《最新出炉》系列初窥篇-Python+Playwright自动化测试-58 - 文件下载
1.简介
前边几篇文章讲解完如何上传文件,既然有上传,那么就可能会有下载文件。因此宏哥就接着讲解和分享一下:自动化测试下载文件。可能有的小伙伴或者童鞋们会觉得这不是很简单吗,还用你介绍和讲解啊,不说就是访问到下载页面,然后定位到要下载的文件的下载按钮后,点击按钮就可以了。其实不是这样的,且听宏哥徐徐道来:宏哥这里的下载是去掉下载弹框的下载。我们可以看到在下载文件时会弹出一个Windows对话框,我们知道,selenium只能操作web页面,无法操作Windows对话框,在Selenium的的教程中,关于这部分的讲解就是利用浏览器的参数来禁止下载弹出窗口或者是利用工具autoIT或者键盘模拟实现的。那么Playwright是如何实现文件下载的呢?
2.下载文件的API
Playwright是一个现代化的自动化测试工具,它支持多种浏览器和操作系统,可以帮助开发人员和测试人员轻松地构建和运行可靠的端到端测试。除了测试功能之外,Playwright还提供了一些实用工具和API,其中包括文件上传和下载的功能。这些功能可以帮助用户模拟用户上传或下载文件的场景,并验证这些操作是否按预期执行。在本文中,我们将探讨如何在Playwright中实现文件上传,并提供一些示例代码和最佳实践。
比如:平台上面的上传功能,会提供一个模板(如excel,csv),此时,我们就需要下载这个模板,修改完成后,再上传,作为测试人员,我们需要验证它是否已下载到本地。playwright则可以不借助其他工具实现文件的下载。
下载文件介绍官方API的文档地址:Downloads | Playwright Python
2.1下载文件语法
# Start waiting for the download
with page.expect_download() as download_info:
# Perform the action that initiates download
page.get_by_text("Download file").click()
download = download_info.value # Wait for the download process to complete and save the downloaded file somewhere
download.save_as("/path/to/save/at/" + download.suggested_filename)
从以上语法我们知道:playwright提供了expect_download()操作来实现文件的下载操作,但是要特别的注意,当浏览器上下文关闭时,所有属于浏览器上下文的下载文件都会被删除。下载开始后会发出下载事件。下载完成后,下载路径可供使用。
3.download相关操作
3.1取消下载
取消下载。如果下载已经完成或取消,则不会失败。成功取消后,download.failure()将解析为'canceled'。
download.cancel()
3.2删除下载
删除下载的文件。如有必要,将等待下载完成。
download.delete()
3.3返回下载错误(如果有)
返回下载错误(如果有)。如有必要,将等待下载完成。
download.failure()
3.4获取下载所属页面
获取下载所属的页面。
download.page
3.5下载路径
如果下载成功,则返回下载文件的路径。如有必要,该方法将等待下载完成。该方法在远程连接时抛出。
请注意,下载的文件名是随机 GUID,使用download.suggested_filename获取建议的文件名。
download.path() #返回NoneType|pathlib.Path 类型
3.6将下载复制到用户指定路径
将下载复制到用户指定的路径。在下载仍在进行时调用此方法是安全的。如有必要,将等待下载完成。
download.save_as(path)
3.7返回此下载的建议文件名
返回此下载的建议文件名。
它通常由浏览器根据Content-Disposition响应标头或download属性计算得出。请参阅whatwg上的规范。不同的浏览器可以使用不同的逻辑来计算它。
download.suggested_filename
3.8返回下载的URL
返回下载的 url。
download.url
4.项目实战
宏哥在这个网站:https://sahitest.com/demo/saveAs.htm找到了一个在线现在文件的示例,在这里给小伙伴或者童鞋们来演示一下。
4.1代码设计
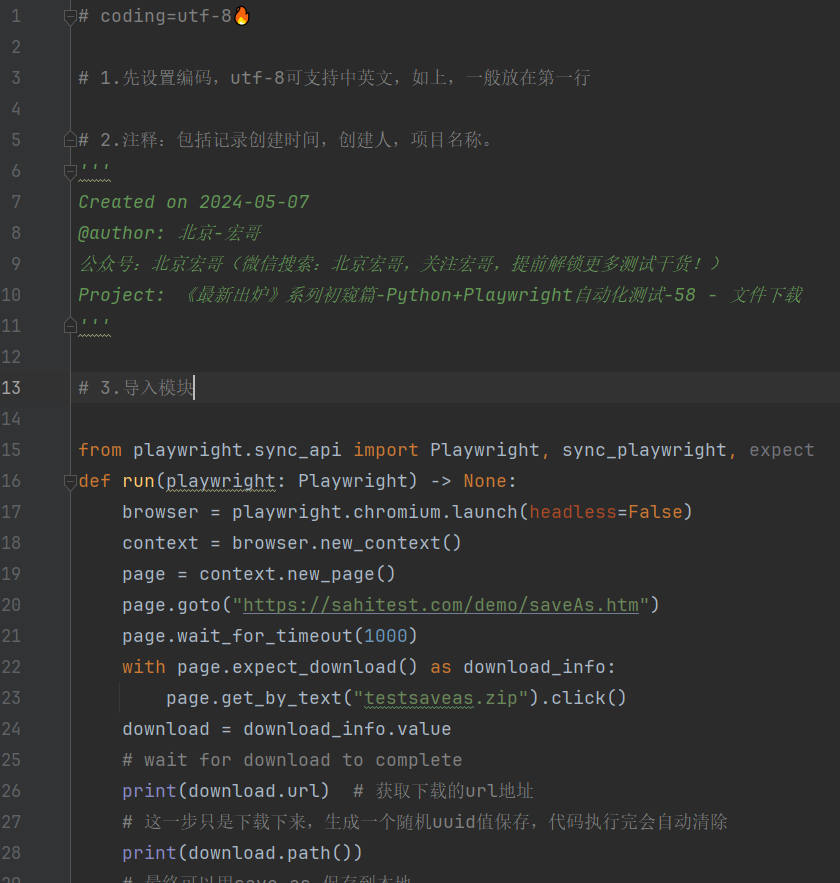
4.2参考代码
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2024-05-07
@author: 北京-宏哥
公众号:北京宏哥(微信搜索:北京宏哥,关注宏哥,提前解锁更多测试干货!)
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-58 - 文件下载
''' # 3.导入模块 from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://sahitest.com/demo/saveAs.htm")
page.wait_for_timeout(1000)
with page.expect_download() as download_info:
page.get_by_text("testsaveas.zip").click()
download = download_info.value
# wait for download to complete
print(download.url) # 获取下载的url地址
# 这一步只是下载下来,生成一个随机uuid值保存,代码执行完会自动清除
print(download.path())
name = download.suggested_filename # get suggested name
file = f"download/{name}" # file path download = download_info.value
# 最终可以用save_as 保存到本地
download.save_as(file) # download file
page.wait_for_timeout(1000)
print("browser will be close")
# page.close()
# context.close()
# page.pause()
browser.close()
with sync_playwright() as playwright:
run(playwright)
4.3运行代码
1.运行代码,右键Run'Test',就可以看到控制台输出,如下图所示:
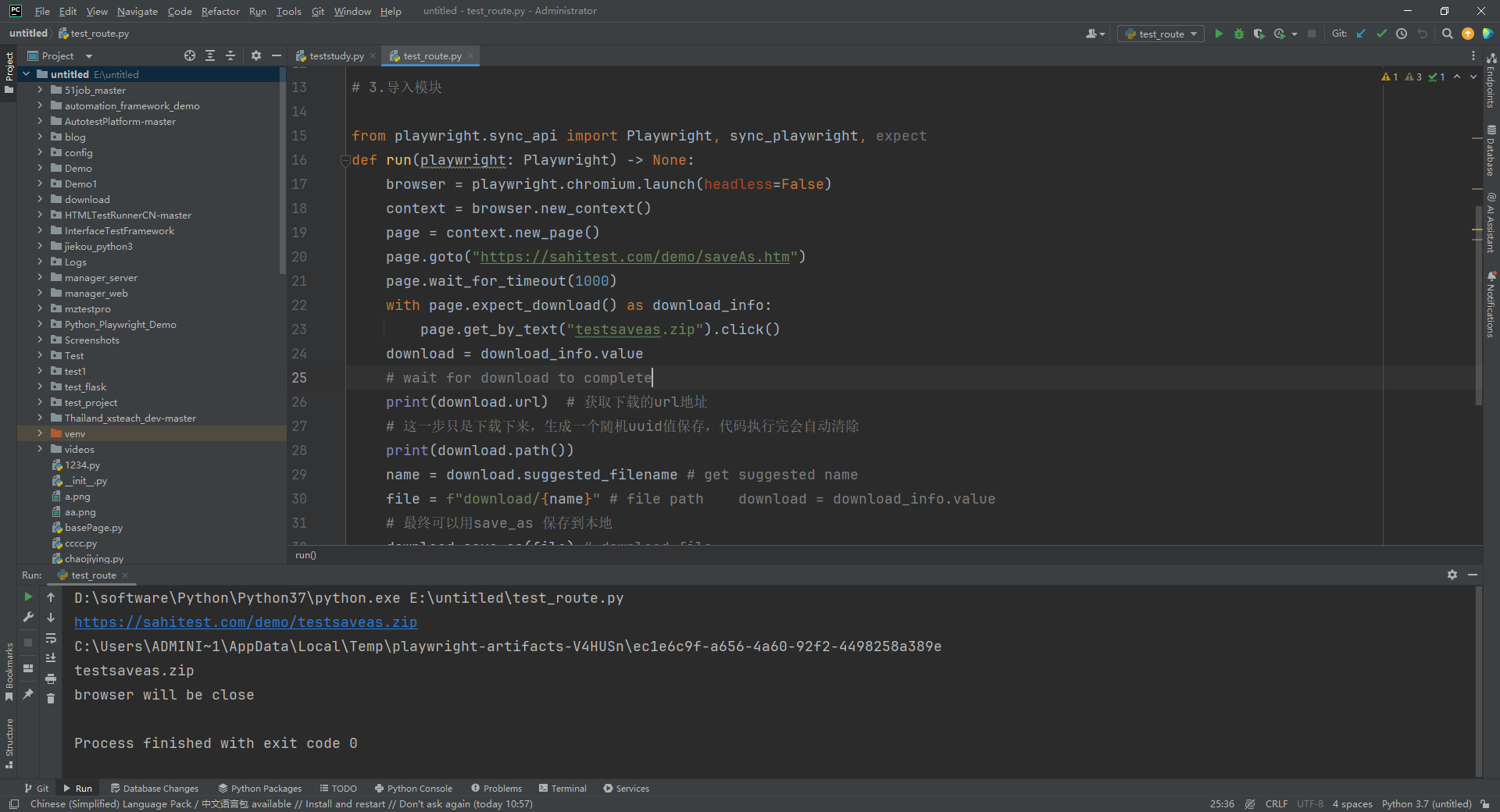
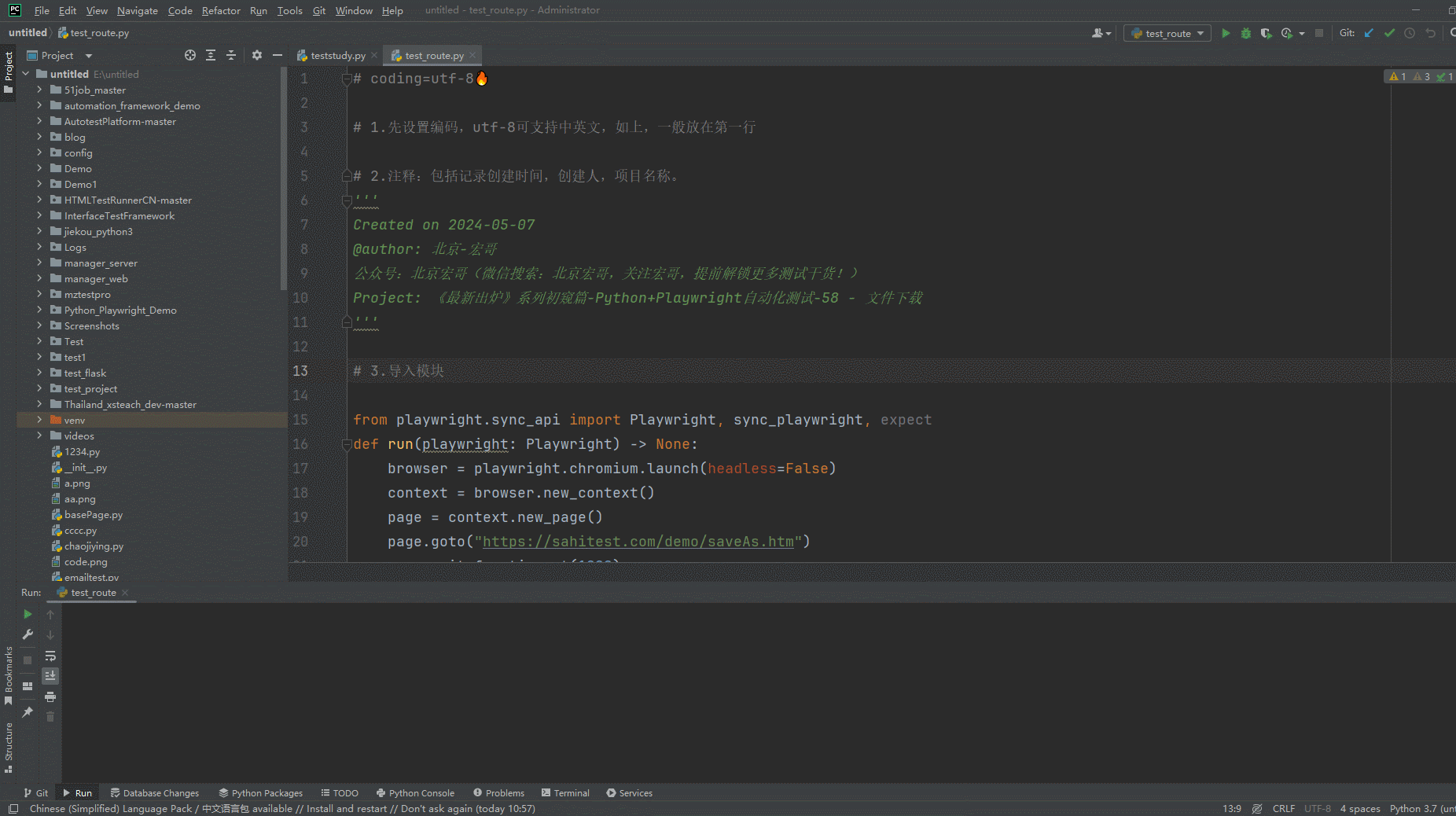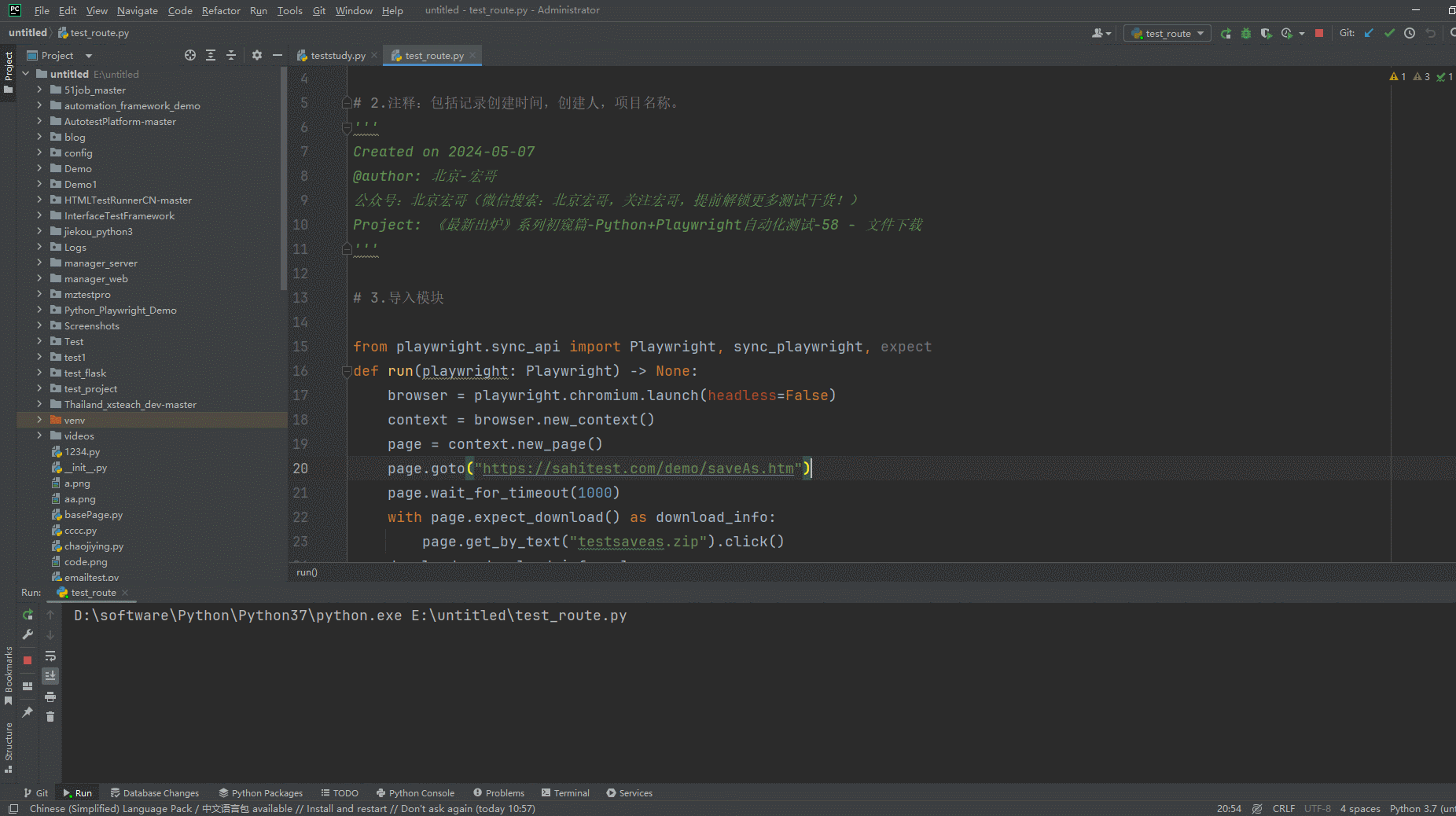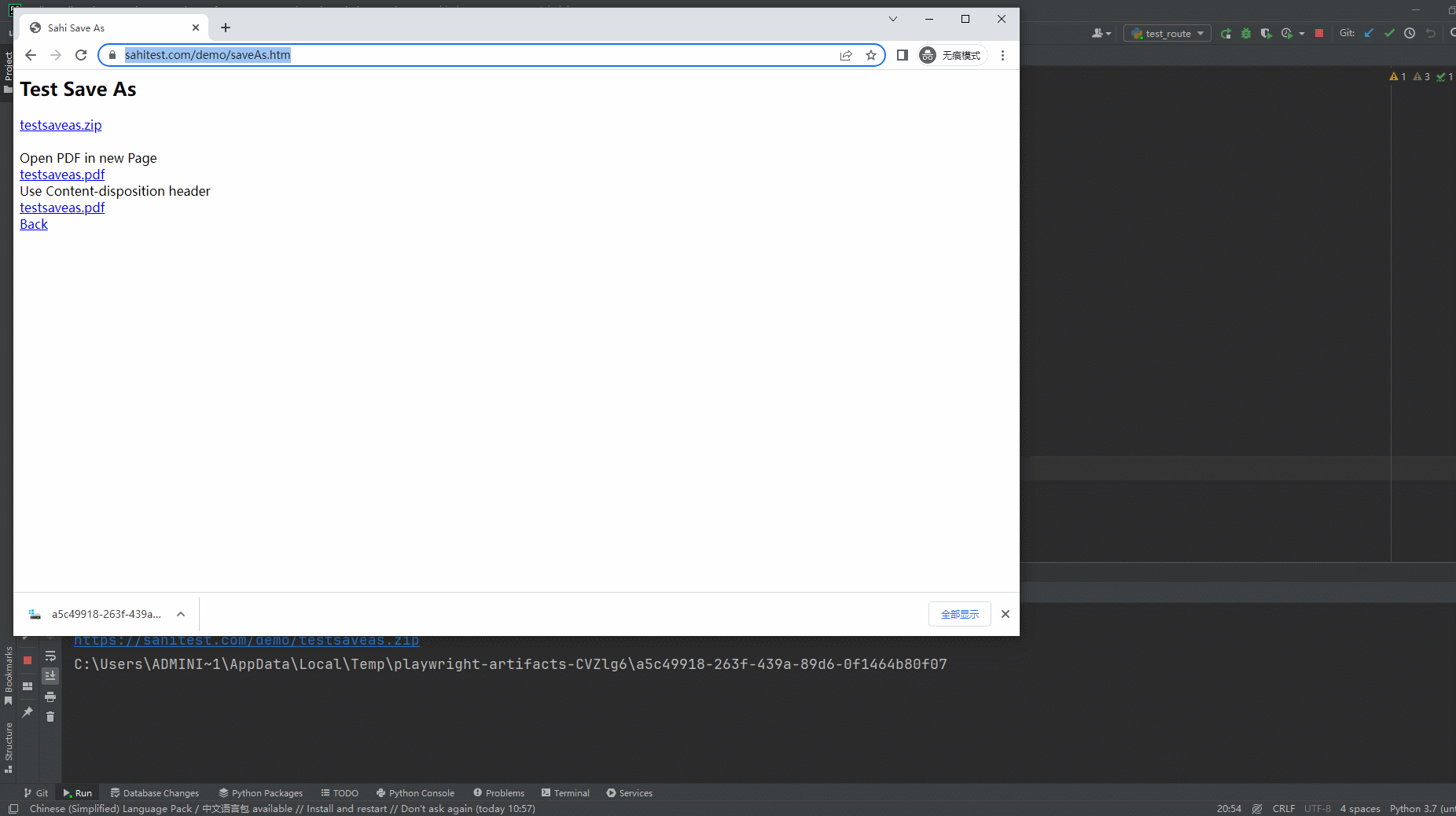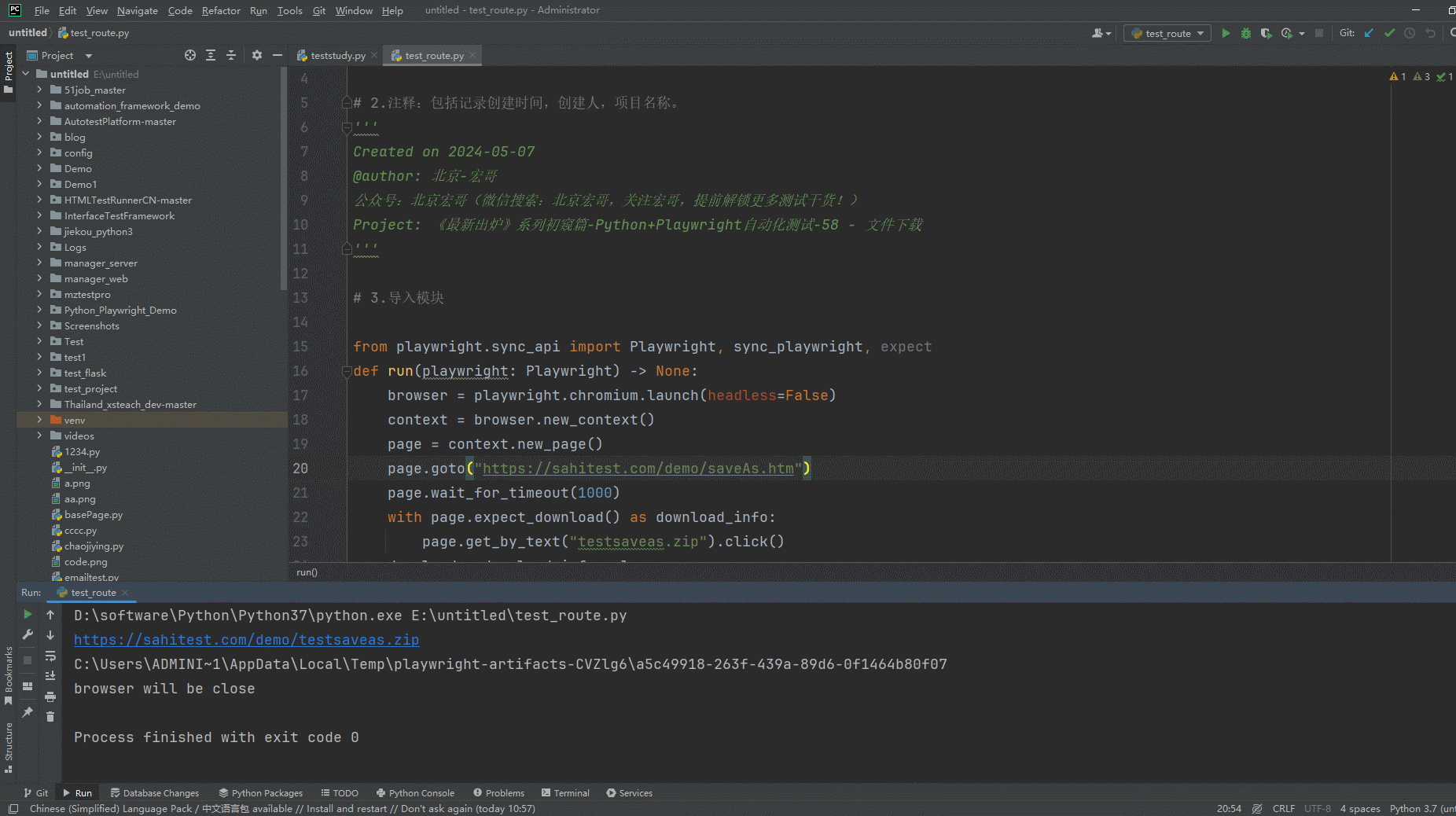
2.运行代码后电脑端的浏览器的动作(浏览器左下角下载文件)。如下图所示:
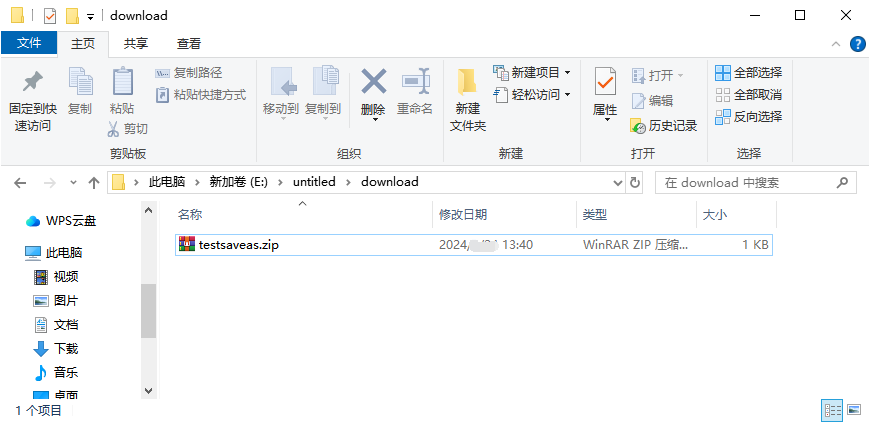
3.可以看到文件已经成功下载到宏哥的本地电脑默认的下载路径里,如下图所示:
5.小结
本文主要介绍了使用playwright实现自动化的文件下载,相比于selenium,playwright文件下载的功能更加强大,不需要借助其他工具就能够实现。宏哥这里就讲解和分享了Chrome浏览器的下载文件,其他浏览器类似,有兴趣的小伙伴或者童鞋们可以自己尝试一下。好了,时间不早了,关于playwright的下载文件先介绍讲解到这里,感谢您耐心的阅读!!!
《最新出炉》系列初窥篇-Python+Playwright自动化测试-58 - 文件下载的更多相关文章
- Flutter 即学即用系列博客——04 Flutter UI 初窥
前面三篇可以算是一个小小的里程碑. 主要是介绍了 Flutter 环境的搭建.如何创建 Flutter 项目以及如何在旧有 Android 项目引入 Flutter. 这一篇我们来学习下 Flutte ...
- Spark系列-初体验(数据准备篇)
Spark系列-初体验(数据准备篇) Spark系列-核心概念 在Spark体验开始前需要准备环境和数据,环境的准备可以自己按照Spark官方文档安装.笔者选择使用CDH集群安装,可以参考笔者之前的文 ...
- Python系列之入门篇——HDFS
Python系列之入门篇--HDFS 简介 HDFS (Hadoop Distributed File System) Hadoop分布式文件系统,具有高容错性,适合部署在廉价的机器上.Python ...
- Python系列之入门篇——MYSQL
Python系列之入门篇--MYSQL 简介 python提供了两种mysql api, 一是MySQL-python(不支持python3),二是PyMYSQL(支持python2和python3) ...
- python爬虫 scrapy2_初窥Scrapy
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- WWDC15 Session笔记 - Xcode 7 UI 测试初窥
https://onevcat.com/2015/09/ui-testing/ WWDC15 Session笔记 - Xcode 7 UI 测试初窥 Unit Test 在 iOS 开发中已经有足够多 ...
- Scrapy001-框架初窥
Scrapy001-框架初窥 @(Spider)[POSTS] 1.Scrapy简介 Scrapy是一个应用于抓取.提取.处理.存储等网站数据的框架(类似Django). 应用: 数据挖掘 信息处理 ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- scrapy2_初窥Scrapy
递归知识:oop,xpath,jsp,items,pipline等专业网络知识,初级水平并不是很scrapy,可以从简单模块自己写. 初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数 ...
- Java发送邮件初窥
一.背景 最近朋友的公司有用到这个功能,之前对这一块也不是很熟悉,就和他一起解决出现的异常的同时,也初窥一下使用Apache Common Email组件进行邮件发送. 二.Java发送邮件的注意事项 ...
随机推荐
- uniapp 返回顶部
<template> <view> <view class="btn" @tap="toTop" :style="{'d ...
- numpy cumsum()函数简介
函数原型:numpy.cumsum(a, axis=None, dtype=None, out=None) 可参考链接:https://docs.scipy.org/doc/numpy-1.10.1/ ...
- k8s配置文件管理
1.为什么要用configMap ConfigMap是一种用于存储应用所需配置信息的资源类型,用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件. 通过ConfigMap可以方便的 ...
- 一文了解Spark引擎的优势及应用场景
Spark引擎诞生的背景 Spark的发展历程可以追溯到2009年,由加州大学伯克利分校的AMPLab研究团队发起.成为Apache软件基金会的孵化项目后,于2012年发布了第一个稳定版本. 以下是S ...
- 浅拷贝、深拷贝与序列化【初级Java必需理解的概念】
浅拷贝 首先创建两个类,方便理解浅拷贝 @Data class Student implements Cloneable{ //年龄和名字是基本属性 private int age; private ...
- 开启IPV6网络
1.路由器开启IPV6支持 2.路由器关闭IPV6 DHCP服务 3.若外网无法访问则关闭路由器防火墙 或关闭系统防火墙 4.tomcat需设置地址为0.0.0.0
- ffmpeg 学习:主要结构体之间关系
背景 学习例程源码的时候,搞不清楚各结构体之间是什么含义. 解析 FFmpeg 有多个重要的结构体,解协议,解分装,解码,解封装. 解协议: http,rstp,rtmp,mms. AVIOConte ...
- Oracle常用统计
测试, 这是测消息 1.按天 select to_char(t.STARTDATE+15/24, 'YYYY-MM-DD') as 天,sum(1) as 数量from HOLIDAY tgroup ...
- mysql查看用户的过期时间
1. mysql查看用户的过期时间的方法 在MySQL中,用户的过期时间(也称为账户过期日期)是一个可选项,用于确定某个MySQL用户账户何时到期.但是,值得注意的是,并非所有的MySQL安装或版本都 ...
- ComfyUI基础篇:为什么要学 ComfyUI?
前言: 在AI生成图像领域,有许多产品,例如 Midjourney 和 Stability AI 等.为什么要学习 ComfyUI 呢?我斗胆带大家一起分析一下. 目录 1.Midjourney VS ...