,文档).本着高效学习的目的,本篇 ...
- MySQL的InnoDB索引原理详解 (转)
摘要: 本篇介绍下Mysql的InnoDB索引相关知识,从各种树到索引原理到存储的细节. InnoDB是Mysql的默认存储引擎(Mysql5.5.5之前是MyISAM,文档).本着高效学习的目的,本 ...
- mysql七:索引原理与慢查询优化(待完整)
一.介绍 索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构.索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要. 索引优化应该是对查询性能优 ...
- 0x08 MySQL 超详细-索引原理&慢查询优化【转-多图】(重点)
Content From——Egon's Blog http://www.cnblogs.com/linhaifeng/articles/7274563.html#top 0x01 介绍 为何要有索引 ...
- Mysql数据库的索引原理
写在前面:索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点.考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储100条记录.如果没有索引,查询将 ...
- 第九课——MySQL优化之索引和执行计划
一.创建索引需要关注什么? 1.关注基数列唯一键的数量: 比如性别,该列只有男女之分,所以性别列基数是2: 2.关注选择性列唯一键与行数的比值,这个比值范围在0~1之前,值越小越好: 其实,选择性列唯 ...
- MySQL优化之索引解析
索引的本质 MySQL索引或者说其他关系型数据库的索引的本质就只有一句话,以空间换时间. 索引的作用 索引关系型数据库为了加速对表中行数据检索的(磁盘存储的)数据结构 索引的分类 数据结构上面的分类 ...
- mysql优化之索引篇
对mysql优化是一个综合性的技术,主要包括 a: 表的设计合理化(符合3NF) b: 添加适当索引(index) [四种: 普通索引.主键索引.唯一索引unique.全文索引] c: 分表技术(水平 ...
随机推荐
- AUTOCAD二次开发-----删除一个图层里面的所有对象
https://blog.csdn.net/aasswwe/article/details/40899759 private void Test() { // 获取当前文档和数据库 Document ...
- python方法的使用
1.函数定义 def 函数名(形参): 函数体 return 返回值 2.函数执行 ...
- 只需一步,在Spring Boot中统一Restful API返回值格式与统一处理异常
## 统一返回值 在前后端分离大行其道的今天,有一个统一的返回值格式不仅能使我们的接口看起来更漂亮,而且还可以使前端可以统一处理很多东西,避免很多问题的产生. 比较通用的返回值格式如下: ```jav ...
- WebSocket实现数据库更新前台实时显示
通过一个小实例来实现数据库更新后,推送消息给前台,让前台进行相应操作. 需求 数据库更新之后服务器推送消息给前台,让前台做操作.(数据库的数据不是由服务器写入的) 实现的话说到底都是用轮询,因为数据库 ...
- 原生js实现的一个随机颜色的简单效果
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <meta na ...
- Delphi - cxGrid添加Footer显示
cxGrid - 添加footer显示 1:添加Footer Items 单击cxGrid Customize... ,Summary,Add: 2:添加Footer items数据绑定 选中一条需要 ...
- A-The power of Fibonacci_2019牛客暑期多校训练营(第九场)
题意 求\(\sum_0^n{Fb}_i^m \mod (1e9)\) 题解 模1e9时的斐波那契数列循环节太大,考虑把模数质因数分解成\(2^9\cdot5^9\),此时循环节变成768和78125 ...
- HDU5988 - 2016icpc青岛 - G - Coding Contest 费用流(利用对数化乘为加
HDU5988 题意: 有n个区域,每个区域有s个人,b份饭.现在告诉你每个区域间的有向路径,每条路有容量和损坏路径的概率.问如何走可以使得路径不被破坏的概率最小.第一个人走某条道路是百分百不会损坏道 ...
- HDU4348To the moon主席树,区间修改
题意: 一个长度为n的数组,4种操作 : (1)C l r d:区间[l,r]中的数都加1,同时当前的时间戳加1 . (2)Q l r:查询当前时间戳区间[l,r]中所有数的和 . (3)H l r ...
- CodeForces 948B Primal Sport
Primal Sport 题意:2个人玩游戏, 每次轮到一个人选择一个比当前值小的素数, 然后在找到比素数的倍数中最小的并且不小于当前数的一个数. 现在这个游戏玩了2轮, 现在想找到最小的那个起点X0 ...