10 Self-Attention(自注意力机制)
注意力机制
看一个物体的时候,我们倾向于一些重点,把我们的焦点放到更重要的信息上
第一眼看到这个图,不会说把所有的信息全部看完

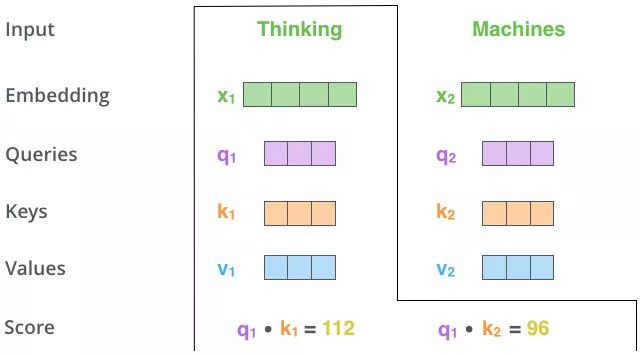
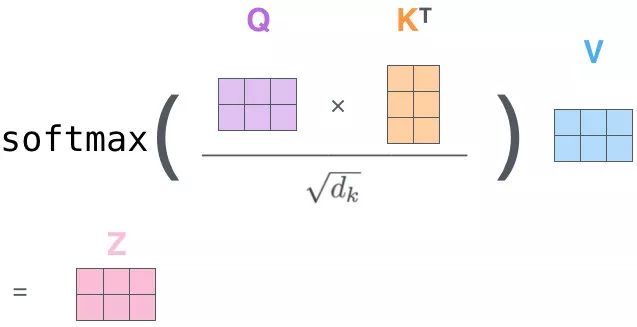
QK 相乘求相似度,做一个 scale(未来做 softmax 的时候避免出现极端情况)
然后做 Softmax 得到概率
新的向量表示了K 和 V(K==V),然后这种表示还暗含了 Q 的信息(于 Q 而言,K 里面重要的信息),也就是说,挑出了 K 里面的关键点
自-注意力机制(Self-Attention)(向量)
Self-Attention 的关键点再于,不仅仅是 K\(\approx\)V\(\approx\)Q 来源于同一个 X,这三者是同源的
通过 X 找到 X 里面的关键点
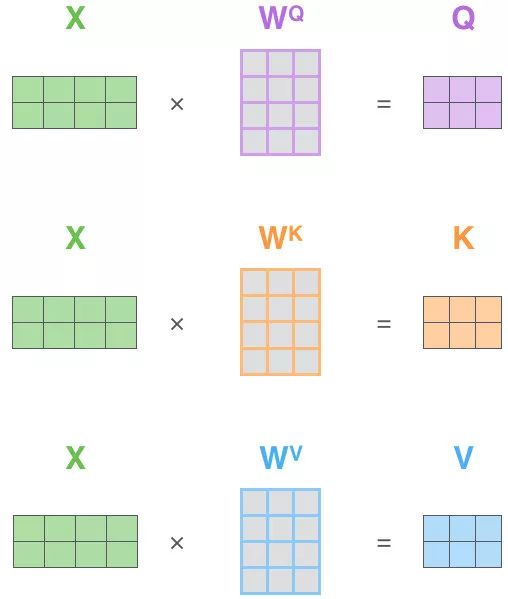
并不是 K=V=Q=X,而是通过三个参数 \(W_Q,W_K,W_V\)
接下来的步骤和注意力机制一模一样
Q、K、V的获取
Matmul:
Scale+Softmax:
Matmul:



\(z_1\)表示的就是 thinking 的新的向量表示
对于 thinking,初始词向量为\(x_1\)
现在我通过 thinking machines 这句话去查询这句话里的每一个单词和 thinking 之间的相似度
新的\(z_1\)依然是 thinking 的词向量表示,只不过这个词向量的表示蕴含了 thinking machines 这句话对于 thinking 而言哪个更重要的信息
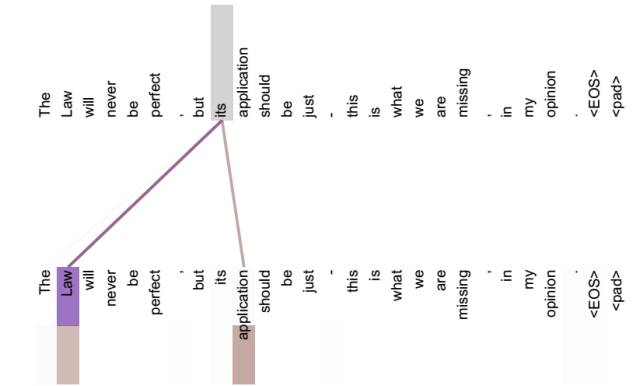
不做注意力,its 的词向量就是单纯的 its,没有任何附加信息
也就是说 its 有 law 这层意思,而通过自注意力机制得到新的 its 的词向量,则会包含一定的 laws 和 application 的信息
自注意力机制(矩阵)

10 Self-Attention(自注意力机制)的更多相关文章
- NLP之基于Seq2Seq和注意力机制的句子翻译
Seq2Seq(Attention) @ 目录 Seq2Seq(Attention) 1.理论 1.1 机器翻译 1.1.1 模型输出结果处理 1.1.2 BLEU得分 1.2 注意力模型 1.2.1 ...
- NLP之基于Bi-LSTM和注意力机制的文本情感分类
Bi-LSTM(Attention) @ 目录 Bi-LSTM(Attention) 1.理论 1.1 文本分类和预测(翻译) 1.2 注意力模型 1.2.1 Attention模型 1.2.2 Bi ...
- 基于Seq2Seq和注意力机制的句子翻译
Seq2Seq(Attention) 目录 Seq2Seq(Attention) 1.理论 1.1 机器翻译 1.1.1 模型输出结果处理 1.1.2 BLEU得分 1.2 注意力模型 1.2.1 A ...
- (转)注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 本文转自:http://www.cnblogs.com/robert-dlut/p/5952032.html 近年来,深度 ...
- 注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了 ...
- 注意力机制(Attention Mechanism)应用——自然语言处理(NLP)
近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了最近神经网络研究的一个热点,下面是一些基于attention机制的神经网络在 ...
- 【注意力机制】Attention Augmented Convolutional Networks
注意力机制之Attention Augmented Convolutional Networks 原始链接:https://www.yuque.com/lart/papers/aaconv 核心内容 ...
- 深度学习之注意力机制(Attention Mechanism)和Seq2Seq
这篇文章整理有关注意力机制(Attention Mechanism )的知识,主要涉及以下几点内容: 1.注意力机制是为了解决什么问题而提出来的? 2.软性注意力机制的数学原理: 3.软性注意力机制. ...
- 关于注意力机制(《Attention is all you need》)
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列.(https://kexue.fm/archives/4765) 第一个思路是RNN层,递归进行,但是RNN无法很好地 ...
- 注意力机制---Attention、local Attention、self Attention、Hierarchical attention
一.编码-解码架构 目的:解决语音识别.机器翻译.知识问答等输出输入序列长度不相等的任务. C是输入的一个表达(representation),包含了输入序列的有效信息. 它可能是一个向量,也可能是一 ...
随机推荐
- 【SpringBoot】10 Web开发 Part1 静态资源
使用SpringBoot创建工程的方式: 1.在IDEA集成的Boot官网选项中点选可能需要的框架环境即可 2.SpringBoot已经设置好了这些场景,只需要配置文件中指定少量配置就可以运行起来 3 ...
- 使用智能AI在农业养殖业中风险预警的应用
一.前言 之前写过一篇<物联网浏览器(IoTBrowser)-使用深度学习开发防浸水远程报警>文章,主要介绍了通过摄像头麦克风监测浸水报警器有无异常,当出现异常后进行紧急报警并推送微信通知 ...
- 从零到一:用Go语言构建你的第一个Web服务
使用Go语言从零开始搭建一个Web服务,包括环境搭建.路由处理.中间件使用.JSON和表单数据处理等关键步骤,提供丰富的代码示例. 关注TechLead,复旦博士,分享云服务领域全维度开发技术.拥有1 ...
- Vue-购物车实战
computed 计算属性 正则 css部分 [v-cloak] { display : none ; } table{ border : lpx solid #e9e9e9 ; border- co ...
- 项目管理工具Maven的简单配置示例
Maven是一个强大的项目管理工具,它基于项目对象模型(POM)的概念,通过一小段描述信息来管理项目的构建.报告和文档.以下是一些关于Maven的具体例子,涵盖了项目配置.依赖管理.插件使用等方面: ...
- MFC对话框程序:实现程序启动画面
MFC对话框程序:实现程序启动画面 对于比较大的程序,在启动的时候都会显示一个画面,以告诉用户程序正在加载,或者显示一些关于软件的信息,如Visual C++,Word, PhotoShop等.那么对 ...
- AtCoder Beginner Contest 314
AtCoder Beginner Contest 314 - AtCoder A - 3.14 (atcoder.jp) 题目提供了100位,所以直接用字符串输出 #include <bits/ ...
- OpenHarmony编译构建系统详解,从零搭建windows下开发环境,巨方便!
自从OpenHarmony更新了dev-tool,就可以在windows下构建鸿蒙(轻量型)系统了,这对于进行MCU开发的朋友们,学习鸿蒙OS会友好许多!我们可以更快的构建出系统,方便快速学习和验证. ...
- 使用 reloadNuxtApp 强制刷新 Nuxt 应用
title: 使用 reloadNuxtApp 强制刷新 Nuxt 应用 date: 2024/8/22 updated: 2024/8/22 author: cmdragon excerpt: re ...
- Windows PE 安装
Microsoft 官方提供的 Windows PE 默认只有命令行界面.如果想要使用带有桌面环境的 Windows PE,推荐使用微 PE . 下载并安装 Windows ADK 和 WinPE 加 ...