YoloV5实战:手把手教物体检测
摘要:YOLOv5并不是一个单独的模型,而是一个模型家族,包括了YOLOv5s、YOLOv5m、YOLO...
本文分享自华为云社区《YoloV5实战:手把手教物体检测——YoloV5》,作者: AI浩 。
摘要
YOLOV5严格意义上说并不是YOLO的第五个版本,因为它并没有得到YOLO之父Joe Redmon的认可,但是给出的测试数据总体表现还是不错。详细数据如下
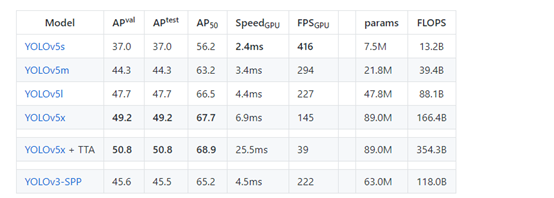
YOLOv5并不是一个单独的模型,而是一个模型家族,包括了YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x、YOLOv5x+TTA,这点有点儿像EfficientDet。由于没有找到V5的论文,我们也只能从代码去学习它。总体上和YOLOV4差不多,可以认为是YOLOV5的加强版。
项目地址:GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
训练
1、下载代码
项目地址:https://github.com/ultralytics/YOLOv5,最近作者又更新了一些代码。
2、配置环境
matplotlib>=3.2.2 numpy>=1.18.5 opencv-python>=4.1.2 pillow PyYAML>=5.3 scipy>=1.4.1 tensorboard>=2.2 torch>=1.6.0 torchvision>=0.7.0 tqdm>=4.41.0
3、准备数据集
数据集采用Labelme标注的数据格式,数据集从RSOD数据集中获取了飞机和油桶两类数据集,并将其转为Labelme标注的数据集。
数据集的地址: https://pan.baidu.com/s/1iTUpvA9_cwx1qiH8zbRmDg
提取码:gr6g
或者:LabelmeData.zip_yolov5实战-深度学习文档类资源-CSDN下载
将下载的数据集解压后放到工程的根目录。为下一步生成测试用的数据集做准备。如下图:
4、生成数据集
YoloV5的数据集和以前版本的数据集并不相同,我们先看一下转换后的数据集。
数据结构如下图:
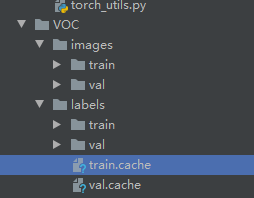
images文件夹存放train和val的图片
labels里面存放train和val的物体数据,里面的每个txt文件和images里面的图片是一一对应的。
txt文件的内容如下:
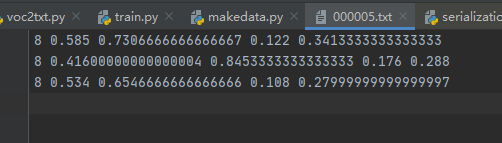
格式:物体类别 x y w h
坐标是不是真实的坐标,是将坐标除以宽高后的计算出来的,是相对于宽和高的比例。
下面我们编写生成数据集的代码,新建LabelmeToYoloV5.py,然后写入下面的代码。
import os import numpy as np import json from glob import glob import cv2 from sklearn.model_selection import train_test_split from os import getcwd
classes = ["aircraft", "oiltank"] # 1.标签路径 labelme_path = "LabelmeData/" isUseTest = True # 是否创建test集 # 3.获取待处理文件 files = glob(labelme_path + "*.json") files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files] print(files) if isUseTest: trainval_files, test_files = train_test_split(files, test_size=0.1, random_state=55) else: trainval_files = files # split train_files, val_files = train_test_split(trainval_files, test_size=0.1, random_state=55)
def convert(size, box): dw = 1. / (size[0]) dh = 1. / (size[1]) x = (box[0] + box[1]) / 2.0 - 1 y = (box[2] + box[3]) / 2.0 - 1 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h)
wd = getcwd() print(wd)
def ChangeToYolo5(files, txt_Name): if not os.path.exists('tmp/'): os.makedirs('tmp/') list_file = open('tmp/%s.txt' % (txt_Name), 'w') for json_file_ in files: json_filename = labelme_path + json_file_ + ".json" imagePath = labelme_path + json_file_ + ".jpg" list_file.write('%s/%s\n' % (wd, imagePath)) out_file = open('%s/%s.txt' % (labelme_path, json_file_), 'w') json_file = json.load(open(json_filename, "r", encoding="utf-8")) height, width, channels = cv2.imread(labelme_path + json_file_ + ".jpg").shape for multi in json_file["shapes"]: points = np.array(multi["points"]) xmin = min(points[:, 0]) if min(points[:, 0]) > 0 else 0 xmax = max(points[:, 0]) if max(points[:, 0]) > 0 else 0 ymin = min(points[:, 1]) if min(points[:, 1]) > 0 else 0 ymax = max(points[:, 1]) if max(points[:, 1]) > 0 else 0 label = multi["label"] if xmax <= xmin: pass elif ymax <= ymin: pass else: cls_id = classes.index(label) b = (float(xmin), float(xmax), float(ymin), float(ymax)) bb = convert((width, height), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') print(json_filename, xmin, ymin, xmax, ymax, cls_id) ChangeToYolo5(train_files, "train") ChangeToYolo5(val_files, "val") ChangeToYolo5(test_files, "test")
这段代码执行完成会在LabelmeData生成每个图片的txt标注数据,同时在tmp文件夹下面生成训练集、验证集和测试集的txt,txt记录的是图片的路径,为下一步生成YoloV5训练和测试用的数据集做准备。在tmp文件夹下面新建MakeData.py文件,生成最终的结果,目录结构如下图:
打开MakeData.py,写入下面的代码。
import shutil
import os file_List = ["train", "val", "test"]
for file in file_List:
if not os.path.exists('../VOC/images/%s' % file):
os.makedirs('../VOC/images/%s' % file)
if not os.path.exists('../VOC/labels/%s' % file):
os.makedirs('../VOC/labels/%s' % file)
print(os.path.exists('../tmp/%s.txt' % file))
f = open('../tmp/%s.txt' % file, 'r')
lines = f.readlines()
for line in lines:
print(line)
line = "/".join(line.split('/')[-5:]).strip()
shutil.copy(line, "../VOC/images/%s" % file)
line = line.replace('JPEGImages', 'labels')
line = line.replace('jpg', 'txt')
shutil.copy(line, "../VOC/labels/%s/" % file)
执行完成后就可以生成YoloV5训练使用的数据集了。结果如下:
5、修改配置参数
打开voc.yaml文件,修改里面的配置参数 train: VOC/images/train/ # 训练集图片的路径 val: VOC/images/val/ # 验证集图片的路径 # number of classes nc: 2 #检测的类别,本次数据集有两个类别所以写2
# class names names: ["aircraft", "oiltank"]#类别的名称,和转换数据集时的list对应
6、修改train.py的参数
cfg参数是YoloV5 模型的配置文件,模型的文件存放在models文件夹下面,按照需求填写不同的文件。
weights参数是YoloV5的预训练模型,和cfg对应,例:cfg配置的是yolov5s.yaml,weights就要配置yolov5s.pt
data是配置数据集的配置文件,我们选用的是voc.yaml,所以配置data/voc.yaml
修改上面三个参数就可以开始训练了,其他的参数根据自己的需求修改。修改后的参数配置如下:
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/voc.yaml', help='data.yaml path')
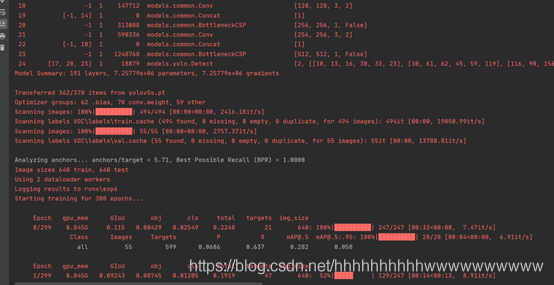
修改完成后,就可以开始训练了。如下图所示:
7、查看训练结果
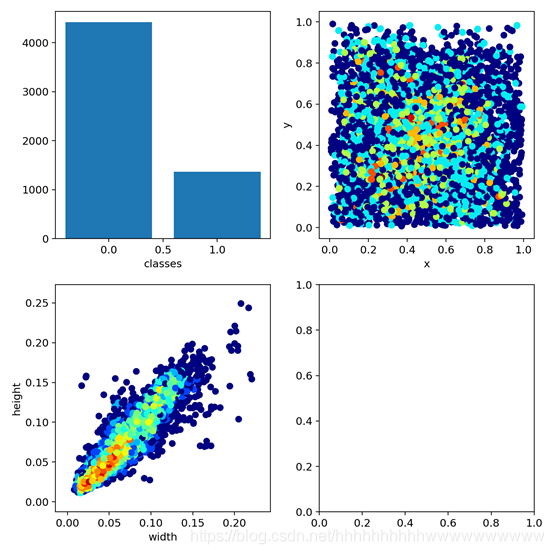
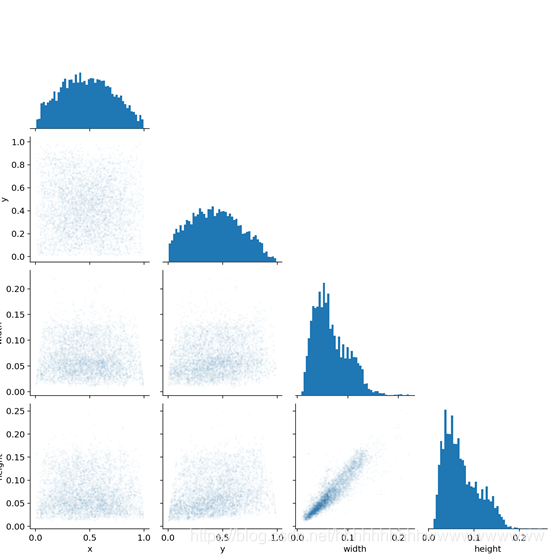
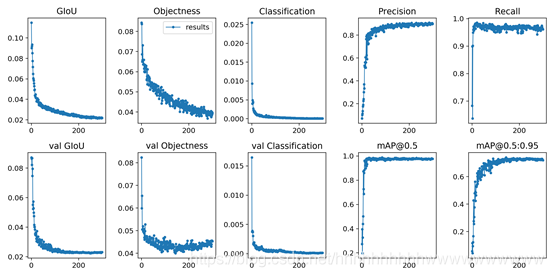
在经历了300epoch训练之后,我们会在runs文件夹下面找到训练好的权重文件和训练过程的一些文件。如图:

测试
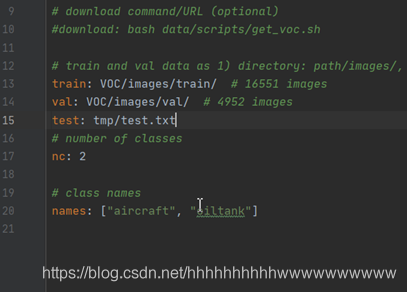
首先需要在voc.yaml中增加测试集的路径,打开voc.yaml,在val字段后面增加test: tmp/test.txt这行代码,如图:
修改test.py中的参数,下面的这几个参数要修改。
parser = argparse.ArgumentParser(prog='test.py')
parser.add_argument('--weights', nargs='+', type=str, default='runs/exp7/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--data', type=str, default='data/voc.yaml', help='*.data path')
parser.add_argument('--batch-size', type=int, default=2, help='size of each image batch')
parser.add_argument('--save-txt', default='True', action='store_true', help='save results to *.txt')
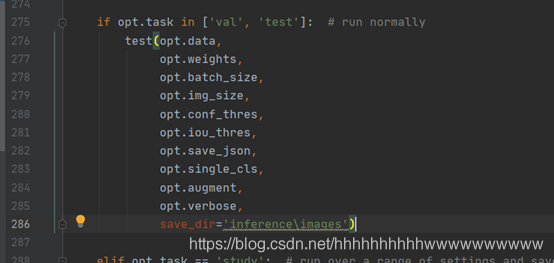
在275行 修改test的方法,增加保存测试结果的路径。这样测试完成后就可以在inference\images查看到测试的图片,在inference\output中查看到保存的测试结果。
如图:
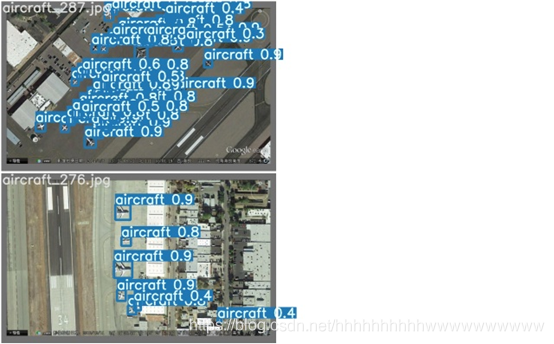
下面是运行的结果:
YoloV5实战:手把手教物体检测的更多相关文章
- 【YOLOv5】手把手教你使用LabVIEW ONNX Runtime部署 TensorRT加速,实现YOLOv5实时物体识别(含源码)
前言 上一篇博客给大家介绍了LabVIEW开放神经网络交互工具包[ONNX],今天我们就一起来看一下如何使用LabVIEW开放神经网络交互工具包实现TensorRT加速YOLOv5. 以下是YOLOv ...
- yolov5实战之皮卡丘检测
前言 从接触深度学习开始一直都做的是人脸识别,基本上也一直都在用mxnet. 记得之前在刚接触的时候看到博客中写到,深度学习分三个层次,第一个层次是分类,第二个层次是检测,第三个层次是分割.人脸识别算 ...
- 手把手教你用Pytorch-Transformers——实战(二)
本文是<手把手教你用Pytorch-Transformers>的第二篇,主要讲实战 手把手教你用Pytorch-Transformers——部分源码解读及相关说明(一) 使用 PyTorc ...
- yolov5实战之二维码检测
目录 1.前沿 2.二维码数据 3.训练配置 3.1数据集设置 3.2训练参数的配置 3.3网络结构设置 3.4训练 3.5结果示例 附录:数据集下载 1.前沿 之前总结过yolov5来做皮卡丘的检测 ...
- 手把手教你用深度学习做物体检测(五):YOLOv1介绍
"之前写物体检测系列文章的时候说过,关于YOLO算法,会在后续的文章中介绍,然而,由于YOLO历经3个版本,其论文也有3篇,想全面的讲述清楚还是太难了,本周终于能够抽出时间写一些YOLO算法 ...
- 手把手教你用深度学习做物体检测(六):YOLOv2介绍
本文接着上一篇<手把手教你用深度学习做物体检测(五):YOLOv1介绍>文章,介绍YOLOv2在v1上的改进.有些性能度量指标术语看不懂没关系,后续会有通俗易懂的关于性能度量指标的介绍文章 ...
- 30分钟手把手教你学webpack实战
30分钟手把手教你学webpack实战 阅读目录 一:什么是webpack? 他有什么优点? 二:如何安装和配置 三:理解webpack加载器 四:理解less-loader加载器的使用 五:理解ba ...
- 手把手教你写电商爬虫-第三课 实战尚妆网AJAX请求处理和内容提取
版权声明:本文为博主原创文章,未经博主允许不得转载. 系列教程: 手把手教你写电商爬虫-第一课 找个软柿子捏捏 手把手教你写电商爬虫-第二课 实战尚妆网分页商品采集爬虫 看完两篇,相信大家已经从开始的 ...
- 转:手把手教你如何玩转Solr(包含项目实战)
原文地址:手把手教你如何玩转Solr(包含项目实战) 参考原文
- 每天记录一点:NetCore获得配置文件 appsettings.json vue-router页面传值及接收值 详解webpack + vue + node 打造单页面(入门篇) 30分钟手把手教你学webpack实战 vue.js+webpack模块管理及组件开发
每天记录一点:NetCore获得配置文件 appsettings.json 用NetCore做项目如果用EF ORM在网上有很多的配置连接字符串,读取以及使用方法 由于很多朋友用的其他ORM如S ...
随机推荐
- svn 分支的创建及合并
http://blog.csdn.net/jixiuffff/article/details/5586858 http://zhidao.baidu.com/link?url=uiRk-4ZBkLPx ...
- 关于区间DP的一点点心得(虽然还是很菜)
自己今天对于区间 DP 的一个总结 区间 DP 的数组一般是二维,其状态一般表示区间 \((l,r)\). 区间 DP 在思考的时候是有一定套路的,思考时可以按照如下方式进行思考: 这段区间要维护的信 ...
- MIT实验警示:人类或需要人工智能辅助才能理解复杂逻辑
麻省理工实验揭示人类的天赋缺陷 麻省理工学院林肯实验室(MIT Lincoln Laboratory)的一项研究表明,尽管形式规范具有数学上的精确性,但人类并不一定能对其进行解释.换句话说就是,人类在 ...
- 支持向量机SVM:从数学原理到实际应用
本篇文章全面深入地探讨了支持向量机(SVM)的各个方面,从基本概念.数学背景到Python和PyTorch的代码实现.文章还涵盖了SVM在文本分类.图像识别.生物信息学.金融预测等多个实际应用场景中的 ...
- .net 获取客户端真实ip
Nginx 如何设置 情况1 在只有1层nginx代理的情况下,设置nginx配置"proxy_set_header X-Forwarded-For $remote_addr;". ...
- centos虚拟机安装
目录 一.准备工作 1.vmware workstation软件安装 2.准备ios镜像 二.创建Centos虚拟机 三.进行Centos7的系统安装 四.虚拟机快照的使用 1.创建虚拟机快照 2.还 ...
- Android 图表开源库调研及使用示例
原文地址: Android图表开源库调研及使用示例 - Stars-One的杂货小窝 之前做的几个项目都是需要实现图表统计展示,于是做之前调研了下,做下记录 概述 AAChartCore-Kotlin ...
- 【Python微信机器人】第六篇:优化使用方式,可pip安装
优化内容 这篇不聊技术点,说一下优化后的Python机器人代码怎么使用,优化内容如下: 将hook库独立成一个库,发布到pypi,可使用pip安装 将微信相关的代码发布成另一个库,也可以pip安装 g ...
- 太牛叉了!国产 AI 智能体惊艳问世,全面致敬 FastGPT!
太震撼了!太厉害了!昆仑万维正式发布了「天工 SkyAgents」平台,助力大模型走入千家万户.你听听,这个名字一听就有一种巧夺天工的感觉,技艺那是相当的高超. 这个平台基于昆仑万维「天工大模型」打造 ...
- android webview(外部浏览器)调起app
最近写的项目中涉及外部浏览器以及项目webview中调起app,所以总结下,和大家分享下. 总的实现方法还是比较简单的, 1:在清单中注册 首先在AndroidManifest文件中,注册一个过滤器 ...