纯分享:将MySql的建表DDL转为PostgreSql的DDL
背景
现在信创是搞得如火如荼,在这个浪潮下,数据库也是从之前熟悉的Mysql换到了某国产数据库。
该数据库我倒是想吐槽吐槽,它是基于Postgre 9.x的基础上改的,至于改了啥,我也没去详细了解,当初的数据库POC测试和后续的选型没太参与,但对于我一个开发人员的角度来说,它给我带来的不便主要是客户端GUI工具这块。
我们读写数据库,程序这块还好,CURD代码用到的语法,基本是sql标准兼容的那些,没用多少mysql的特殊语法,所以这块没啥感觉。
客户端GUI这块,pg的客户端软件目前知道几个:
- navicat,公司没采购正版,用不了,替代软件是开源的dbeaver
- pgAdmin,pg官方客户端,结果不知道这个国产化过程中改了啥,用pgAdmin连上就各种报错,放弃
- dbeaver,这个倒是可以用,就是我感觉操作太麻烦了,太繁琐
基于以上原因,一直用dbeaver来着,之前两次把mysql项目的表结构换成pg,一次是写了个乱七八糟的代码来做建表语句转换,一次是用dbeaver建的,太繁琐了。
这次又来了个项目,我就换回了我熟悉的sqlyog(一款mysql客户端),几下就把表建好了(mysql版本),然后写了个工具代码,来把mysql的DDL转换成pg的。
下面简单介绍下这个转换代码。
技术选型
以前写这种代码,都是各种字符串操作(正则、匹配、替换等等),反正代码最终是非常难以维护。这次就先去网上查了下,发现有人有类似需求,还发了文章:https://zhuanlan.zhihu.com/p/314069540
我发现其中利用了一个java库,JSqlParser(https://github.com/JSQLParser/JSqlParser),我在网上也找了下其他的库,java这块没有更好的了,遥遥领先。
其官方说明:
JSqlParser parses an SQL statement and translate it into a hierarchy of Java classes.
它支持解析sql语句这种非结构化文本为结构化数据,比如,针对如下的一个建库sql:
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
可以解析为如下的类及属性:
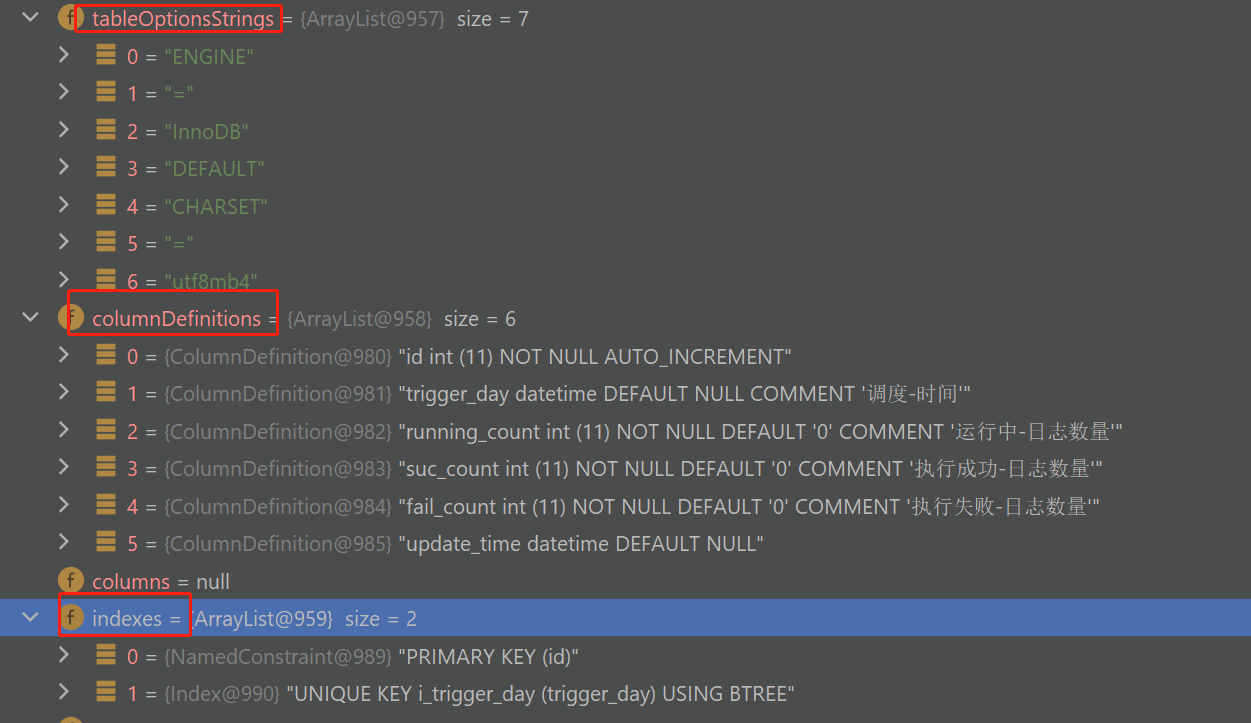
如上就包含了索引、列定义、建表选项等等。
我们接下来就只需要根据这些字段,获取数据并转换为对应的Postgre的语法即可。
转换效果
源码:https://github.com/cctvckl/convertMysqlDdlToPostgre.git
对于以上的类,给大家看看转换效果:
CREATE TABLE xxl_job_log_report (
id serial PRIMARY KEY,
trigger_day timestamp NULL,
running_count int NOT NULL DEFAULT '0',
suc_count int NOT NULL DEFAULT '0',
fail_count int NOT NULL DEFAULT '0',
update_time timestamp NULL
);
COMMENT ON COLUMN xxl_job_log_report.trigger_day IS '调度-时间';
COMMENT ON COLUMN xxl_job_log_report.running_count IS '运行中-日志数量';
COMMENT ON COLUMN xxl_job_log_report.suc_count IS '执行成功-日志数量';
COMMENT ON COLUMN xxl_job_log_report.fail_count IS '执行失败-日志数量';
这个sql,基本都满足我们的要求了。
当然,我这个工具类,还没特别完善,对于索引这块,只支持了主键索引,其他索引类型,后面空了我补一下。
支持的DDL类型,目前仅限于create table和drop table,目前能满足我个人需求了,反正mysqldump那些导出来的sql结构基本就这样。
暂不支持DML,如insert那些。
代码要点
整体逻辑
Statements statements = CCJSqlParserUtil.parseStatements(sqlContent);
for (Statement statement : statements.getStatements()) {
if (statement instanceof CreateTable) {
String sql = ProcessSingleCreateTable.process((CreateTable) statement);
totalSql.append(sql).append("\n");
} else if (statement instanceof Drop) {
String sql = ProcessSingleDropTable.process((Drop) statement);
totalSql.append(sql).append("\n");
} else {
throw new UnsupportedOperationException();
}
}
如上,CCJSqlParserUtil 是 JSqlParser 的工具类,将我们的sql转换为一个一个的statement(即sql语句),我这边利用instanceof检查属于哪种DDL,再调用对应的代码进行处理,设计模式也懒得弄,if else写起来多快。
数据准备:表注释
List<String> tableOptionsStrings = createTable.getTableOptionsStrings();
String tableCommentSql = null;
int commentIndex = tableOptionsStrings.indexOf("COMMENT");
if (commentIndex != -1) {
tableCommentSql = String.format("COMMENT ON TABLE %s IS %s;", tableFullyQualifiedName,tableOptionsStrings.get(commentIndex + 2));
}
解析出的表的相关属性,全都被放在一个list中,我们根据COMMENT关键字定位索引,然后找后两个,即是表注释具体值。
数据准备:列注释
由于我是直接在作者基础上改的,https://zhuanlan.zhihu.com/p/314069540,所以也是像他那样,复用了其代码,提取每一列的注释,逻辑也是根据COMMENT关键字找到index,然后index+1就是注释值。
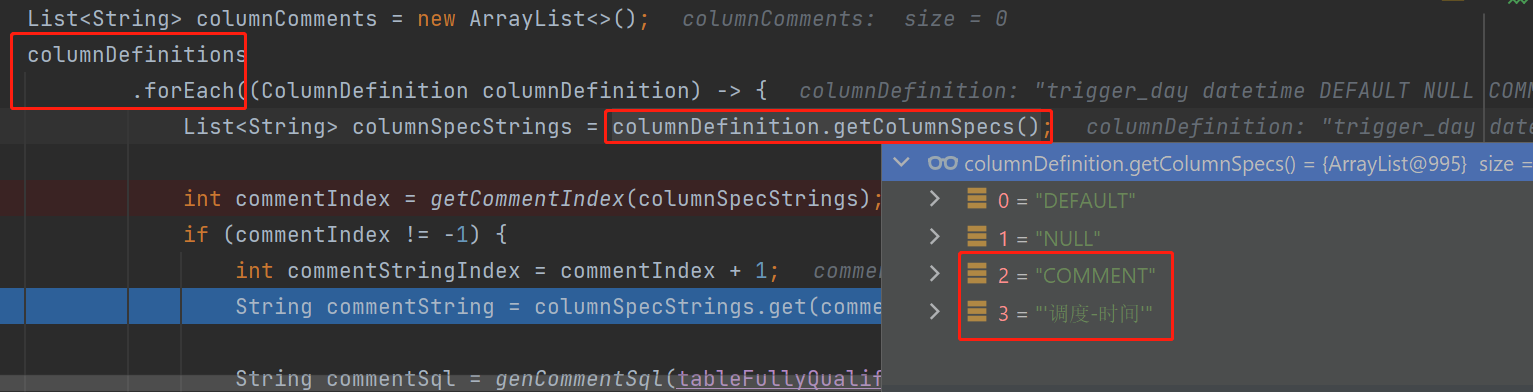
提取出来后,格式化为pg语法:
String.format("COMMENT ON COLUMN %s.%s IS %s;", table, column, commentValue);
数据准备:提取主键
Index primaryKey = createTable.getIndexes().stream()
.filter((Index index) -> Objects.equals("PRIMARY KEY", index.getType()))
.findFirst().orElse(null);
组装sql:建表第一行
String createTableFirstLine = String.format("CREATE TABLE %s (", tableFullyQualifiedName);
组装sql:主键列
这里涉及数据类型转换,如mysql中的bigint,在pg中,使用bigserial即可:
String dataType = primaryKeyColumnDefinition.getColDataType().getDataType();
if (Objects.equals("bigint", dataType)) {
primaryKeyType = "bigserial";
} else if (Objects.equals("int", dataType)) {
primaryKeyType = "serial";
} else if (Objects.equals("varchar", dataType)){
primaryKeyType = primaryKeyColumnDefinition.getColDataType().toString();
}
String sql = String.format("%s %s PRIMARY KEY", primaryKeyColumnName, primaryKeyType);
组装sql:其他列
这部分有几块:
类型转换,mysql的类型,转换为pg的,我这边定义了一个map,大致如下:
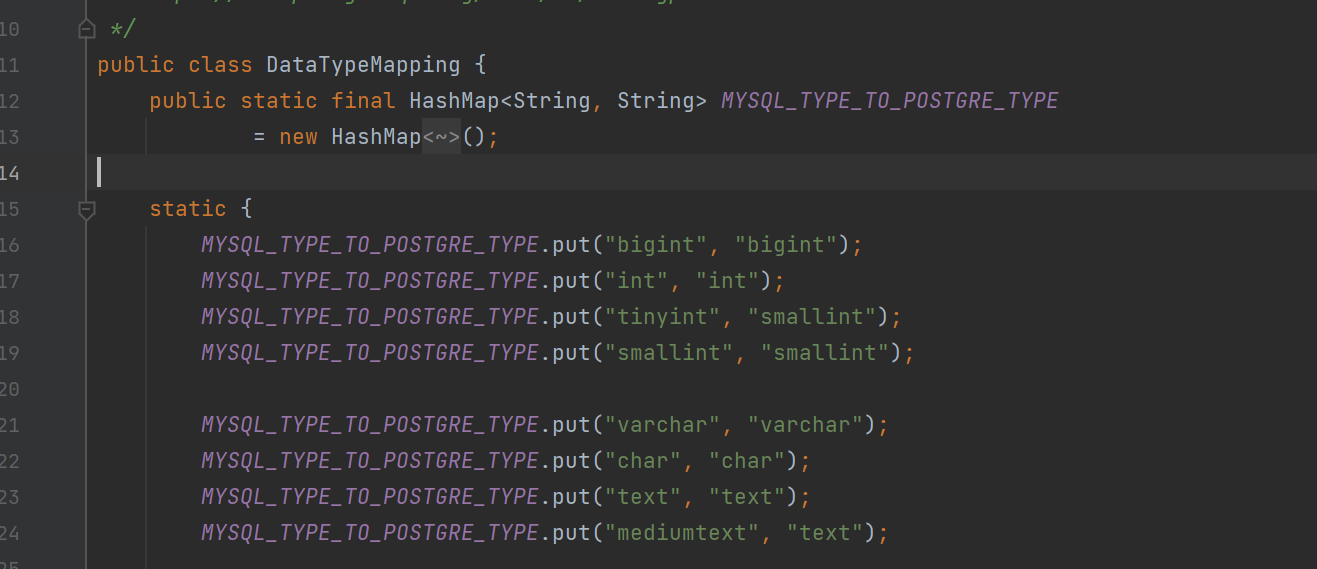
以上仅是部分,具体查看代码
默认值处理
这块也比较麻烦,比如mysql中的函数这种,如CURRENT_TIMESTAMP这种默认值,转换为pg中的对应函数,我大概定义了几个,满足当前需要:
static {
MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("NULL", "NULL");
MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("CURRENT_TIMESTAMP", "CURRENT_TIMESTAMP");
MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("CURRENT_DATE", "CURRENT_DATE");
MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("CURRENT_TIME", "CURRENT_TIME");
}
删除pg不支持的mysql语法
// postgre不支持unsigned
sourceSpec = sourceSpec.replaceAll("unsigned", "");
// postgre不支持ON UPDATE CURRENT_TIMESTAMP
sourceSpec = sourceSpec.replaceAll("ON UPDATE CURRENT_TIMESTAMP", "");
打印完整的pg语法sql
这块就不说了,上面效果展示部分有。
生成出来的sql,会在项目根路径下的target.sql文件中
总结
生成的target.sql文件,在idea中打开,如果有语法错误会飘红,如果大家有java开发能力,直接debug改就行,不行就提issue,我看到了空了就改;
我之前拿着有语法错误的sql就去dbeaver执行了,报错也不详细,看得一脸懵,idea还是厉害。
参考资料
mysql官方的迁移指南,里面包含了pg的各种类型对应到mysql的什么类型
https://dev.mysql.com/doc/workbench/en/wb-migration-database-postgresql-typemapping.html
mysql中的各种类型查阅
https://dev.mysql.com/doc/refman/8.0/en/data-types.html
pg中的各种类型查阅,我看得低版本的,谁让我们的信创数据库是基于pg 9版本的呢
https://www.postgresql.org/docs/11/datatype-numeric.html#DATATYPE-INT
这边直接贴一下吧,方便大家看:
| Pg Source Type | Taret MySQL Type | Comment |
| INT | INT | |
| SMALLINT | SMALLINT | |
| BIGINT | BIGINT | |
| SERIAL | INT | Sets AUTO_INCREMENT in its table definition. |
| SMALLSERIAL | SMALLINT | Sets AUTO_INCREMENT in its table definition. |
| BIGSERIAL | BIGINT | Sets AUTO_INCREMENT in its table definition. |
| BIT | BIT | |
| BOOLEAN | TINYINT(1) | |
| REAL | FLOAT | |
| DOUBLE PRECISION | DOUBLE | |
| NUMERIC | DECIMAL | |
| DECIMAL | DECIMAL | |
| MONEY | DECIMAL(19,2) | |
| CHAR | CHAR/LONGTEXT | |
| NATIONAL CHARACTER | CHAR/LONGTEXT | |
| VARCHAR | VARCHAR/MEDIUMTEXT/LONGTEXT | |
| NATIONAL CHARACTER VARYING | VARCHAR/MEDIUMTEXT/LONGTEXT | |
| DATE | DATE | |
| TIME | TIME | |
| TIMESTAMP | DATETIME | |
| INTERVAL | TIME | |
| BYTEA | LONGBLOB | |
| TEXT | LONGTEXT | |
| CIDR | VARCHAR(43) | |
| INET | VARCHAR(43) | |
| MACADDR | VARCHAR(17) | |
| UUID | VARCHAR(36) | |
| XML | LONGTEXT | |
| JSON | LONGTEXT | |
| TSVECTOR | LONGTEXT | |
| TSQUERY | LONGTEXT | |
| ARRAY | LONGTEXT | |
| POINT | POINT | |
| LINE | LINESTRING | |
| LSEG | LINESTRING | |
| BOX | POLYGON | |
| PATH | LINESTRING | |
| POLYGON | POLYGON | |
| CIRCLE | POLYGON | |
| TXID_SNAPSHOT | VARCHAR |
纯分享:将MySql的建表DDL转为PostgreSql的DDL的更多相关文章
- mysql workbench 建表时 PK,NN,UQ,BIN,UN,ZF,AI解释
mysql workbench 建表时 - PK: primary key (column is part of a pk) 主键 - NN: not null (column is nullable ...
- 分享一个MySQL分库分表备份脚本(原)
分享一个MySQL分库备份脚本(原) 开发思路: 1.路径:规定备份到什么位置,把路径(先判断是否存在,不存在创建一个目录)先定义好,我的路径:/mysql/backup,每个备份用压缩提升效率,带上 ...
- mysql怎样建表及mysql优化
1.符合数据库三范式 2.字段选择合适的数据类型 3.注意表之间的联系,一对多,多对多,一对一 4.拆分表,把不常用的字段单独成表. 5.建立索引,哪些字段建立索引?建立索引的原则?最左前缀原则,wh ...
- MySQL常见建表选项以约束
一.CREATE TABLE 选项 1.在定义列的时候,指定列选项 1)DEFAULT <literal>:定义列的默认值 当插入一个新行到表中并且没有给该列明确赋值时,如果定义了列的默认 ...
- mysql数据库建表的基本规范
1.创建表的时候必须指定主键,并且主键建立后最好不要再有数据修改的需求 mysql从5.5版本开始默认使用innodb引擎,innodb表是聚簇索引表,也就是说数据通过主键聚集( 主键下存储该行的数据 ...
- MySQL常见建表选项及约束
阅读目录---MySQL常见的建表选项及约束: 1.create table选项 1.指定列选项:default.comment 2.指定表选项:engine.auto_increment.comme ...
- Mysql的建表规范与注意事项
一. 表设计规范 库名.表名.字段名必须使用小写字母,“_”分割. 库名.表名.字段名必须不超过12个字符. 库名.表名.字段名见名知意,建议使用名词而不是动词. 建议使用InnoDB存储引擎. 存储 ...
- Mysql 批量建表存储过程
最近项目中用到了使用存储过程批量建表的功能,记录下来: USE db_test_3; drop procedure if EXISTS `createTablesWithIndex`; create ...
- 50个SQL语句(MySQL版) 建表 插入数据
本学期正在学习数据库,前段时间老师让我们做一下50个经典SQL语句,当时做的比较快,有一些也是百度的,自我感觉理解的不是很透彻. 所以从本篇随笔开始,我将进行50个经典SQL语句的复盘,加深理解. 答 ...
- 【mysql】mysql 常用建表语句
[1]建立员工档案表要求字段:员工员工编号,员工姓名,性别,工资,email,入职时间,部门.[2]合理选择数据类型及字段修饰符,要求有NOT NULL,auto_increment, primary ...
随机推荐
- adb查看端口号,杀进程
1.先查看端口号占用的进程 netstat -ano | findstr 8000 2.在杀掉我们查出的进程15812 3.再次查看8000端口号的进程
- Electron桌面应用开发基础
Electron桌面应用开发 Electron技术架构 地址:快速入门 | Electron Chromium 支持最新特性的浏览器 Node.js Javascript运行时,可实现文件读写 Nat ...
- 聊聊Flink必知必会(二)
Checkpoint与Barrier Flink是一个有状态的流处理框架,因此需要对状态做持久化,Flink定期保存状态数据到存储空间上,故障发生后从之前的备份中恢复,这个过程被称为Checkpoin ...
- Mybatis Generator 配置详解
因原版观感不佳,搬运至此. 作者:Jimin 链接:https://www.imooc.com/article/21444 来源:慕课网 <?xml version="1.0" ...
- vulnhub-xxe靶场通关(xxe漏洞续)
vulnhub-xxe靶场通关(xxe漏洞续) 下面简单介绍一个关于xxe漏洞的一个靶场,靶场来源:https://www.vulnhub.com 这里面有很多的靶场. 靶场环境需要自己下载:http ...
- Dlang 与 C 语言交互(二)
Dlang 与 C 语言交互(二) 随着需求不断增加,发现好像需要更多的东西了.在官网上找不到资料,四处拼凑才有了本文的分享. 上一文(DLang 与 C 语言交互(一) - jeefy - 博客园) ...
- 教你学会使用Angular 应用里的 export declare const X Y
摘要:export declare const X: Y语法用于在Angular应用程序中声明一个具有指定类型的常量变量,并将其导出,以便在其他文件中使用. 本文分享自华为云社区<关于 Angu ...
- 谁在以太坊区块链上循环交易?TuGraph+Kafka的0元流图解决方案
都在说数据已经成为新时代的生产资料. 但随着大数据和人工智能等技术的发展,即便人们都知道数据的价值日益凸显,却无法凭借一己之力获取和分析如此大规模的数据. 要想富,先修路.要想利用新时代的数据致富,也 ...
- 采集douban
# -*- coding: utf-8 -*-"""Created on Thu Oct 31 16:14:02 2019 @author: DELL"&quo ...
- Oracle分组取最大值
需求 该SQL是一个子SQL,需要查询出某个人所有过往履历中职务最高的 SELECT a."EMP_ID",a."CADRE_LEVEL" FROM (SELE ...