分布式机器学习(Parameter Server)
分布式机器学习中,参数服务器(Parameter Server)用于管理和共享模型参数,其基本思想是将模型参数存储在一个或多个中央服务器上,并通过网络将这些参数共享给参与训练的各个计算节点。每个计算节点可以从参数服务器中获取当前模型参数,并将计算结果返回给参数服务器进行更新。
为了保持模型一致性,通常采用下列两种方法:
- 将模型参数保存在一个集中的节点上,当一个计算节点要进行模型训练时,可从集中节点获取参数,进行模型训练,然后将更新后的模型推送回集中节点。由于所有计算节点都从同一个集中节点获取参数,因此可以保证模型一致性。
- 每个计算节点都保存模型参数的副本,因此要定期强制同步模型副本,每个计算节点使用自己的训练数据分区来训练本地模型副本。在每个训练迭代后,由于使用不同的输入数据进行训练,存储在不同计算节点上的模型副本可能会有所不同。因此,每一次训练迭代后插入一个全局同步的步骤,这将对不同计算节点上的参数进行平均,以便以完全分布式的方式保证模型的一致性,即All-Reduce范式
PS架构
在该架构中,包含两个角色:parameter server和worker
parameter server将被视为master节点在Master/Worker架构,而worker将充当计算节点负责模型训练
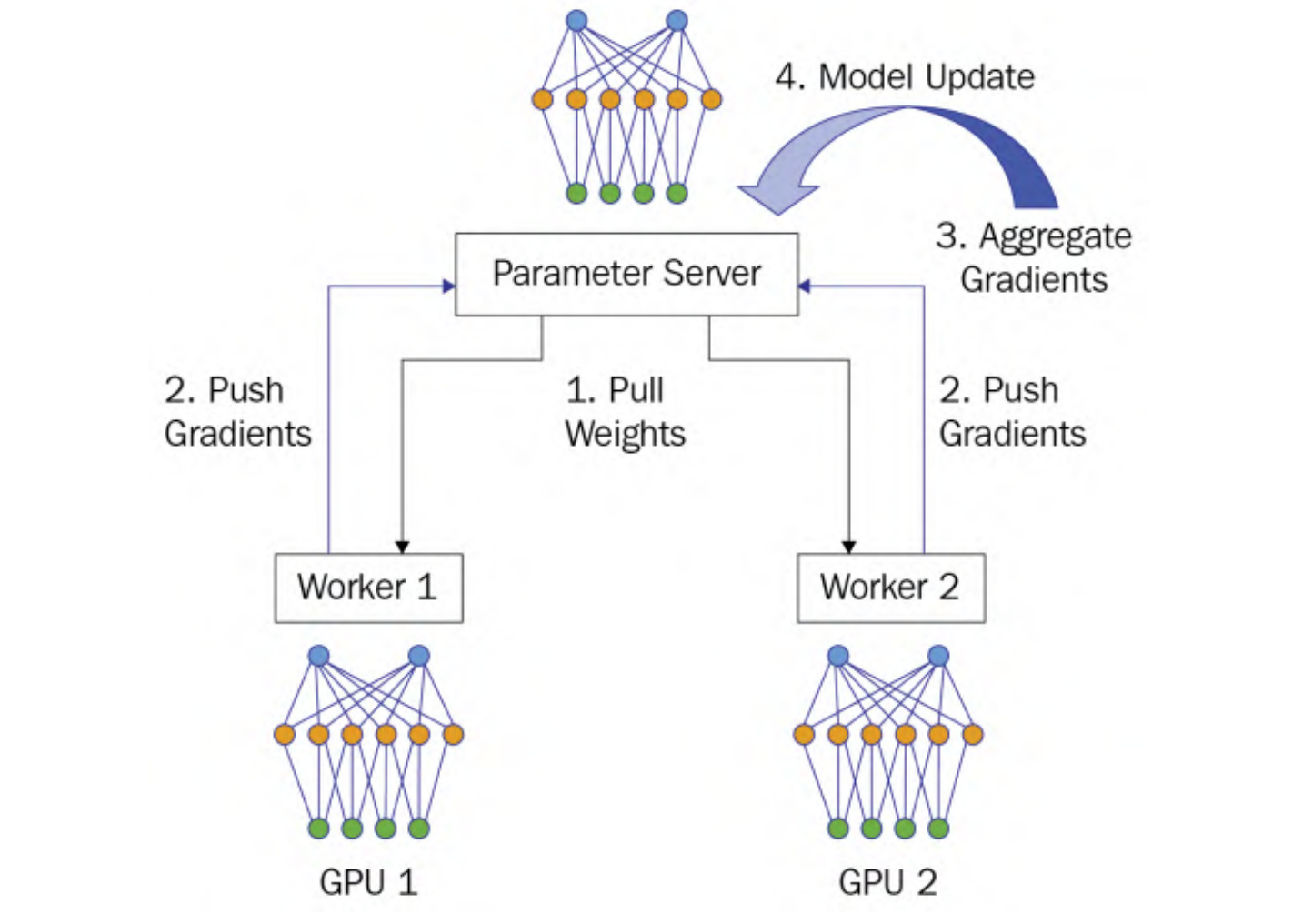
整个系统的工作流程分为4个阶段:
- Pull Weights: 所有worker从参数服务器获取权重参数
- Push Gradients: 每一个worker使用本地的训练数据训练本地模型,生成本地梯度,之后将梯度上传参数服务器
- Aggregate Gradients:收集到所有计算节点发送的梯度后,对梯度进行求和
- Model Update:计算出累加梯度,参数服务器使用这个累加梯度来更新位于集中服务器上的模型参数
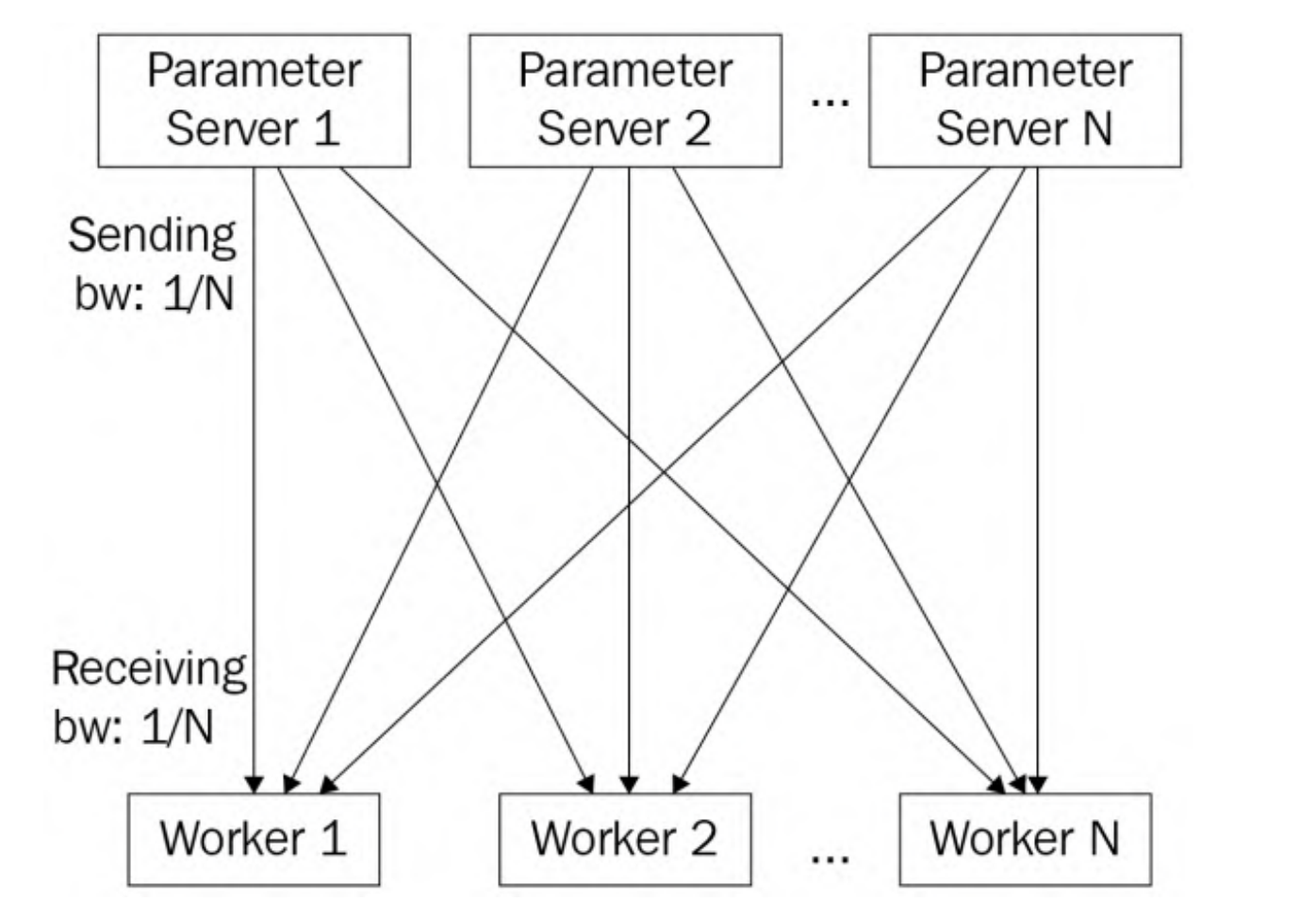
可见,上述的Pull Weights和Push Gradients涉及到通信,首先对于Pull Weights来说,参数服务器同时向worker发送权重,这是一对多的通信模式,称为fan-out通信模式。假设每个节点(参数服务器和工作节点)的通信带宽都为1。假设在这个数据并行训练作业中有N个工作节点,由于集中式参数服务器需要同时将模型发送给N个工作节点,因此每个工作节点的发送带宽(BW)仅为1/N。另一方面,每个工作节点的接收带宽为1,远大于参数服务器的发送带宽1/N。因此,在拉取权重阶段,参数服务器端存在通信瓶颈。
对于Push Gradients来说,所有的worker并发地发送梯度给参数服务器,称为fan-in通信模式,参数服务器同样存在通信瓶颈。
基于上述讨论,通信瓶颈总是发生在参数服务器端,将通过负载均衡解决这个问题
将模型划分为N个参数服务器,每个参数服务器负责更新1/N的模型参数。实际上是将模型参数分片(sharded model)并存储在多个参数服务器上,可以缓解参数服务器一侧的网络瓶颈问题,使得参数服务器之间的通信负载减少,提高整体的通信效率。
代码实现
定义网络结构:
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
if torch.cuda.is_available():
device = torch.device("cuda:0")
else:
device = torch.device("cpu")
self.conv1 = nn.Conv2d(1,32,3,1).to(device)
self.dropout1 = nn.Dropout2d(0.5).to(device)
self.conv2 = nn.Conv2d(32,64,3,1).to(device)
self.dropout2 = nn.Dropout2d(0.75).to(device)
self.fc1 = nn.Linear(9216,128).to(device)
self.fc2 = nn.Linear(128,20).to(device)
self.fc3 = nn.Linear(20,10).to(device)
def forward(self,x):
x = self.conv1(x)
x = self.dropout1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.dropout2(x)
x = F.max_pool2d(x,2)
x = torch.flatten(x,1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
output = F.log_softmax(x,dim=1)
return output
如上定义了一个简单的CNN
实现参数服务器:
class ParamServer(nn.Module):
def __init__(self):
super().__init__()
self.model = Net()
if torch.cuda.is_available():
self.input_device = torch.device("cuda:0")
else:
self.input_device = torch.device("cpu")
self.optimizer = optim.SGD(self.model.parameters(),lr=0.5)
def get_weights(self):
return self.model.state_dict()
def update_model(self,grads):
for para,grad in zip(self.model.parameters(),grads):
para.grad = grad
self.optimizer.step()
self.optimizer.zero_grad()
get_weights获取权重参数,update_model更新模型,采用SGD优化器
实现worker:
class Worker(nn.Module):
def __init__(self):
super().__init__()
self.model = Net()
if torch.cuda.is_available():
self.input_device = torch.device("cuda:0")
else:
self.input_device = torch.device("cpu")
def pull_weights(self,model_params):
self.model.load_state_dict(model_params)
def push_gradients(self,batch_idx,data,target):
data,target = data.to(self.input_device),target.to(self.input_device)
output = self.model(data)
data.requires_grad = True
loss = F.nll_loss(output,target)
loss.backward()
grads = []
for layer in self.parameters():
grad = layer.grad
grads.append(grad)
print(f"batch {batch_idx} training :: loss {loss.item()}")
return grads
Pull_weights获取模型参数,push_gradients上传梯度
训练
训练数据集为MNIST
import torch
from torchvision import datasets,transforms
from network import Net
from worker import *
from server import *
train_loader = torch.utils.data.DataLoader(datasets.MNIST('./mnist_data', download=True, train=True,
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])),
batch_size=128, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('./mnist_data', download=True, train=False,
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])),
batch_size=128, shuffle=True)
def main():
server = ParamServer()
worker = Worker()
for batch_idx, (data,target) in enumerate(train_loader):
params = server.get_weights()
worker.pull_weights(params)
grads = worker.push_gradients(batch_idx,data,target)
server.update_model(grads)
print("Done Training")
if __name__ == "__main__":
main()
分布式机器学习(Parameter Server)的更多相关文章
- 分布式机器学习系统笔记(一)——模型并行,数据并行,参数平均,ASGD
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术.应用感兴趣的同学加入. 文章索引::"机器学 ...
- 百度DMLC分布式深度机器学习开源项目(简称“深盟”)上线了如xgboost(速度快效果好的Boosting模型)、CXXNET(极致的C++深度学习库)、Minerva(高效灵活的并行深度学习引擎)以及Parameter Server(一小时训练600T数据)等产品,在语音识别、OCR识别、人脸识别以及计算效率提升上发布了多个成熟产品。
百度为何开源深度机器学习平台? 有一系列领先优势的百度却选择开源其深度机器学习平台,为何交底自己的核心技术?深思之下,却是在面对业界无奈时的远见之举. 5月20日,百度在github上开源了其 ...
- 【分布式计算】MapReduce的替代者-Parameter Server
原文:http://blog.csdn.net/buptgshengod/article/details/46819051 首先还是要声明一下,这个文章是我在入职阿里云1个月以来,对于分布式计算的一点 ...
- MXNet之ps-lite及parameter server原理
MXNet之ps-lite及parameter server原理 ps-lite框架是DMLC组自行实现的parameter server通信框架,是DMLC其他项目的核心,例如其深度学习框架MXNE ...
- 转:Parameter Server 详解
Parameter Server 详解 本博客仅为作者记录笔记之用,不免有很多细节不对之处. 还望各位看官能够见谅,欢迎批评指正. 更多相关博客请猛戳:http://blog.csdn.net/c ...
- Adam:大规模分布式机器学习框架
引子 转载请注明:http://blog.csdn.net/stdcoutzyx/article/details/46676515 又是好久没写博客,记得有一次看Ng大神的訪谈录,假设每周读三篇论文, ...
- 分布式机器学习框架:MxNet 前言
原文连接:MxNet和Caffe之间有什么优缺点一.前言: Minerva: 高效灵活的并行深度学习引擎 不同于cxxnet追求极致速度和易用性,Minerva则提供了一个高效灵活的平台 ...
- [Distributed ML] Parameter Server & Ring All-Reduce
Resource ParameterServer入门和理解[较为详细,涉及到另一个框架:ps-lite] 一文读懂「Parameter Server」的分布式机器学习训练原理 并行计算与机器学习[很有 ...
- parameter server学习
关于parameter server的学习: https://www.zybuluo.com/Dounm/note/517675 机器学习系统相比于其他系统而言,有一些自己的独特特点.例如: 迭代性: ...
- 分布式机器学习框架:CXXNet
caffe是很优秀的dl平台.影响了后面很多相关框架. cxxnet借鉴了很多caffe的思想.相比之下,cxxnet在实现上更加干净,例如依赖很少,通过mshadow的模板化使得gpu ...
随机推荐
- 2020 ccpc秦皇岛 赛后总结!!!!
amazing!!!! 金牌!!!!! 总结一下这次的发挥,以及如何冲到了金牌. 1 有队友单开了银牌题,50分钟过了K题,当时只有5个人过K.他敲的过程中另个队友想出来另外一题的思路,等过了K,我直 ...
- day10-SpringBoot的异常处理
SpringBoot异常处理 1.基本介绍 默认情况下,SpringBoot提供/error处理所有错误的映射,也就是说当出现错误时,SpringBoot底层会请求转发到/error这个映射路径所关联 ...
- Skywalking搭建
因毕设前端太丑,所以后端要稍微搞的高大上一点才能忽悠住老师,所以分享一下搭建skywalking的步. 我是参考https://baijiahao.baidu.com/s?id=17211835411 ...
- Windows7卡在正在关机
据我的分析,Windows系统卡在正在关机的原因很大可能性是破解过系统主题.解决方法就是还原成主题未被破解时候的状态.但是这种情况是随机性的,但是可以确定的是,只要是破解过系统主题,都有一定概率关不了 ...
- flutter widget---->FloatingActionButton
在Flutter中说起Button,floatingActionButton用的也非常的多.今天我们就来学习一下. Simple Example import 'package:flutter/mat ...
- Flutter中如何取消任务
前言 在开发过程中,取消需求是很常见的,但很容易被忽略.然而,取消需求的好处也很大.例如,在页面中会发送很多请求.如果页面被切走并处于不可见状态,就需要取消未完成的请求任务.如果未及时取消,则可能会导 ...
- 安装KubeOperator并导入现有集群进行管理
安装KubeOperator并导入现有集群进行管理 介绍 KubeOperator 是一个开源的轻量级 Kubernetes 发行版,专注于帮助企业规划.部署和运营生产级别的 Kubernetes 集 ...
- [Linux]常用命令之【mkdir/touch/cp/rm/ls/mv】
cp 将来源文件夹packageA下的所有目录及文件复制到新文件夹packageB下,形成: /packageB/... # cp -r /home/packageA/* /home/cp/packa ...
- Ficow 的 AI 平台快速上手指南(ChatGPT, NewBing, ChatGLM-6B, cursor.so)
本文首发于 Ficow Shen's Blog,原文地址: Ficow 的 AI 平台快速上手指南(ChatGPT, NewBing, ChatGLM-6B, cursor.so). 内容概览 前言 ...
- LeeCode 316周赛复盘
T1:判断两个事件是否存在冲突 思路:判断两个区间是否有交集 public boolean haveConflict(String[] event1, String[] event2) { // 比较 ...