图解三代测序(SMRT Sequencing)
目前主流三代测序平台除了Oxford 家的 Nanopore,还有 Pacific Biosciences(简称 PacBio)公司的 Single Molecule Real-Time(SMRT)Sequencing。该平台的优势在于:
在不会影响吞吐量和准确性的前提下,提供目前最长的 25 kb 的 Reads 长度
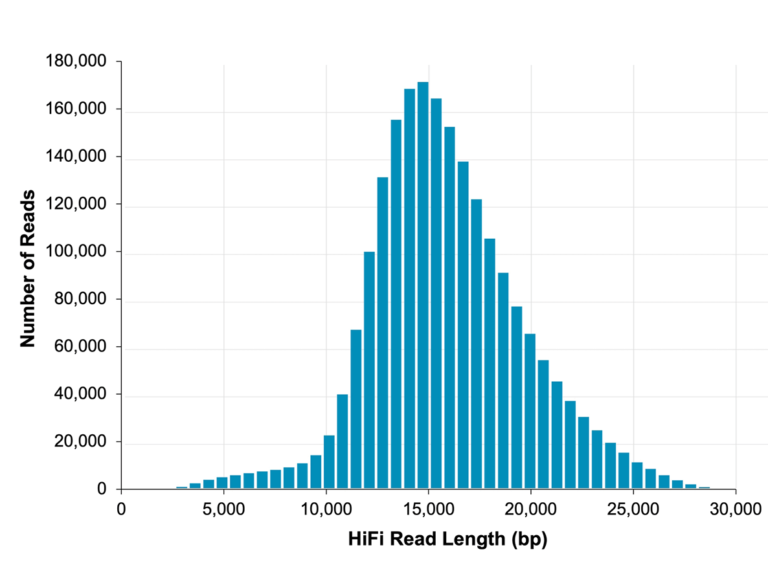
如果不含系统误差,准确度可达 99.999%,这样高质量的 Reads 可以解析几乎所有类型变体,从头组装高质量基因组
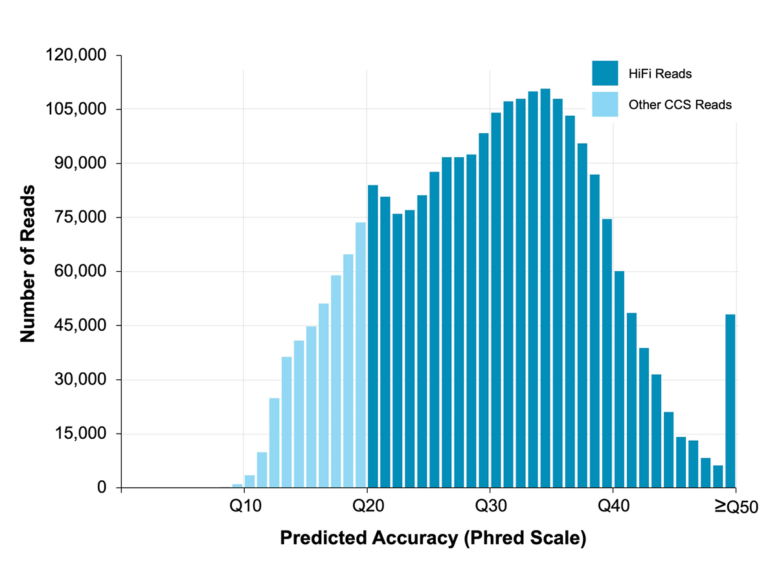
可测取富含 AT 或 GC 区域,高度重复序列,回文序列等,不会产生 GC 的较大偏差
可直接测取化学修饰,在表观遗传学中有重要应用
吃个瓜,2018年11月1日,Illumina 同意以 12 亿美元现金收购 PacBio 和其三代测序技术。
但是,去年 Illumina 放弃了收购计划,摊手。
接下来,我们看看它如何巧妙地完成这样的高质量三代测序。
 1 基本原理
1 基本原理
边合成边测序,与前文我们说的 Illumina 的基本测序原理一样。
2 构建文库
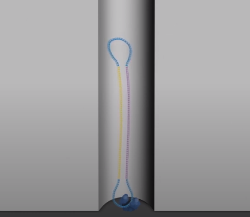
将样本中的 DNA 或 RNA 分子提取后,构建如下的哑铃状分子结构:

黄色,紫色:双链 DNA 分子
蓝色:接头(Adapter)
将文库分子展开,一个完整的圆环出现在我们眼前:
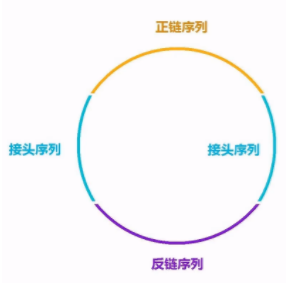
这种结构有利于进行周而复始的滚环复制,我们后文会讲这种复制方式的好处。
将样本中所有的DNA片段都构建哑铃状分子结构,组成的集合就叫文库(SMRTbell Library),随后,它们会被放到测序芯片中。
3 测序芯片
以 RSII 测序平台为例,测序仪芯片(SMRT Cell)长这样:

放大后:

上面整齐排列着15万个直径为70纳米的测序微孔(Zero-Model Waveguides,ZMWs)。
4 上机测序
1、构建测序复合物
测序复合物:聚合酶,测序模板,测序引物

2、复合物撒入测序小孔
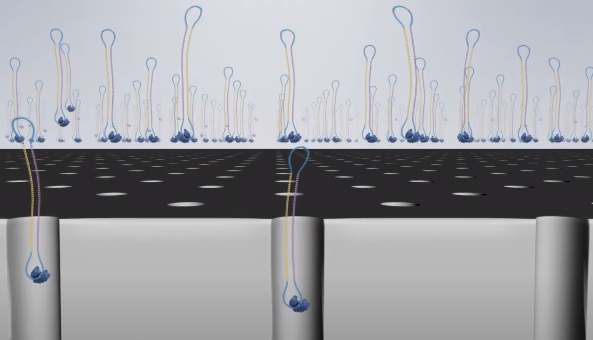
3、固定测序复合物
由于聚合酶加了生物素,在芯片玻璃底板有链酶亲和素。利用生物素和链酶亲和素的亲和力,包含聚合酶的测序复合物会被固定在玻璃底板。
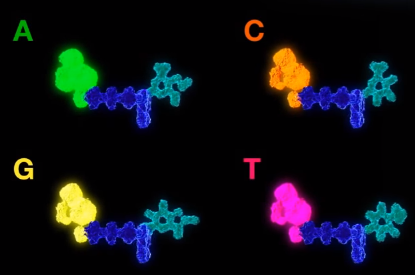
4、构建带有荧光基团的 dNTP
在芯片溶液中含有许多游离 dNTP,所谓游离 dNTP 就是随机飘在溶液中的 dNTP。
ATGC 四种碱基的 dNTP,在磷酸基团上分别带有四种颜色的荧光基团。
5、边合成边测序
在合成时,游离的 dNTP 被固定在底板上的酶捕获,激发光会从玻璃板底部发出。
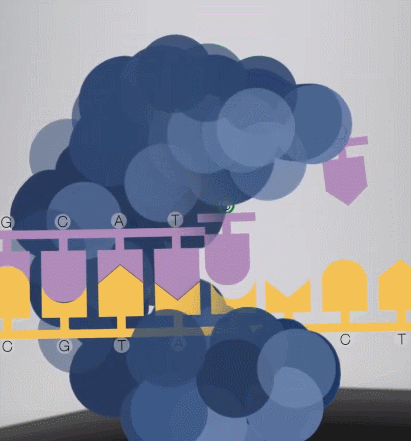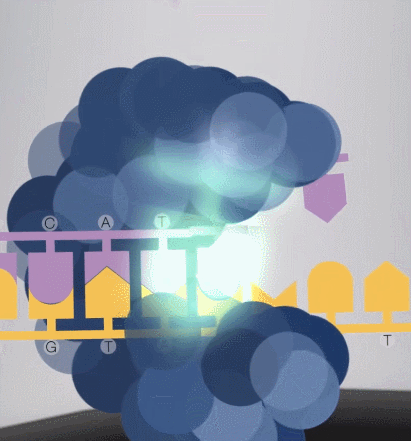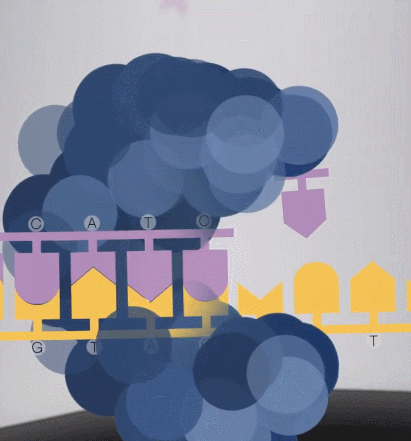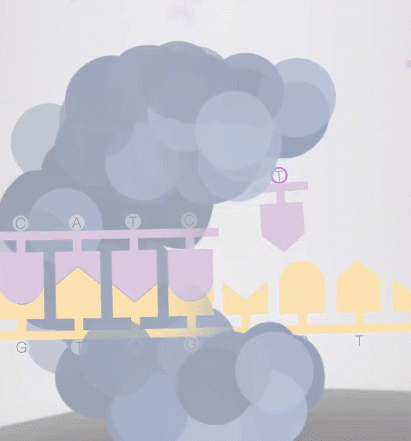
怎么保证每次测取一个碱基?
由于测序小孔直径很小,激发光的穿透能力会逐渐衰减,只能在小孔中传输很短的距离,所以只有当 dNTP 足够靠近底部,荧光基团才会被激发光照到,发出荧光。当然,其他的游离 dNTP,虽然也有可能飘到小孔底部被激发光照到,但这种情况极少。
在一个碱基合成结束后,带有荧光基团的磷酸基团会从 dNTP 上掉落,发生猝灭,不影响其他碱基的信号检测。
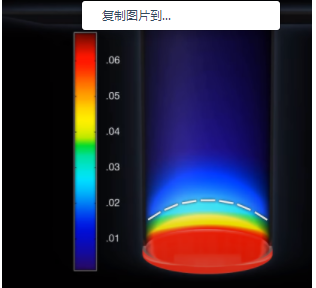
在发生测序的小孔有各自的 DNA 片段和测序复合物,同一时间发出不同颜色的激发光,机器会检测到如下的光信号,实际同时会得到多达几万个光点。

重复上述步骤,经过计算机分析光谱,最终我们拿到样本的测序文件。SMRT Sequencing 测序过程中,每秒读取三个碱基,一个小时可检测大约一万多碱基。
6、检测碱基甲基化
有意思的是,在 SMRT Sequencing 测序过程中,可以直接测到碱基被修饰的状态,聚合酶遇到碱基上带有甲基化的碱基,合成速度会明显变慢,而且光谱也会发生改变。
因此,SMRT Sequencing 可以检测到碱基的甲基化修饰情况。
5 测序模型
SMRT 测序有如下两种测序模式:
1、Circular Consensus Sequencing (CCS)
说这种测序模型前,就不得不提三代测序最大的缺点:碱基读取不准,错误率在12.5%,也就是说,每读取八个碱基,就会读错一个。
好在碱基读取错误是随机的,如果重新读一遍同样位置的碱基,不一定会发生同样的错误。
如果对同一个序列,多测几遍,那么这些读错的碱基就能矫正过来。
前边提到的滚环复制的优势就来了,我们可以利用测序复合物在环状文库分子循环测序同一个片段来消除错误率。
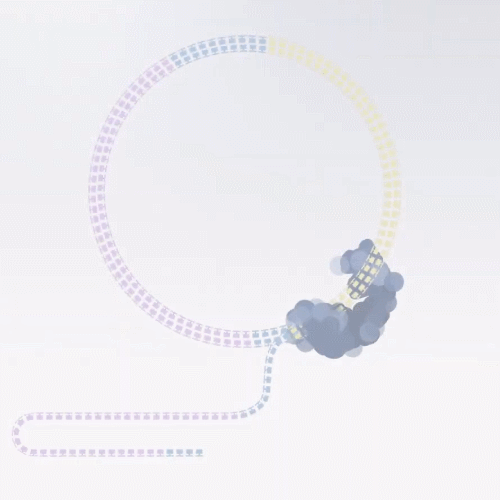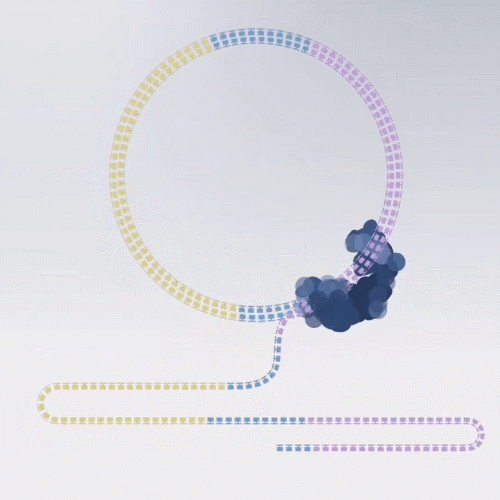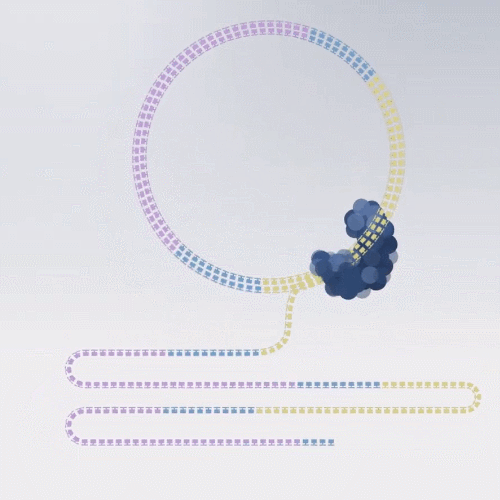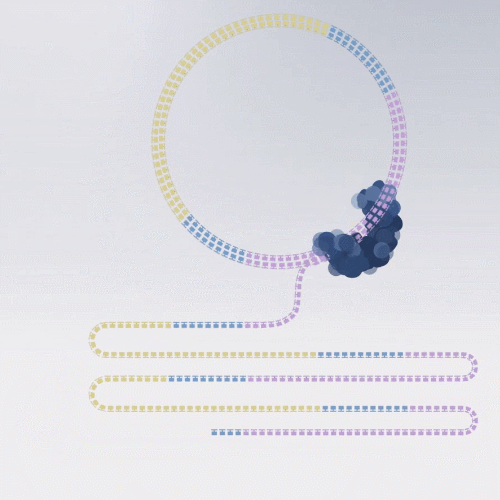
这种测序模型,复制出的 Reads叫 HiFi Reads,测序准确率 > 99%。
2、Continuous Long Read (CLR) Sequencing
这种测序的优势在于可以读取更长的 Reads。

6 其他影响因素
1、GC bias 影响
什么是 GC bias?
PCR 时,如果模板里的 G、C 碱基含量高,PCR 效率低,A、T碱 基含量高,PCR 效率高。一般测序过程,如二代测序,都会有大量的 PCR 过程。这样就会有一个问题,G、C 含量高的片段,读到的 Reads 数少。
SMRT 在测序过程中,没有 PCR 过程,因此富含 GC 含量高,含量低的 Reads 片段都会有相似的概率被测序,所以三代测序中的 GC Bias 影响小。
2、读长的限制因素
DNA 模板断裂,用激发光长时间照射 DNA 链时,会发生断裂,DNA 链会从酶上掉下来,测序终止。
酶变性,酶被长时间照射时,酶会变性,失去聚合酶活性,测序终止。
文库序列短,如果做文库序列片段大于 20~30 K ,且保证质量的文库是有技术难度的
3、测序通量
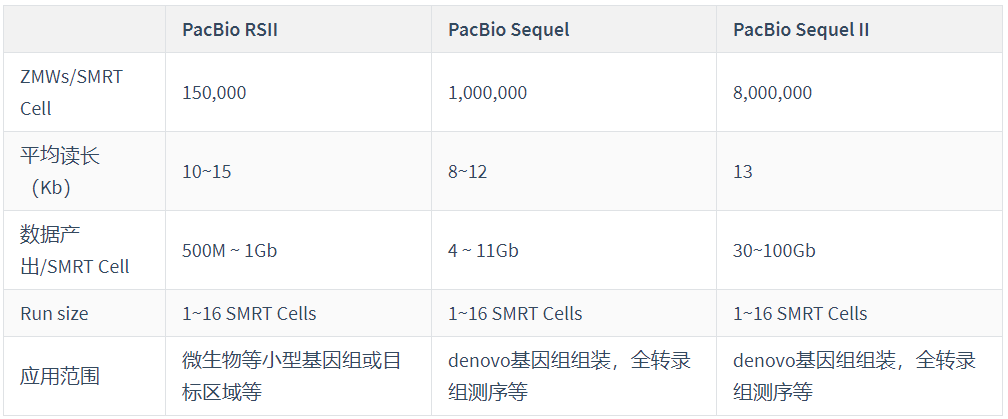
目前,主流的测序平台由三种,各有利弊,可以根据自己的课题来选择。
以 RSII 为例,将测序复合物,随机撒到 15 万个小孔中,正好有一个复合物进入到单个小孔的概率符合泊松分布。理论情况是
1/3 的小孔中有一个测序复合物,正常信号
1/3 的小孔什么都没有,无信号
1/3 的小孔中有两个以上的测序复合物,杂乱信号
五万个小孔 * 10kb,所以一张芯片大约会产出 500M 的数据。
参考:
https://www.cnbc.com/2020/01/02/illumina-abandons-1point2-billion-deal-to-buy-rival-pacific-biosciences.html
https://www.youtube.com/watch?v=rUKhfITd2CA
https://www.youtube.com/watch?v=NHCJ8PtYCFc&t=1s
文末友情推荐
•《2021生信学习班起航,先送福利》•《96核心384G内存的超级服务器(共享)使用权一年》

本文分享自微信公众号 - 生信科技爱好者(bioitee)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
图解三代测序(SMRT Sequencing)的更多相关文章
- 4、Brief primer and lexicon for PacBio SMRT sequencing
转载:http://pacbiofileformats.readthedocs.io/en/5.1/Primer.html 转载:http://pacbiofileformats.readthedoc ...
- 用单分子测序(single-molecule sequencing)和局部敏感哈希(locality-sensitive hashing)来组装大型基因组
Assembling large genomes with single-molecule sequencing and locality-sensitive hashing 好好读读,算法系列的好文 ...
- 三代PacBio reads纠错 - 专题
三代纠错的重要性不言而喻,三代的核心优势就是长,唯一的缺点就是错误率高,但好就好在错误是随机分布的,可以通过算法解决,这也就是为什么现在有这么多针对三代开发的纠错工具. 纠错和组装是分不开的,纠错就是 ...
- DNA甲基化测序方法介绍
DNA甲基化测序方法介绍 甲基化 表观遗传学 DNA 甲基化是表观遗传学(Epigenetics)的重要组成部分,在维持正常细胞功能.遗传印记.胚胎发育以及人类肿瘤发生中起着重要作用,是目前新的研究热 ...
- 测序原理 - PacBio技术资料
手头有一套完整的PacBio技术资料,会慢慢的总结到博客上. 写在前面:PacBio公司主要有两个测序平台一个是RS,一个是最新的Sequel,下面如果没有指明则是在讲RS平台. SMRT测序技术总览 ...
- smrt analysis 软件安装
pacbio 公司把三代测序常用软件整合起来,做成了一个在线的分析软件,类似于galaxy; 安装过程如下,参考官网给的指导手册 http://www.pacb.com/wp-content/uplo ...
- Pacbio 纯三代组装复活草基因组
对于植物等真核生物基因组来说,重复序列, 多倍体,高杂合度等特征在利用二代数据进行组装的时候都会有很大的问题: 利用二代数据组装出来的基因组,大多达不到完成图的水准,通常只是覆盖到编码蛋白的基因区域, ...
- 第三代PacBio测序技术的测序原理和读长
针对PacBio单分子测序——第三代测序技术的测序原理和读长 DNA基因测序技术从上世纪70年代起,历经三代技术后,目前已发展成为一项相对成熟的生物产业.测序技术的应用也扩展到了生物.医学.制 ...
- 植物基因组|注释版本问题|重测序vs泛基因组
生命组学: 细菌和其他物种比,容易发生基因漂移,duplication和重排. 泛基因组学研究的一般思路是通过comparison找到特殊基因区域orspecific gene,研究其调控机制(即通过 ...
- Iso-Seq学习
SMRT portal安装教程: http://www.pacb.com/wp-content/uploads/2015/09/SMRT-Analysis-Software-Installation- ...
随机推荐
- 必知必会的 WebSocket 协议
文章介绍 WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议,它的出现使客户端和服务器之间的数据交换变得更加简单.WebSocket 通常被应用在实时性要求较高的场景,例如赛事数据. ...
- sort和sorted区别----引子:多维列表,如何实现第一个元素升序,第二个元素降序
一.列表内建方法--sort() 作用:就地对列表排序(直接在原列表上做排序) 语法: list.sort(func=None, key=None, reverse=False) 当reverse=F ...
- 容器云平台监控告警体系(三)—— 使用Prometheus Operator部署并管理Prometheus Server
1.概述 Prometheus Operator是一种基于Kubernetes的应用程序,用于管理Prometheus实例和相关的监控组件.它是由CoreOS开发的开源工具,旨在简化Prometheu ...
- Spring(Bean详解)
GoF之工厂模式 GoF是指二十三种设计模式 GoF23种设计模式可分为三大类: 创建型(5个):解决对象创建问题. 单例模式 工厂方法模式 抽象工厂模式 建造者模式 原型模式 结构型(7个):一些类 ...
- pandas之分类操作
通常情况下,数据集中会存在许多同一类别的信息,比如相同国家.相同行政编码.相同性别等,当这些相同类别的数据多次出现时,就会给数据处理增添许多麻烦,导致数据集变得臃肿,不能直观.清晰地展示数据. 针对上 ...
- 如何在Java中做基准测试?JMH使用初体验
大家好,我是王有志,欢迎和我聊技术,聊漂泊在外的生活.快来加入我们的Java提桶跑路群:共同富裕的Java人. 最近公司在搞新项目,由于是实验性质,且不会直接面对客户的项目,这次的技术选型非常激进,如 ...
- MySQL笔记之Checkpoint机制
CheckPoint是MySQL的WAL和Redolog的一个优化技术. 一.Checkpoint机制 CheckPoint做了什么事情?将缓存池中的脏页刷回磁盘. checkpoint定期将db b ...
- 2023-04-20:有一堆石头,用整数数组 stones 表示 其中 stones[i] 表示第 i 块石头的重量。 每一回合,从中选出任意两块石头,然后将它们一起粉碎 假设石头的重量分别为 x 和
2023-04-20:有一堆石头,用整数数组 stones 表示 其中 stones[i] 表示第 i 块石头的重量. 每一回合,从中选出任意两块石头,然后将它们一起粉碎 假设石头的重量分别为 x 和 ...
- odoo wizard界面显示带复选框列表及勾选数据获取
实践环境 Odoo 14.0-20221212 (Community Edition) 需求描述 如下图(非实际项目界面截图,仅用于介绍本文主题),打开记录详情页(form视图),点击某个按钮(图中的 ...
- NLP入门1——李宏毅网课笔记
近日因为项目需要,开始恶补预习NLP的相关知识.以前也看过两本相关书籍,但是都十分浅显.这次准备详细的学一下并记录. 李宏毅老师的网课是 Deep Learning for Human Languag ...