[oeasy]python0132_[专业选修]utf-8_unicode_transformation_format_8_编码方式
- 上次再次输出了大红心<span style="color:red"></span>
- 找到了红心对应的编码
- 黑红梅方都对应有编码
- 原来的编码叫做 ascii️
- \u这种新的编码方式叫unicode
- 包括了 中日韩字符集等 各书写系统的字符集
- 但是有个问题
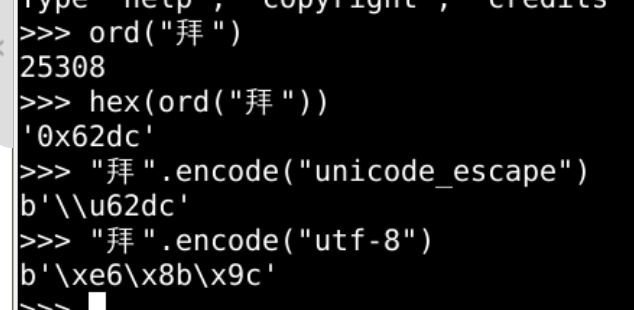
- 拜这个字
- 在字节中应该是b"\x62\xdc"两个字节
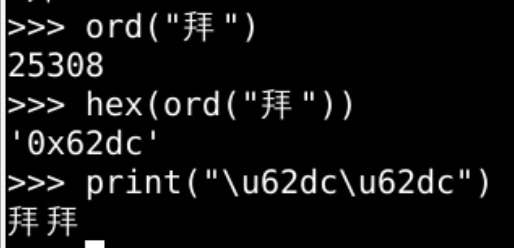
- 该如何理解b"\x62\xdc"这两个字节呢?
- 究竟是"拜"
- 还是"bÜ"呢?
- 首先进入 vi
- 然后在插入模式下写一个一
- 点击桌面上的sougo图表
- 在右下角的键盘位置选择中文
- 然后就可以输入中文了
- :%!xxd

- 一字
- 存储的状态是
- e4b880
- 三个字节
- 并不是unicode对应的
- 4e00
- 两个字节
- 我们还是得区分一下概念
- 字符集(Character-Set)是
- 指的是字符和序号之间的对应关系
- 函数是
- ord
- chr
- 字符集编码(Character-Set Encoding)
- 指的是把字符集里面的所有字符
- 放到计算机的字节里
- 函数是
- encode
- decode
- ascii、gb2312、BIG5
- 既是字符集
- 又是字符编码
- unicode如何呢?
- 一般来讲unicode是字符集
- 可以用ord和chr
- 但Unicode一般不做字符集编码

- 用字符集什么来进行字符编码呢?
- utf-8 是一种可变长度的字符编码格式
- 有的时候 1 字节 利用他省空间
- 有的时候 2 字节 利用他很平衡
- 有的时候 3 字节 利用他范围广
- 再往后 利用的更是他范围广
- 这不就两方面好处都得到了么
- utf-8 的意思是
- Unicode Transformation Format – 8-bit

- 这和 unicode 到底有什么区别呢?
- Unicode 是字符集
- Universal Coded Character Set
- 字符集:为每一个字符分配一个唯一的数字ID
- (学名为码位 / 码点 / Code Point / 字符的身份证号)
- 找到每一个字符的唯一编码

- utf-8 是 字符集编码方案
- Unicode Transformation Format – 8-bit
- 编码规则:将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)
- 而且读到字符之后
- 系统就知道这个到底是几个字节存储的
- 那这个东西怎么具体存储和操作呢?
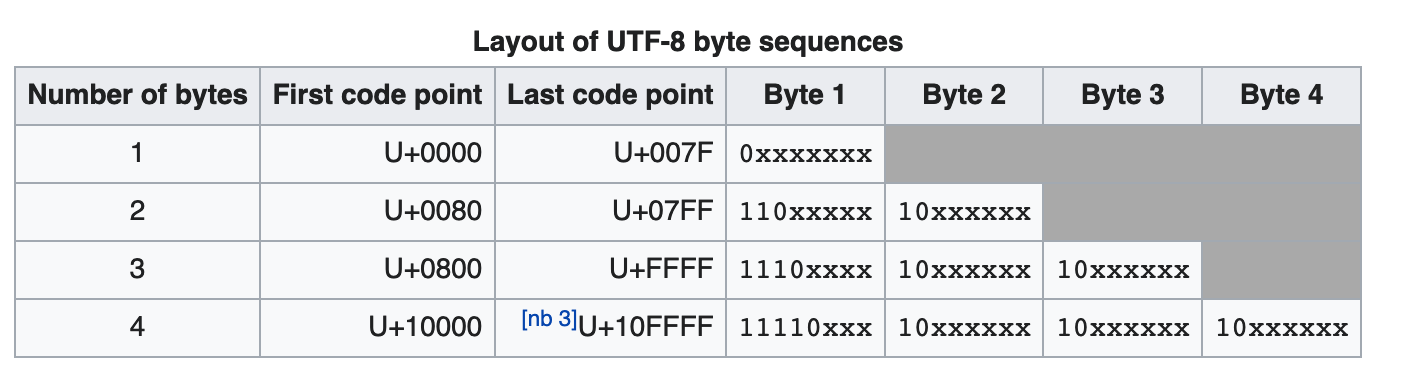
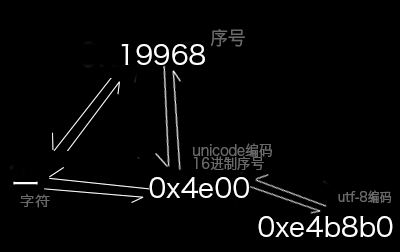
- 一(4E00) 在上图中
- 属于第三行的范围
- 从 0800-FFFF
- 所以三个字节
- 如下图套入模板

- 具体存储的状态呢?
- :%!xxd

- 说明我们用的确实是utf-8编码
- 可以解码回来吗?
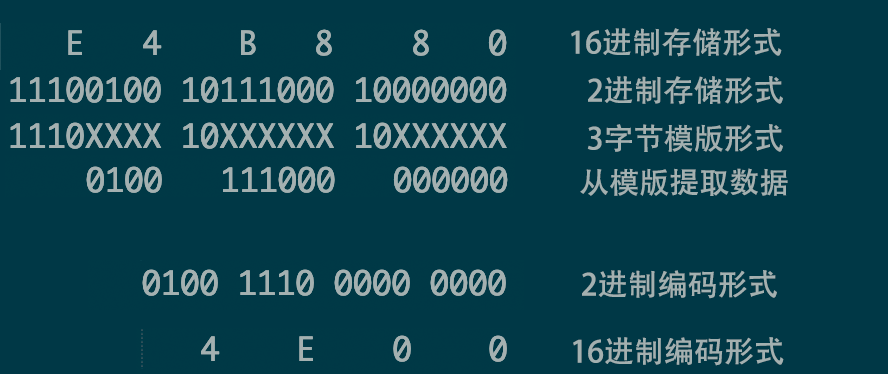
- utf-8 解码 E4B080 转化为 unicode 编码是 4E00
- 后面的 0a 是 换行LineFeed
- 或者叫做 NL(NewLine)
- 如果是两个一呢
- 两个字符相同的

- 得到两个同样的三字节utf-8存储

- 以及最后的
- 0a 依然是 换行LineFeed
- 或者叫做 NL(NewLine)
- 可以在反汇编指令层面中看到么?
- :%!xxd
- 转化为字节码状态
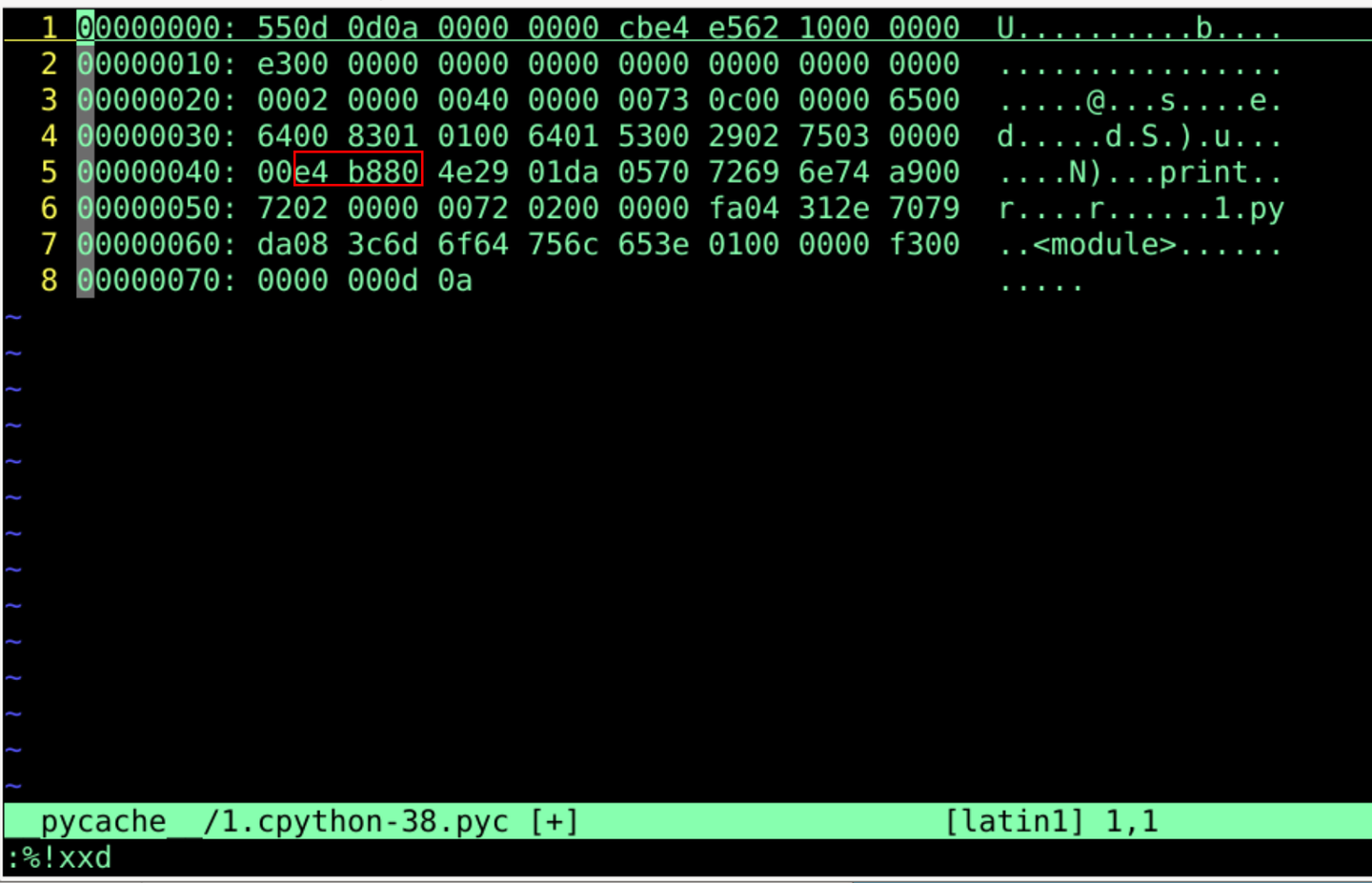
- 汉字确实可以在字节码状态中观察到
- 第一次编码
- 把汉字编码为 unicode
- 具体就是把 一 编码为 unicode 值 0x4e00这个编号
- 第二次编码
- 把 unicode 值编码为 utf-8 值
- 具体就是把 unicode 值 0x4e00 编码为 0xe4b880
- 可以落实到字节里
- 第一次解码
- 把 utf-8 解码为 unicode
- 具体就是把 utf-8 值 0xe4b880 解码为 0x4e00
- 把字节还原为序号
- 第二次解码
- 把 unicode 解码为汉字
- 具体就是把 0x4e00 解码为 一
- 找到序号对应的字符
- unicode编码是utf-8存储形式和具体汉字中间的桥梁
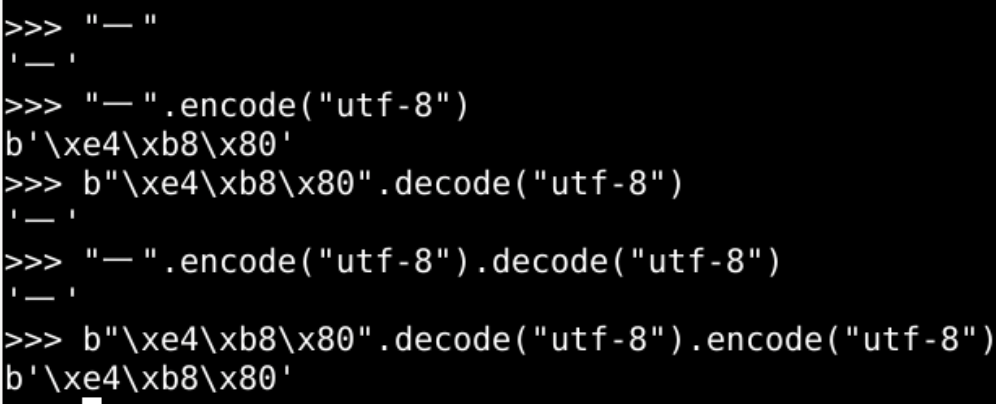
- 原始字符串
- "一"
- 查看原始字符串utf-8编码
- "一".encode("utf-8")
- 给utf-8编码解码
- b"\xe4\xb8\x80".decode("utf-8")
- 先编码再解码
- "一".encode("utf-8").decode("utf-8")
- 先解码再编码
- b"\xe4\xb8\x80".decode("utf-8").encode("utf-8")
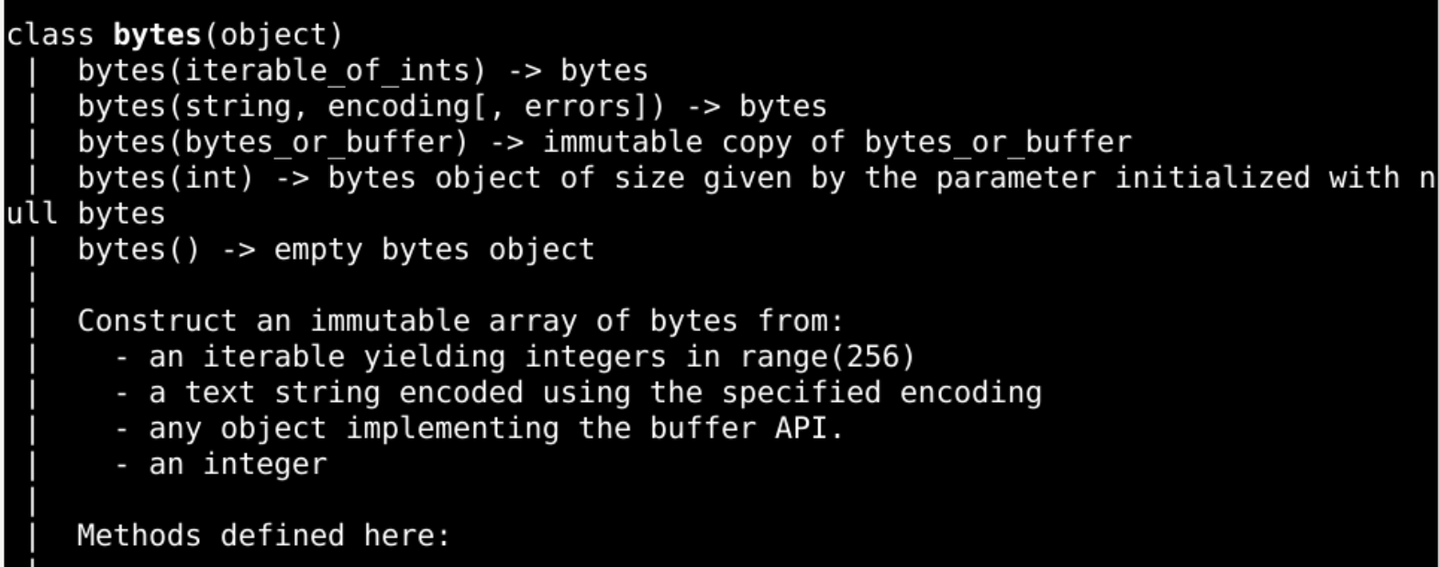
- b"\xe4\xb8\x80"是几个字节的类型呢?
- 前缀 b 表示 byte 字节
- 后面的是 bytes类型对应的 字节序列

- \x 是前缀
- b"\xe4\xb8\x80"是三个字节的序列
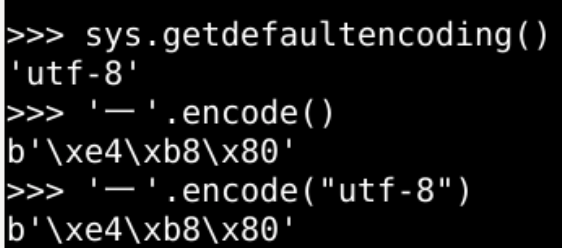
- utf-8 是系统默认的编码格式
- 一般都是这种编码格式
- 这一个字符就对应三个字节
- 可以用长度来描述字符么?
- len()函数
- 可以衡量出字符串的长度
- 也可以衡量出编码后字节序列的长度

- ascii[0,127] 字符 的长度
- 就是字节的长度
- 汉字呢?
- 字母a对应着一个字节
- 汉字一对应着三个字节
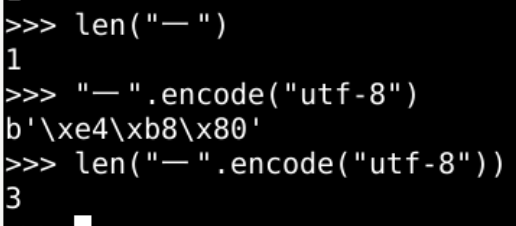
- 这个unicode的编码空间
- 究竟是怎么安排的呢?

- 所有unicode字符 被分成了4档
- ascii
- 1 字节
- 后面的字符有可能用
- 2 字节
- 3 字节
- 4 字节
- 0开头的
- ascii
- 英文字符和数字占据最大范围兼容
- 10开头的
- 2 字节
- 主要是拼音符号文字
- 拉丁
- 希腊
- 西里尔
- 等等
- 110开头的
- 3 字节范围内
- 首先是印度
- 然后是杂项
- 然后是符号
- 日文假名
- 然后是中日韩 CJK
- 11110开头的
- 4 字节
- 表情符号emoji
- 各种扩展集
- unicode字符集 开始逐渐流行
- utf-8所代表的存储编码也开始流行
- 一旦一种编码在世界上开始流行
- 他就会挤压其他的编码方式的生存空间
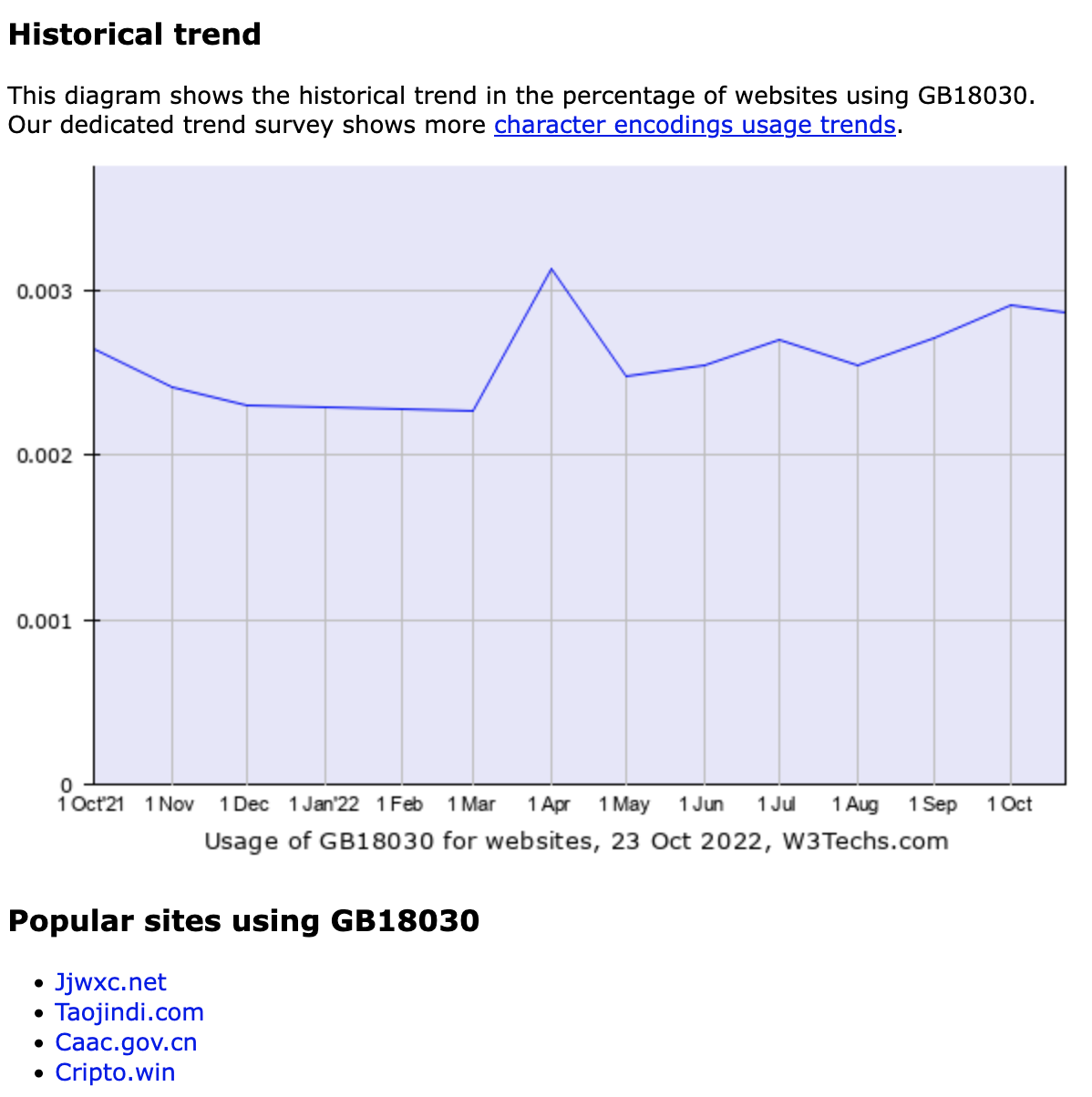
- 到了 2020 年 95%的网页使用 unicode 编码
- 到了 2021 已经达到了 97.4%
- 感觉这是全球化一体最终的编码方式
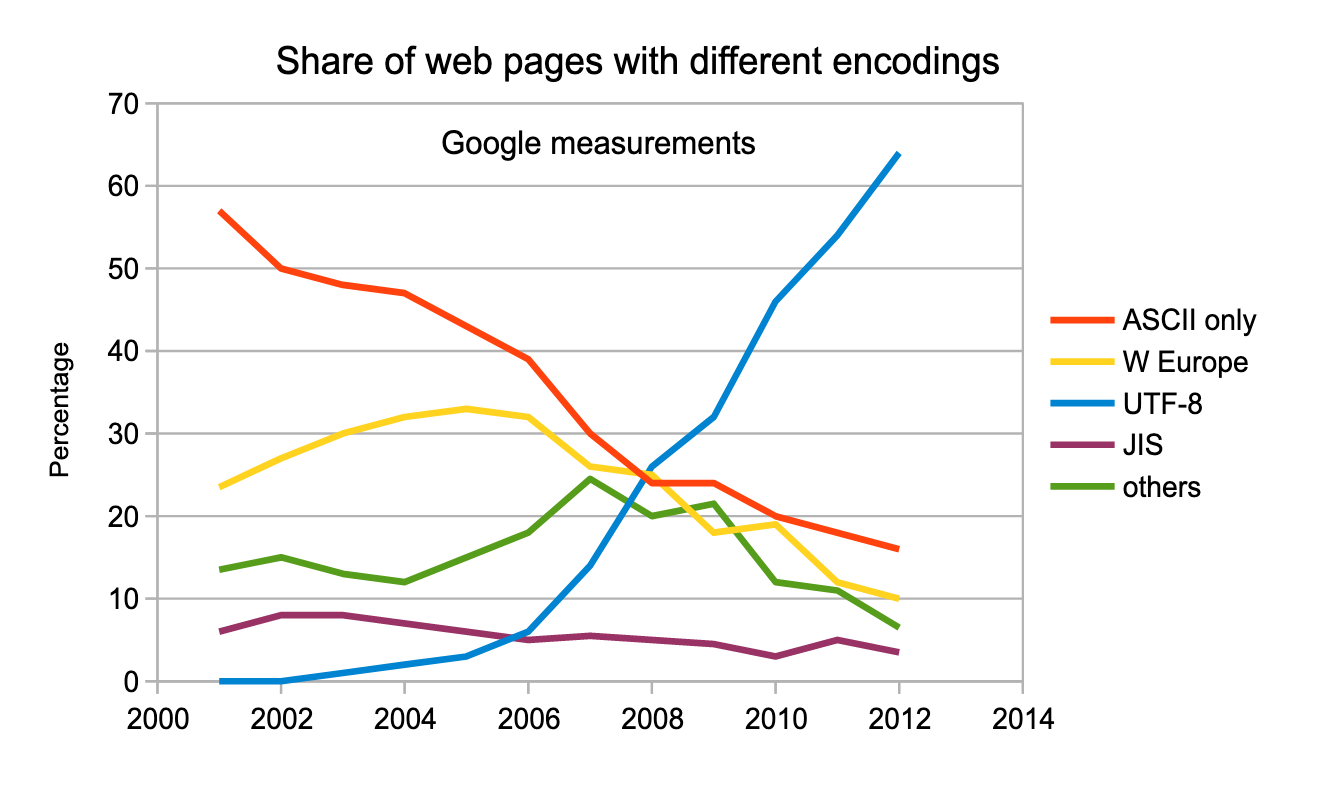

- 关于编码的世界大战
- 分久必合
- 最终的胜利者是unicode和utf-8
- 他们彼此也可以相互转化
- unicode形式
- "\u4e00"
- 把unicode编码按照utf-8编码
- "\u4e00".encode("utf-8")
- 先把unicode编码为utf-8,再解码回unicode
- "\u4e00".encode("utf-8").decode("utf-8")
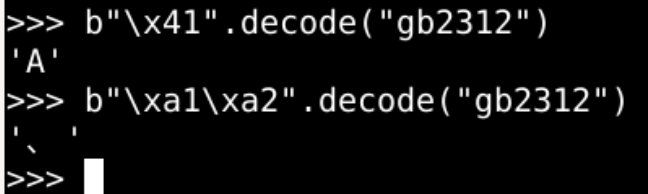
- 把utf-8编码解码回unicode编码
- b"\xe4\xb8\x80".decode("utf-8")
- 把utf-8编码先解码回unicode编码,再编码为utf-8
- b"\xe4\xb8\x80".decode("utf-8").encode("utf-8")
- 曾经掌握了 ascii 码和 ascii 字符的转化方法
- 也要掌握 unicode 和 utf-8 双向转化的方法
- gb2312系列又如何了呢?
- 80年的gb2312
- 95年的gbk
- 05年有了gb18030

- 全称:国家标准 GB 18030-2005《信息技术中文编码字符集》
- 是中华人民共和国现时最新的内码字集
- 是 GB 18030-2000《信息技术信息交换用汉字编码字符集基本集的扩充》的修订版
- 有多少字符了呢?
- GB 18030 与 GB 2312-1980 和 GBK 兼容
- 共收录汉字<span style="font-size:80px">70244</span>个
- 与 utf-8 相同
- 采用多字节编码
- 每个字可以由 1 个、2 个或 4 个字节组成
- 编码空间庞大
- utf-8标准海纳百川
- GB18030用的人很少
- 但始终依然存在
- GB18030有什么作用呢?
- 有的时候还会遇到 gb18030 编码的文档
- 用 utf-8编码方式
- 打开 gb18030编码 的文件
- 就会乱码
- 这个时候可以在 vim 中使用命令
- :edit ++enc=gb18030
- 可以解决问题

- gb18030 用的人少
- 有用的人少的好处
- 如果只会用utf-8解码
- 那么gb18030本身就构成了加密系统
- 只有懂汉语并且懂编码才能看懂
- 不懂的话只能见到乱码
- 想要自动翻译都不行
- 这次了解了unicode 和 utf-8
- unicode是字符集
- utf-8是一种可变长度的编码方式
- utf-8是实现unicode的存储和传输的现实的方式
- unicode让字符范围得到了极大扩展
- unicode到底还扩展出什么好玩的字符呢?
- 我们下次再说!
[oeasy]python0132_[专业选修]utf-8_unicode_transformation_format_8_编码方式的更多相关文章
- UNICODE UTF编码方式解析
先明确几个概念 基础概念部分 1.字符编码方式CEF(Character Encoding Form) 对符号进行编码,便于处理与显示 常用的编码方式有 GB2312(汉字国标码 2字节) ASCII ...
- Unicode 字符集与它的编码方式
正式内容開始之前,我们先来了解一个基本概念,编码字符集. 编码字符集:编码字符集是一个字符集,它为每个字符分配一个唯一数字.Unicode 标准的核心是一个编码字符集,字母"A"的 ...
- java中的字符编码方式
1. 问题由来 面试的时候被问到了各种编码方式的区别,结果一脸懵逼,这个地方集中学习一下. 2. 几种字符编码的方式 1. ASCII码 我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符 ...
- 刨根究底字符编码之十——Unicode字符集的字符编码方式CEF
Unicode字符集的字符编码方式CEF 一.字符编码方式CEF的选择 1. 由于Unicode字符集非常大,有些字符的编号(码点值)需要两个或两个以上字节来表示,而要对这样的编号进行编码,也必须使用 ...
- 刨根究底字符编码之十一——UTF-8编码方式与字节序标记
UTF-8编码方式与字节序标记 一.UTF-8编码方式 1. 接下来将分别介绍Unicode字符集的三种编码方式:UTF-8.UTF-16.UTF-32.这里先介绍应用最为广泛的UTF-8. 为满足基 ...
- 计算机编码方式详解(Unicode、UTF-8、UTF-16、ASCII)
整理这篇文章的动机是两个问题: 问题一: 使用Windows记事本的"另存为",可以在GBK.Unicode.Unicode big endian和UTF-8这几种编码方式间相互转 ...
- unicode,gbk,utfF-8字符编码方式的区别
一.编码历史与区别 一直对字符的各种编码方式懵懵懂懂,什么ANSI UNICODE UTF-8 GB2312 GBK DBCS UCS……是不是看的很晕,假如您细细的阅读本文你一定可以清晰的理解他们. ...
- (转载)UTF-8和GBK的编码方式的部分知识:重要
GBK的文字编码是双字节来表示的,即不论中.英文字符均使用双字节来表示,只不过为区分中文,将其最高位都定成1. 至于UTF-8编码则是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节) ...
- Java编码方式再学
一直以来对编码方式对了解不是很深入.建议读下这几篇博文 学点编码知识又不会死:Unicode的流言终结者和编码大揭秘 编码研究笔记 这几篇博文上回答了内心存在的一些问题,这些问题可能也是大家经常遇到的 ...
- 各种字符编码方式详解及由来(ANSI,UNICODE,UTF-8,GB2312,GBK)
一直对字符的各种编码方式懵懵懂懂,什么ANSI UNICODE UTF-8 GB2312 GBK DBCS UCS……是不是看的很晕,假如您细细的阅读本文你一定可以清晰的理解他们.Let's go! ...
随机推荐
- mysql命令最新
查看授权 mysql> select user,host from mysql.user; +--------+------------+ | user | host | +--------+- ...
- Spring 对 Junit4,Junit5 的支持上的运用
1. Spring 对 Junit4,Junit5 的支持上的运用 @ 目录 1. Spring 对 Junit4,Junit5 的支持上的运用 每博一文案 2. Spring对Junit4 的支持 ...
- linux wget命令的重要用法:下载文件并保存,后台下载
Linux wget命令是一个下载文件的工具,它用在命令行下. #从网络下载一个文件并保存在当前目录 [root@node5 ~]# wget http://cn.wordpress.org/word ...
- 20220314线上panic总结
panic: runtime error: invalid memory address or nil pointer dereference [signal SIGSEGV: segmentatio ...
- Android OpenMAX(一)漫谈
在开始正式的学习前,我们先来聊一聊Android音视频开发中的一些问题.感受与想法.(有一点要事先说明,我的问题与答案.想法并不一定正确,请读者带着审慎的思考来阅读,后续的文章也是一样,希望读者边阅读 ...
- mp4封装格式与MPEG4Extractor
首先来看mp4的封装格式,mp4数据都被放在一个个的箱子当中,也就是box,box的字节序为网络字节序,也就是大端存储,box由header和body组成,header指明box的大小和类型,body ...
- 从零开始写 Docker(十六)---容器网络实现(上):为容器插上”网线”
本文为从零开始写 Docker 系列第十六篇,利用 linux 下的 Veth.Bridge.iptables 等等相关技术,构建容器网络模型,为容器插上"网线". 完整代码见:h ...
- 莫烦tensorflow学习记录 (3)建造我们第一个神经网络
另一个学习文档http://doc.codingdict.com/tensorflow/tfdoc/tutorials/overview.html 定义 add_layer() https://mof ...
- 深入理解Vue 3:计算属性与侦听器的艺术
title: 深入理解Vue 3:计算属性与侦听器的艺术 date: 2024/5/30 下午3:53:47 updated: 2024/5/30 下午3:53:47 categories: 前端开发 ...
- Java交换map的key和value值
在Java中,我们都知道直接交换Map的key和value是不被允许的,因为Map的接口设计是基于key-value对的,其中key是唯一的,并且是不可变的(在HashMap等常见的实现中,虽然key ...