看李沐的 ViT 串讲
ViT
概括
论文题目:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
论文地址:https://openreview.net/pdf?id=YicbFdNTTy
作者来自 Google
亮点:
- 一些有趣的特性:
- CNN 处理不太好但是 ViT 可以处理好的例子:
- 遮挡
- 数据分布偏移
- 加入对抗性的 patch
- 排列
作者认为:
- 对于 CNN 的依赖是不必要的
- 纯 Transformer 可以做到和 CNN 媲美的结果
- Transformer 需要更少的训练资源,即使如此,也需要 2500 TPUv3 天数。这里说的少,只是跟更耗卡的模型做对比。
- 在 CV 使用 Transformer
- 难点:
- 像素点过多,而 maxlength 太短
- 于是前人提出许多思路,降低 length 长度:
- 用 ResNet 最后的特征图 \(14 \times 14=196\) 输入 transformer
- 用局部小窗口或者把图像这个二维的拆成两个一维的向量
- 没有硬件加速,模型都无法做到太大
- 大规模还是 ResNet 效果最好
- 难点:
- 于是 ViT 做法:
- 模型
- 把一张图片分成很多 patch,每一个 patch 的大小为 16 * 16
- 由于 224 / 16 = 14,因此共有 14 * 14 个 patch
- 所以 length 为 14 * 14 = 196
- 然后把每一个 patch 通过一个 linear embedding,这些再作为输入传给 Transformer
- 训练
- 用有监督的方式训练,原因是 cv 还是需要有监督的
- 有钱
- 之前有一个思路一样的,但是那个作者没钱
- 模型
- 一些结果
- 中型大小数据集上,ViT 比同等大小的 ResNet 要弱几个点,作者认为原因有
- Transformer 模型缺少一些 CNN 的归纳偏置
- 局部临近 locality
- 相邻的图片有相邻的特征
- 平移等变性 translation equivariance:
- \(f(g(x)) = g(f(x))\)
- 即函数顺序变换最后结果也一样。
- 在 CNN 中,即为相同的物体无论平移到哪里,只要遇到相同的卷积核,那么输出一样。
- 局部临近 locality
- 因此 Transformer 缺少一些 CNN 拥有的前置知识,需要自己从数据里学。
- Transformer 模型缺少一些 CNN 的归纳偏置
- 于是作者又在大规模的数据集上学习,效果很好,得到与 ResNet 相近或者更好的结果。
- 中型大小数据集上,ViT 比同等大小的 ResNet 要弱几个点,作者认为原因有
模型
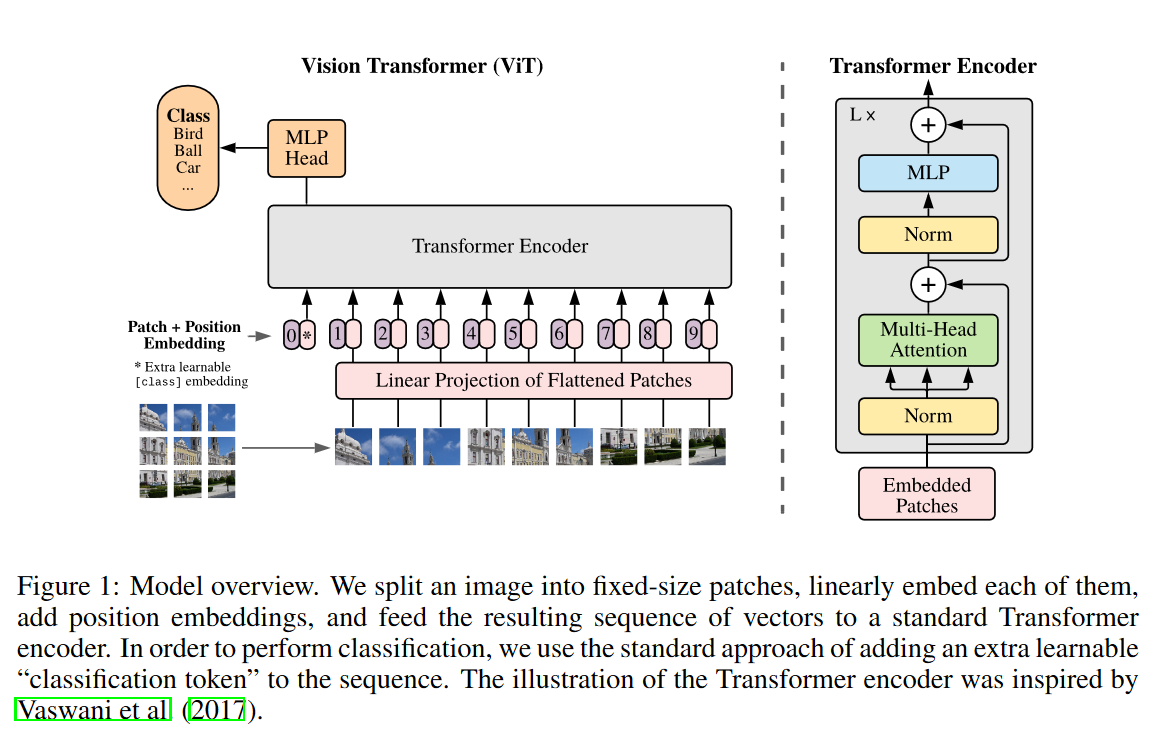
模型介绍
- 首先给定一张图,然后把这张图打成许多个 patch
- 然后每个 patch 通过一个线性的投射层得到一个特征。
- 再通过 Patch + Position Embedding 的方式,把位置编码弄上去。
- 丢进 TFM enc。
- 然后拿 [CLS] 最后对应的 representation 丢进一个 MLP Head 里。
图像的维度从 \(224 \times 224 \times 3\),变成了一个有 196 个有的 \(16 \times 16 \times 3 = 768\) 维度的 patch。
线性投射层是一个全连接层,维度是 \(D \times D = 768 \times 768\).
然后要加上 [CLS] token
最后加上位置编码信息
- 具体是把位置编码编成一张表,每一个位置对应一个向量
- 位置编码,三种效果差不多
- 作者做了 1D 的位置编码。常规方法。
- 2D 的做法:假设之前 1D 的位置编码维度是 D,2D 的位置编码横坐标有 \(\frac{D}{2}\) 的维度,纵坐标亦然,然后直接拼在一起。
- 相对位置编码:两个 patch 之间的距离可以用相对距离来表示
归纳偏置,ViT 比 CNN 少了很多归纳偏置
- CNN 中,局部性和平移等变性在模型每一层都有所体现,因此先验知识贯穿模型始终。
- 而 ViT 中,只有 MLP 这个层有局部性和平移等变性,自注意力层是全局的。
作者还做了一个混合的网络,前面 CNN,后面 TFM
预训练以及更大的图片
图片更大,patch 的个数也变了,于是位置编码也会变。
- 作者直接用了 pytorch 官方自带的 interpolate 函数做 2D 插值。
- 这个插值只能算一个临时解决方案,是 ViT 的局限性。
实验
主要对比 ResNet,ViT,hybrid
下游任务主要是分类
实验结果
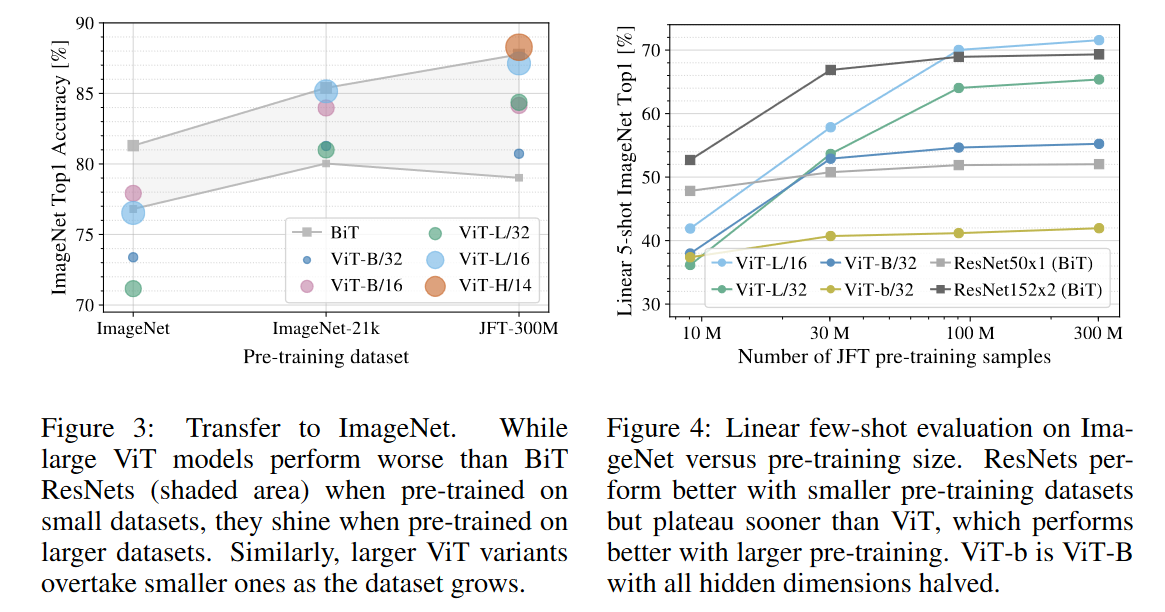 、
、
ImageNet 结果
- 中型大小数据集上,ViT 比同等大小的 ResNet 要弱几个点
- 大型数据集上,ViT 几乎全面超过 ResNet
线性 5-shot 评估
- 没有经过微调
- 结果同上
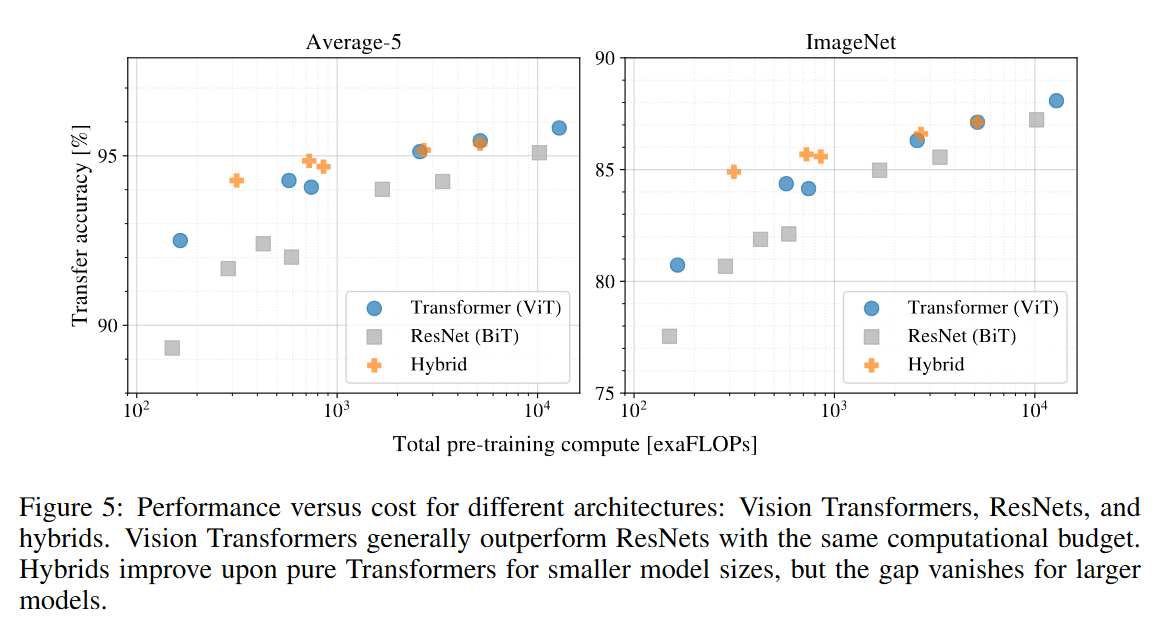
- 同等预训练计算复杂度下,ViT 比 ResNet 强
- 预训练计算次数小时,混合模型最强
- 数据越来越大时,ViT 越来越强,接近超越混合模型和 ResNet
- ViT 和 ResNet 模型似乎都没有饱和,仍然可以继续往上走
看李沐的 ViT 串讲的更多相关文章
- CLIP改进工作串讲(上)学习笔记
看了跟李沐学AI系列朱毅老师讲的CLIP改进工作串讲,这里记录一下. 1.分割 分割的任务其实跟分类很像,其实就是把图片上的分类变成像素级别上的分类,但是往往图片上能用的技术都能用到像素级别上来.所以 ...
- 视频+图文串讲:MySQL 行锁、间隙锁、Next-Key-Lock、以及实现记录存在的话就更新,如果记录不存在的话就插入如何保证并发安全
导读 Hi,大家好!我是白日梦!本文是MySQL专题的第 27 篇. 下文还是白日梦以自导自演的方式,围绕"如何实现记录存在的话就更新,如果记录不存在的话就插入."展开本话题.看看 ...
- 0607pm克隆&引用类&加载类&面向对象串讲&函数重载
克隆class Ren{ public $name; public $sex; function __construct($n,$s) { $this->name=$n; $this->s ...
- CLIP 改进工作串讲(下)学习笔记
1.图像生成 1.1CLIPasso(semantically-aware object sketching) 将物体的照片变成简笔画的形式,希望即使有最少的线条,也能识别出来物体. 问题定义,在纸上 ...
- getElementById返回的是什么?串讲HTML DOM
1. getElementById()返回的是什么? 这个函数使用的最普遍,但是你有没有深入探究下,这个函数究竟返回的是什么么?我们来一起看看. var mydivEle = document.get ...
- 集成学习-Boosting 模型深度串讲
首先强调一下,这篇文章适合有很好的基础的人 梯度下降 这里不系统讲,只介绍相关的点,便于理解后文 先放一个很早以前写的 梯度下降 实现 logistic regression 的代码 def tidu ...
- 全网最牛X的!!! MySQL两阶段提交串讲
目录 一.吹个牛 二.事务及它的特性 三.简单看下两阶段提交的流程 四.两阶段写日志用意? 五.加餐:sync_binlog = 1 问题 六.如何判断binlog和redolog是否达成了一致 七. ...
- 全网最清楚的:MySQL的insert buffer和change buffer 串讲
目录 一.前言 二.问题引入 2.1.聚簇索引 2.2.普通索引 三.change buffer存在的意义 四.再看change buffer 五.change buffer 的限制 六.change ...
- .NET 基础串讲
C#基础 .NET介绍 计算机发展史 第一代语言:机器语言 0101 第二代语言:汇编语言, 用一些简洁的英文字母.符号串来替代一个特定指令的二进制串 第三代语言:接近于数学语言或人的自然语言,同时 ...
- 技术串讲 CAS 有用
CAS,全称为Compare and Swap,即比较-替换.假设有三个操作数:内存值V.旧的预期值A.要修改的值B,当且仅当预期值A和内存值V相同时,才会将内存值修改为B并返回true,否则什么都不 ...
随机推荐
- WPF 自己封装 Skia 差量绘制控件
使用 Skia 能做到在多个不同的平台使用相同的一套 API 绘制出相同界面效果的图片,可以将图片绘制到应用程序的渲染显示里面.在 WPF 中最稳的方法就是通过 WriteableBitmap 作为承 ...
- OLAP系列之分析型数据库clickhouse集群部署(二)
一.环境准备 IP 配置 clickhouse版本 zookeeper版本 myid 192.168.12.88 Centos 7.9 4核8G 22.8.20.11 3.7.1 3 192.168. ...
- webpack调优技巧
webpack优化主要有三个方面:1.提高构建速度,2.减少打包体积,3.优化用户体验 提高构建速度: 启用多线程 thread-loader 使用thread-loader插件可以启用多线程进行构建 ...
- centos 7 开启 httpd 服务和 80 端口
centos 7 开启 httpd 服务和 80 端口 yum install -y httpd systemctl start httpd firewall-cmd --add-service=ht ...
- docker-compose 安装 mysql:5.7.31
目录 一.新建一个启动服务的目录 二.新建文件docker-compose.yml 三.新建角本文件 init-mysql.sh 四.实使化目录和配置文件 启动服务 登陆mysql 其它操作 参考文档 ...
- jeecg-boot中分页接口用自定义sql和list实现
1.controller中 @ApiOperation(value="分析仪工作状态和报警-3列-分页", notes="分析仪工作状态和报警状态-分页") @ ...
- Java面试题:@PostConstruct、init-method和afterPropertiesSet执行顺序?
在Spring框架中,@PostConstruct注解.init-method属性.以及afterPropertiesSet()方法通常用于初始化Bean的逻辑.它们都提供了在Bean创建和初始化完成 ...
- Ajax 请求总共有八种 Callback
1)onSuccess 2)onFailure 3)onUninitialized 4)onLoading 5)onLoaded 6)onInteractive 7)onComplete 8)onEx ...
- 面向K-12学生的远程访问学校计算机实验室
为了应对新冠肺炎大流行,许多学校被迫采用远程学习和混合时间制度.在家学习的学生必须使用自己的个人设备或学校提供的设备(例如 Chromebook )来完成课堂作业. 尽管许多解决方案可以帮助学生和 ...
- 比Selenium更优秀的playwright介绍与未来展望
Playwright是微软开发的,专门为满足端到端测试需求而创建的.Playwright支持包括Chromium.WebKit和Firefox在内的所有现代渲染引擎.在Windows.Linux和ma ...