<编译原理 - 函数绘图语言解释器(2)语法分析器 - python>
<编译原理 - 函数绘图语言解释器(2)语法分析器 - python>
背景
编译原理上机实现一个对函数绘图语言的解释器 - 用除C外的不同种语言实现
设计思路:
设计函数绘图语言的文法,使其适合递归下降分析;
设计语法树的结构,用于存放表达式的语法树;
设计递归下降子程序,分析句子并构造表达式的语法树;
设计测试程序和测试用例,检验分析器是否正确。
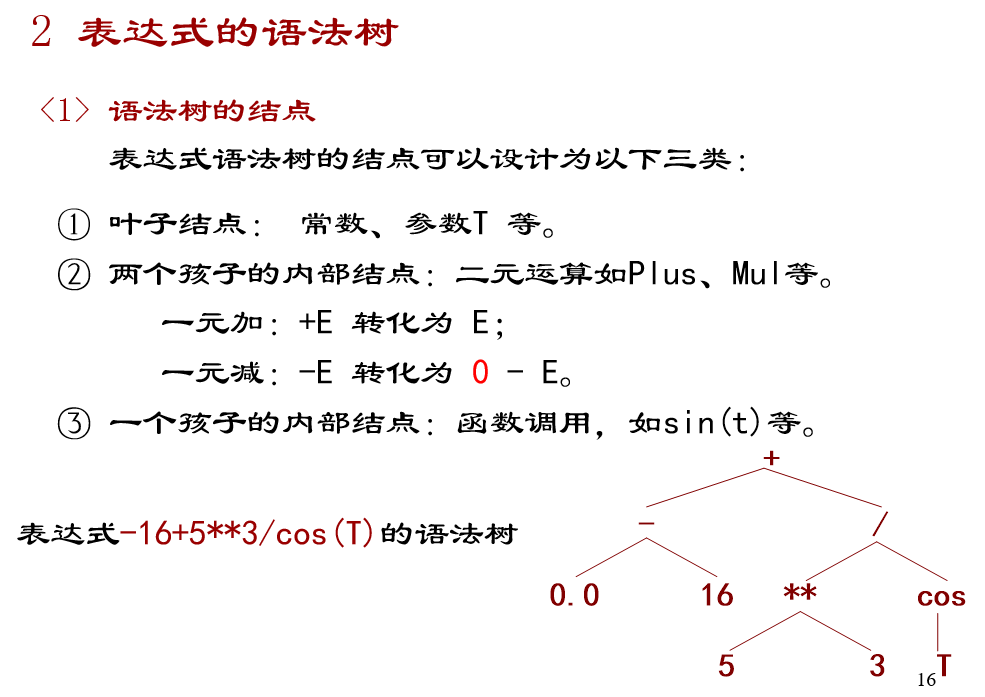
消除无二义/无左递归完整的EBNF文法:

- 表达式的语法树:
- 用Pycharm写了三个.py文件:
parserclass.py
parserfunc.py
parsermain.py
输入流是词法分析器得到的记号流,输出流是语法树
测试文本序列(1)
FOR T FROM 0 TO 2*PI STEP PI/50 DRAW(COS(T),SIN(T));
+ 测试文本序列 (2)
//------------------This is zhushi!!------------------------
ORIGIN IS (100,300); // Sets the offset of the origin
ROT IS 0; // Set rotation Angle.
SCALE IS (1,1); // Set the abscissa and ordinate scale.
FOR T FROM 0 TO 200 STEP 1 DRAW (T,0); // The trajectory of the x-coordinate.
FOR T FROM 0 TO 150 STEP 1 DRAW (0,-T); // The trajectory of the y-coordinate.
FOR T FROM 0 TO 120 STEP 1 DRAW (T,-T); // The trajectory of the function f[t]=t.
Step 1 :parserclass.py - 构造语法树节点类
import scannerclass as sc
class ExprNode(object): ## 语法树节点类
def __init__(self,item): ## item 表示符号类型Token_Type
self.item = item #表示对应的元素
if self.item == sc.Token_Type.PLUS or self.item == sc.Token_Type.MINUS or \
self.item == sc.Token_Type.MUL or self.item == sc.Token_Type.DIV or \
self.item == sc.Token_Type.POWER:
# 运算符 - 两个孩子
self.left=None
self.right=None
elif self.item == sc.Token_Type.FUNC:
self.FuncPtr = None
self.center = None ## 一个孩子
self.value = None ## 传入的所有类型都有value
def __str__(self): ## 叶子节点
return str(self.item) #print 一个 Node 类时会打印 __str__ 的返回值
def GetExprValue(self):
if self.item == sc.Token_Type.PLUS:
self.value = self.right.value + self.left.value
elif self.item == sc.Token_Type.MINUS:
self.value = self.left.value - self.right.value
elif self.item == sc.Token_Type.MUL:
self.value = self.left.value * self.right.value
elif self.item == sc.Token_Type.DIV:
self.value = self.left.value / self.right.value
elif self.item == sc.Token_Type.POWER:
self.value = self.left.value ** self.right.value
elif self.item == sc.Token_Type.FUNC:
self.value = self.FuncPtr(self.center.value)
return self.value
Step 2 :parserfunc.py - 构造语法分析器类
#!/usr/bin/env python
# encoding: utf-8
'''
@author: 黄龙士
@license: (C) Copyright 2019-2021,China.
@contact: iym070010@163.com
@software: xxxxxxx
@file: parserfunc.py
@time: 2019/11/26 19:47
@desc:
'''
import parserclass as ps
import scannerclass as sc
import scannerfunc as sf
import sys
import numpy as np
class Parsef(object):
def __init__(self,scanner):
self.scanner = scanner ## 传入的一个初始化后的scanner
self.token = None
self.Parameter,self.Origin_x,self.Origin_y,self.Scale_x,self.Scale_y,self.Rot_angle = (0,0,0,1,1,0)
self.x_ptr, self.y_ptr = (None,None)
self.Tvalue = 0 # len(Tvalue)==1
def enter(self,x):
print('enter in '+str(x)+'\n')
def back(self,x):
print('exit from ' + str(x) + '\n')
def call_match(self,x):
print('match token ' + str(x) + '\n')
def Tree_trace(self,x):
self.PrintSyntaxTree(x, 1) #打印语法树
def FetchToken(self): # 调用词法分析器的GetToken,保存得到结果
self.token = self.scanner.GetToken()
while self.token.type == sc.Token_Type.NONTOKEN: ## 如果读取的是空格,则再继续读取,所以token不可能是空格
self.token = self.scanner.GetToken()
if (self.token.type == sc.Token_Type.ERRTOKEN):
self.SyntaxError(1) ## 如果得到的记号是非法输入errtoken,则指出一个词法错误
## 匹配当前记号
def MatchToken(self,The_Token):
if (self.token.type != The_Token):
self.SyntaxError(2) # 若失败,则指出一个语法错误
if The_Token == sc.Token_Type.SEMICO:
self.scanner.fp.readline()
last = self.scanner.fp.tell()
str = self.scanner.fp.readline()
if len(str) == 0: ## 最后一行读完,直接退出,token还是sc.Token_Type.SEMICO
return
else:
self.scanner.fp.seek(last) ## 否则就返回到之前的位置
self.FetchToken() # 若成功,则获取下一个
### //语法错误处理
def SyntaxError(self,x):
if x == 1:
print(self.token.type)
self.ErrMsg(self.scanner.LineNo, " 错误记号 ", self.token.lexeme)
elif x == 2:
self.ErrMsg(self.scanner.LineNo, " 不是预期记号 ", self.token.lexeme)
## 打印错误信息
def ErrMsg(self,LineNo,descrip,string):
print("Line No {:3d}:{:s} {:s} !\n".format(LineNo, descrip, string))
self.scanner.CloseScanner()
sys.exit(1)
def PrintSyntaxTree(self,root,indent): #打印语法树 - 先序遍历并打印表达式的语法树
for temp in range(indent): # 缩进
print('\t',end=" ")
if root.item == sc.Token_Type.PLUS:
print('+ ')
elif root.item == sc.Token_Type.MINUS:
print('- ')
elif root.item == sc.Token_Type.MUL:
print('* ')
elif root.item == sc.Token_Type.DIV:
print('/ ')
elif root.item == sc.Token_Type.POWER:
print('** ')
elif root.item == sc.Token_Type.FUNC:
print('{} '.format(root.FuncPtr))
elif root.item == sc.Token_Type.CONST_ID: ##
print('{:5f} '.format(root.value))
elif root.item == sc.Token_Type.T:
print('{} '.format(root.value))
else:
print("Error Tree Node !\n")
sys.exit(0)
if root.item == sc.Token_Type.CONST_ID or root.item == sc.Token_Type.T: # 叶子节点返回
return ## 常数和参数只有叶子节点 #常数:右值;参数:左值地址
elif root.item == sc.Token_Type.FUNC: #递归打印一个孩子节点
self.PrintSyntaxTree(root.center, indent + 1) # 函数有孩子节点和指向函数名的指针
else: # 递归打印两个孩子节点 二元运算:左右孩子的内部节点
self.PrintSyntaxTree(root.left, indent + 1)
self.PrintSyntaxTree(root.right, indent + 1)
#绘图语言解释器入口(与主程序的外部接口)
def Parser(self): #语法分析器的入口
self.enter("Parser")
if (self.scanner.fp == None): #初始化词法分析器
print("Open Source File Error !\n")
else:
self.FetchToken() #获取第一个记号
self.Program() #递归下降分析
self.scanner.CloseScanner() #关闭词法分析器
self.back("Parser")
def Program(self):
self.enter("Program") # 每句话
while (self.token.type != sc.Token_Type.SEMICO): #记号类型不是分隔符 - 如果最后一行读完了,则记号仍是分隔符;否则不会是分隔符
self.Statement() #转到每一种文法
self.MatchToken(sc.Token_Type.SEMICO) #匹配到分隔符
self.call_match(";")
self.back("Program")
##----------Statement的递归子程序 开始状态
def Statement(self): ##转到每一种文法 ## 构造的文法
self.enter("Statement")
if self.token.type == sc.Token_Type.ORIGIN:
self.OriginStatement()
elif self.token.type == sc.Token_Type.SCALE:
self.ScaleStatement()
elif self.token.type == sc.Token_Type.ROT:
self.RotStatement()
elif self.token.type == sc.Token_Type.FOR:
self.ForStatement()
elif self.token.type == sc.Token_Type.CONST_ID or self.token.type == sc.Token_Type.L_BRACKET or \
self.token.type == sc.Token_Type.MINUS:
self.Expression()
else: self.SyntaxError(2)
self.back("Statement")
##----------OriginStatement的递归子程序
##eg:origin is (20, 200);
def OriginStatement(self):
self.enter("OriginStatement")
self.MatchToken(sc.Token_Type.ORIGIN)
self.call_match("ORIGIN")
self.MatchToken(sc.Token_Type.IS)
self.call_match("IS")
self.MatchToken(sc.Token_Type.L_BRACKET) ## eg:origin is (
self.call_match("(")
tmp = self.Expression()
self.Origin_x = tmp.GetExprValue() # 获取横坐标点平移距离
self.MatchToken(sc.Token_Type.COMMA) ## eg: ,
self.call_match(",")
tmp = self.Expression()
self.Origin_y = tmp.GetExprValue() #获取纵坐标的平移距离
self.MatchToken(sc.Token_Type.R_BRACKET) ##eg: )
self.call_match(")")
self.back("OriginStatement")
## ----------ScaleStatement的递归子程序
## eg: scale is (40, 40);
def ScaleStatement(self):
self.enter("ScaleStatement")
self.MatchToken(sc.Token_Type.SCALE)
self.call_match("SCALE")
self.MatchToken(sc.Token_Type.IS)
self.call_match("IS")
self.MatchToken(sc.Token_Type.L_BRACKET) ## eg: scale is (
self.call_match("(")
tmp = self.Expression()
self.Scale_x = tmp.GetExprValue() ## 获取横坐标的比例因子
self.MatchToken(sc.Token_Type.COMMA) ## eg:,
self.call_match(",")
tmp = self.Expression()
self.Scale_y = tmp.GetExprValue() ## 获取纵坐标的比例因子
self.MatchToken(sc.Token_Type.R_BRACKET) ## eg:)
self.call_match(")")
self.back("ScaleStatement")
## ----------RotStatement的递归子程序
## eg: rot is 0;
def RotStatement(self):
self.enter("RotStatement")
self.MatchToken(sc.Token_Type.ROT)
self.call_match("ROT")
self.MatchToken(sc.Token_Type.IS) ## eg: rot is
self.call_match("IS")
tmp = self.Expression()
self.Rot_angle = tmp.GetExprValue() ## 获取旋转角度
self.back("RotStatement")
## ----------ForStatement的递归子程序
## 对右部文法符号的展开->遇到终结符号直接匹配,遇到非终结符就调用相应子程序
## ForStatement中唯一的非终结符是Expression,他出现在5个不同位置,分别代表循环的起始、终止、步长、横坐标、纵坐标,需要5个树节点指针保存这5棵语法树
## eg:for T from 0 to 2 * pi step pi / 50 draw (t, -sin(t))
## ExprNode *start_ptr, *end_ptr, *step_ptr, *x_ptr, *y_ptr;//指向各表达式语法树根节点
def ForStatement(self):
Start, End, Step = (0.0,0.0,0.0) ## 绘图起点、终点、步长
self.enter("ForStatement")
## 遇到非终结符就调用相应子程序
self.MatchToken(sc.Token_Type.FOR)
self.call_match("FOR")
self.MatchToken(sc.Token_Type.T)
self.call_match("T")
self.MatchToken(sc.Token_Type.FROM)
self.call_match("FROM") ## eg:for T from
start_ptr = self.Expression() ## 获得参数起点表达式的语法树
## 'NoneType' object has no attribute 'GetExprValue'
Start = start_ptr.GetExprValue() ## 计算参数起点表达式的值
self.MatchToken(sc.Token_Type.TO)
self.call_match("TO") ## eg: to
end_ptr = self.Expression() ## 构造参数终点表达式语法树
End = end_ptr.GetExprValue() ## 计算参数终点表达式的值 eg: step 2 * pi
self.MatchToken(sc.Token_Type.STEP)
self.call_match("STEP") ## eg: step
step_ptr = self.Expression() ## 构造参数步长表达式语法树
Step = step_ptr.GetExprValue() ## 计算参数步长表达式的值 eg: pi / 50 并存起来
self.Tvalue = np.arange(Start,End,Step)
self.MatchToken(sc.Token_Type.DRAW)
self.call_match("DRAW")
self.MatchToken(sc.Token_Type.L_BRACKET)
self.call_match("(") ## eg: draw(
self.x_ptr = self.Expression() ## 跟节点 eg: t 把x_ptr存起来
self.x_ptr = self.x_ptr.value
# self.x_ptr = self.x_ptr.GetExprValue() ## 直接存储二元组即可
self.MatchToken(sc.Token_Type.COMMA)
self.call_match(",") ## eg:,
self.y_ptr = self.Expression() ## 根节点 把x_ptr存起来
self.y_ptr = self.y_ptr.value
# self.y_ptr = self.y_ptr.GetExprValue()
self.MatchToken(sc.Token_Type.R_BRACKET)
self.call_match(")")
self.back("ForStatement")
## ----------Expression的递归子程序
## 把函数设计为语法树节点的指针,在函数内引进2个语法树节点的指针变量,分别作为Expression左右操作数(Term)的语法树节点指针
## 表达式应该是由正负号或无符号开头、由若干个项以加减号连接而成。
def Expression(self): ## 展开右部,并且构造语法树
self.enter("Expression")
left = self.Term() ## 分析左操作数且得到其语法树
while (self.token.type == sc.Token_Type.PLUS or self.token.type == sc.Token_Type.MINUS):
token_tmp = self.token.type
self.MatchToken(token_tmp)
right = self.Term() ## 分析右操作数且得到其语法树
left = self.MakeExprNode_Operate(token_tmp, left, right) ## 构造运算的语法树,结果为左子树
self.Tree_trace(left) ## 打印表达式的语法树
self.back("Expression")
return left ## 返回最终表达式的语法树
## ----------Term的递归子程序
## 项是由若干个因子以乘除号连接而成
def Term(self):
left = self.Factor()
while (self.token.type == sc.Token_Type.MUL or self.token.type == sc.Token_Type.DIV):
token_tmp = self.token.type
self.MatchToken(token_tmp)
right = self.Factor()
left = self.MakeExprNode_Operate(token_tmp, left, right)
return left
## ----------Factor的递归子程序
## 因子则可能是一个标识符或一个数字,或是一个以括号括起来的子表达式
def Factor(self):
if self.token.type == sc.Token_Type.PLUS: ## 匹配一元加运算
self.MatchToken(sc.Token_Type.PLUS)
right = self.Factor() ## 一元加:+E 转化为 E;
left = None ## 到时候如果左孩子是None则不打印
right = self.MakeExprNode_Operate(sc.Token_Type.PLUS, left, right)
elif self.token.type == sc.Token_Type.MINUS:
self.MatchToken(sc.Token_Type.MINUS)
right = self.Factor()
left = ps.ExprNode(sc.Token_Type.CONST_ID)
left.value = 0.0
right = self.MakeExprNode_Operate(sc.Token_Type.MINUS,left,right)
else:
right = self.Component() ## 匹配非终结符Component
return right
## ----------Component的递归子程序
## 幂
def Component(self): ## 右结合
left = self.Atom()
if self.token.type == sc.Token_Type.POWER: ## 幂运算
self.MatchToken(sc.Token_Type.POWER)
right = self.Component() ## 递归调用Component以实现POWER的右结合
left = self.MakeExprNode_Operate(sc.Token_Type.POWER, left, right)
return left
## ----------Atom的递归子程序
## 包括括号函数常数参数
def Atom(self):
if self.token.type == sc.Token_Type.CONST_ID:
const_value = self.token.value ## 保存当前常数值
self.MatchToken(sc.Token_Type.CONST_ID)
address = self.MakeExprNode_Const(sc.Token_Type.CONST_ID, const_value)
elif self.token.type == sc.Token_Type.T:
self.MatchToken(sc.Token_Type.T)
if len(self.Tvalue) == 1:
address = self.MakeExprNode_Const(sc.Token_Type.T,0.0) ## 暂时用0替代
else:
address = self.MakeExprNode_Const(sc.Token_Type.T, self.Tvalue)
elif self.token.type == sc.Token_Type.FUNC:
funcptr_value = self.token.funcptr ## 保存当前函数指针
self.MatchToken(sc.Token_Type.FUNC)
self.MatchToken(sc.Token_Type.L_BRACKET)
tmp = self.Expression()
address = self.MakeExprNode_Operate(sc.Token_Type.FUNC, funcptr_value, tmp)
self.MatchToken(sc.Token_Type.R_BRACKET)
self.call_match(")")
elif self.token.type == sc.Token_Type.L_BRACKET:
self.MatchToken(sc.Token_Type.L_BRACKET)
self.call_match("(")
address = self.Expression()
self.MatchToken(sc.Token_Type.R_BRACKET)
self.call_match(")")
else:
self.SyntaxError(2)
return address ## 根节点
## 生成语法树的一个节点 - 运算节点 函数节点
def MakeExprNode_Operate(self,item,left,right):
ExprPtr = ps.ExprNode(item) ## 接收记号的类别
if item == sc.Token_Type.FUNC:
ExprPtr.FuncPtr = left
ExprPtr.center = right
else:
ExprPtr.left = left
ExprPtr.right = right
ExprPtr.GetExprValue() ## 更新下自己的value
return ExprPtr
## 常数节点 变量节点
def MakeExprNode_Const(self,item,value):
ExprPtr = ps.ExprNode(item) ## 接收记号的类别
ExprPtr.value = value
return ExprPtr
Step 3 :parsermain.py - 完成I/O流
#!/usr/bin/env python
# encoding: utf-8
'''
@author: 黄龙士
@license: (C) Copyright 2019-2021,China.
@contact: iym070010@163.com
@software: xxxxxxx
@file: parsermain.py
@time: 2019/11/26 22:31
@desc:
'''
import scannerfunc as sf
import parserfunc as pf
import semanticfunc as paint
import os
file_name = 'test.txt'
scanner = sf.scanner(file_name)
##semantic = paint.semantic(scanner)
##semantic.initPaint()
##semantic.Parser()
parser = pf.Parsef(scanner)
parser.Parser()
# os.system("pause")
实现结果
- 对于测试文本(1)
FOR T FROM 0 TO 2*PI STEP PI/50 DRAW(COS(t),sin(t));的测试运行结果如下:
- 换一组测试文本(2)进行的测试运行结果如下:

<编译原理 - 函数绘图语言解释器(2)语法分析器 - python>的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- 设计模式(一)Iterator模式
Iterator模式用于在数据集合中按照顺序遍历集合.即迭代器模式. 下面来看一段实现了迭代器模式的示例程序. 这段程序的作用是将书(Book)放置到书架(BookShelf)中,并将书的名字按顺序显 ...
- vue路由安装
1.安装路由: vue ui cnpm install vue-router 2.使用,导入: 默认创建项目的时候就已经帮你写好了. import router from "vue-rout ...
- mysql全局变量和局部变量
全局变量和局部变量 在服务器启动时,会将每个全局变量初始化为其默认值(可以通过命令行或选项文件中指定的选项更改这些默认值).然后服务器还为每个连接的客户端维护一组会话变量,客户端的会话变量在连接时使用 ...
- 2018.8.3 python中的set集合及深浅拷贝
一.字符串和列表的相互转化 之前写到想把xx类型的数据转化成yy类型的数据,直接yy(xx)就可以了,但是字符串和列表的转化比较特殊,相互之间的转化要通过join()和split()来实现. 例如: ...
- DB2中的MQT优化机制详解和实践
MQT :物化查询表.是以一次查询的结果为基础 定义创建的表(实表),以量取胜(特别是在百万,千万级别的量,效果更显著),可以更快的查询到我们需要的结果.MQT有两种类型,一种是系统维护的MQT , ...
- eclipse 工具翻译插件安装
http://download.eclipse.org/technology/babel/update-site/R0.15.1/oxygen
- 转:XSS和CSRF原理及防范
原文地址:http://www.freebuf.com/articles/web/39234.html 随着Web2.0.社交网络.微博等等一系列新型的互联网产品的诞生,基于Web环境的互联网应用越来 ...
- mysql设计规范一
原文地址:http://www.jianshu.com/p/33b7b6e0a396 主键 表中每一行都应该有可以唯一标识自己的一列(或一组列). 一个顾客可以使用顾客编号列,而订单可以使用订单ID, ...
- 面试精选:JVM垃圾回收
Tips:关注公众号:松花皮蛋的黑板报,领取程序员月薪25K+秘籍,进军BAT必备! Java堆中存放着大量的Java对象实例,在垃圾收集器回收内存前,第一件事情就是确定哪些对象是“活着的”,哪些是可 ...
- Apache服务部署静态网站
Web网络服务也叫WWW(World Wide Web),一般是指能够让用户通过浏览器访问到互联网中文档等资源的服务. 目前提供WEB网络服务的程序有Apache.Nginx或IIS等等,Web网站服 ...