openGauss内核分析:执行计划生成
摘要:SQL语句解析完成后被解析成Query结构,在进行优化时是以Query为单位进行的,Query的优化分为基于规则的逻辑优化(查询重写)和基于代价的物理优化(计划生成),主入口函数为subquery_planner。subquery_planner函数接收Query(查询树),返回一个Plan(计划树)。
本文分享自华为云社区《openGauss内核分析(六) 执行计划生成》,作者:Gauss松鼠会。
SQL语句解析完成后被解析成Query结构,在进行优化时是以Query为单位进行的,Query的优化分为基于规则的逻辑优化(查询重写)和基于代价的物理优化(计划生成),主入口函数为subquery_planner。subquery_planner函数接收Query(查询树),返回一个Plan(计划树)。
Plan* subquery_planner(PlannerGlobal* glob, Query* parse, PlannerInfo* parent_root, bool hasRecursion,
double tuple_fraction, PlannerInfo** subroot, int options, ItstDisKey* diskeys, List* subqueryRestrictInfo)
{
PlannerInfo* root = NULL;
Plan* plan = NULL; //返回结果
…
preprocess_const_params(root, (Node*)parse->jointree); // 常数替换等式
…
if (parse->hasSubLinks) {
pull_up_sublinks(root); //提升子链接
DEBUG_QRW("After sublink pullup");
}
/* Reduce orderby clause in subquery for join */
reduce_orderby(parse, false); //减少orderby
DEBUG_QRW("After order by reduce");
if (u_sess->attr.attr_sql.enable_constraint_optimization) {
removeNotNullTest(root); //删除NotNullTest
DEBUG_QRW("After soft constraint removal");
}
…
if ((LAZY_AGG & u_sess->attr.attr_sql.rewrite_rule) && permit_from_rewrite_hint(root, LAZY_AGG)) {
lazyagg_main(parse); // lazyagg重写
DEBUG_QRW("After lazyagg");
}
…
parse->jointree = (FromExpr*)pull_up_subqueries(root, (Node*)parse->jointree); //提升子查询
…
if (parse->setOperations) {
flatten_simple_union_all(root); //UNIONALL优化
DEBUG_QRW("After simple union all flatten");
}
…
expand_inherited_tables(root); //展开继承表
…
parse->targetList = (List*)preprocess_expression(root, (Node*)parse->targetList, EXPRKIND_TARGET); //预处理表达式
…
parse->havingQual = (Node *) newHaving; //处理HAVING子句
…
reduce_outer_joins(root); //外连接消除
…
reduce_inequality_fulljoins(root); //全连接重写
…
plan = grouping_planner(root, tuple_fraction); //主要的计划过程
…
return plan;
}
subquery_planner函数由函数standard_planner调用,standard_planner函数由exec_simple_query->pg_plan_queries->pg_plan_query->planner函数调用。standard_planner将Query(查询树)生成规划好的语句,可用于执行器实际执行。
PlannedStmt* standard_planner(Query* parse, int cursorOptions, ParamListInfo boundParams)
{
PlannedStmt* result = NULL; //返回结果
PlannerGlobal* glob = NULL;
double tuple_fraction;
PlannerInfo* root = NULL;
Plan* top_plan = NULL;
…
glob = makeNode(PlannerGlobal);
/* primary planning entry point (may recurse for subqueries) */
top_plan = subquery_planner(glob, parse, NULL, false, tuple_fraction, &root); //主规划过程入口
…
/* build the PlannedStmt result */
result = makeNode(PlannedStmt); //构造PlannedStmt
result->commandType = parse->commandType;
result->queryId = parse->queryId;
result->uniqueSQLId = parse->uniqueSQLId;
result->hasReturning = (parse->returningList != NIL);
result->hasModifyingCTE = parse->hasModifyingCTE;
result->canSetTag = parse->canSetTag;
result->transientPlan = glob->transientPlan;
result->dependsOnRole = glob->dependsOnRole;
result->planTree = top_plan; //执行计划
result->rtable = glob->finalrtable;
result->resultRelations = glob->resultRelations;
…
return result;
}
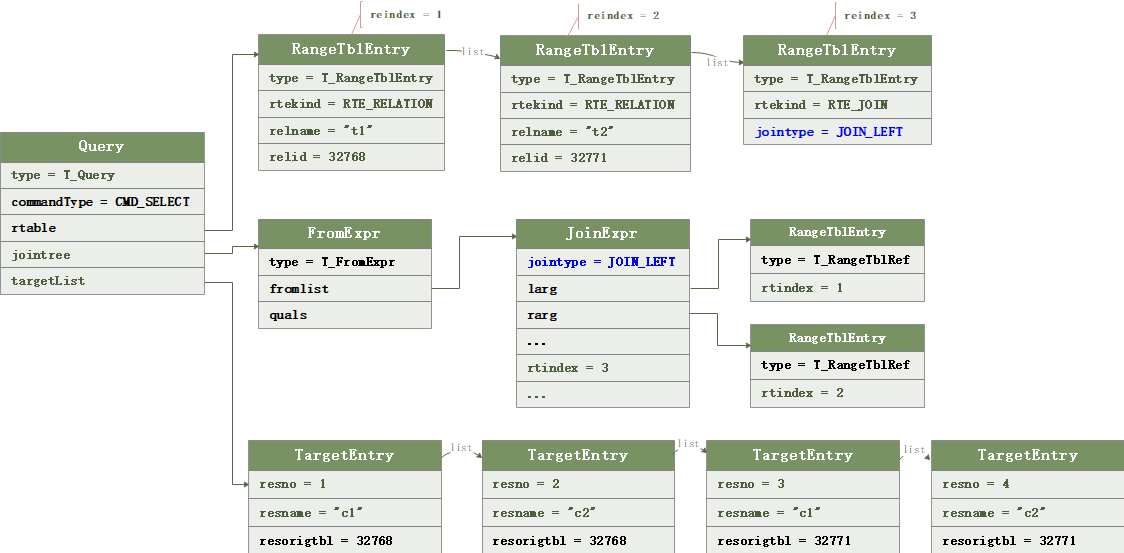
仍然以前文的join列子来说明
SELECT * FROM t1 inner JOIN t2 ON t1.c1 = t2.c1;复制
在planner函数打断点,用gdb查看standard_planner返回的PlannedStmt
(gdb) bt
#0 planner (parse=0x7fd93a410288, cursorOptions=0, boundParams=0x0) at planner.cpp:389
#1 0x0000000001936fbd in pg_plan_query (querytree=0x7fd93a410288, cursorOptions=0, boundParams=0x0, underExplain=false) at postgres.cpp:1197
#2 0x0000000001937381 in pg_plan_queries (querytrees=0x7fd939b81090, cursorOptions=0, boundParams=0x0) at postgres.cpp:1315
#3 0x000000000193a6b8 in exec_simple_query (query_string=0x7fd966ad2060 "SELECT * FROM t1 inner JOIN t2 ON t1.c1 = t2.c1;", messageType=QUERY_MESSAGE, msg=0x7fd931056210)
at postgres.cpp:2560
#4 0x0000000001947104 in PostgresMain (argc=1, argv=0x7fd93a2cf1c0, dbname=0x7fd93a2ce1f8 "postgres", username=0x7fd93a2ce1b0 "test") at postgres.cpp:8403
#5 0x0000000001890740 in BackendRun (port=0x7fd931056720) at postmaster.cpp:8053
#6 0x00000000018a00b1 in GaussDbThreadMain<(knl_thread_role)1> (arg=0x7fd97c55c5f0) at postmaster.cpp:12181
#7 0x000000000189c0de in InternalThreadFunc (args=0x7fd97c55c5f0) at postmaster.cpp:12755
#8 0x00000000024bf7d8 in ThreadStarterFunc (arg=0x7fd97c55c5e0) at gs_thread.cpp:382
#9 0x00007fd9a60cfdd5 in start_thread () from /lib64/libpthread.so.0
#10 0x00007fd9a5df8ead in clone () from /lib64/libc.so.6
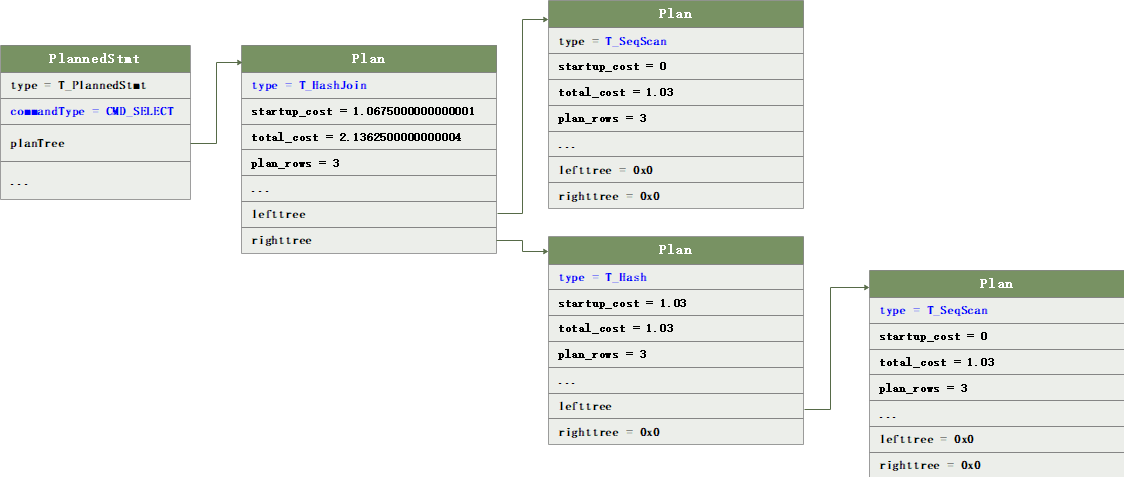
(gdb) p *result
$14 = {type = T_PlannedStmt, commandType = CMD_SELECT, queryId = 0, hasReturning = false, hasModifyingCTE = false, canSetTag = true, transientPlan = false, dependsOnRole = false,
planTree = 0x7fd93a409d58, rtable = 0x7fd939b81660, …}
(gdb) p *result->planTree->lefttree
$46 = {type = T_SeqScan, plan_node_id = 2, parent_node_id = 1, exec_type = EXEC_ON_DATANODES, startup_cost = 0, total_cost = 1.03, plan_rows = 3, multiple = 1, plan_width = 8,…}
将Query规划后得到PlannedStmt
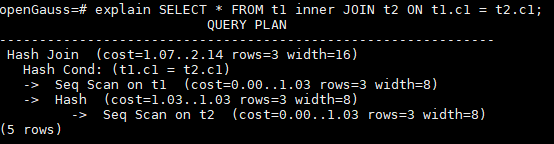
可以看到,Plannedstmt 与explain执行计划是一致的
openGauss内核分析:执行计划生成的更多相关文章
- spark sql 执行计划生成案例
前言 一个SQL从词法解析.语法解析.逻辑执行计划.物理执行计划最终转换为可以执行的RDD,中间经历了很多的步骤和流程.其中词法分析和语法分析均有ANTLR4完成,可以进一步学习ANTLR4的相关知识 ...
- sqlplus 分析执行计划
转载 http://xm-koma.iteye.com/blog/1048451 对于oracle9i,需要手工设置plustrace角色,步骤如下: 1.在SQL>connect sys/密码 ...
- 索引使用,分析初探。(explain分析执行计划,以及强制使用force index)
促使这次探索的初衷还是因为要对一个定时脚本性能进行优化. 脚本有两个指定状态分别是status, latest_process_status,和一个超期时间expire_time进行限制. 按照我以前 ...
- SQL Sever 2008性能分析之执行计划
一直想找一些关于SQL语句性能调试的权威参考,但是有参考未必就能够做好调试 2的工作.我深信实践中得到的经验是最珍贵的,书本知识只是一个引导.本篇来源于<Inside Microsoft SQL ...
- Oracle中获取执行计划的几种方法分析
以下是对Oracle中获取执行计划的几种方法进行了详细的分析介绍,需要的朋友可以参考下 1. 预估执行计划 - Explain PlanExplain plan以SQL语句作为输入,得到这条S ...
- SQL点滴27—性能分析之执行计划
原文:SQL点滴27-性能分析之执行计划 一直想找一些关于SQL语句性能调试的权威参考,但是有参考未必就能够做好调试的工作.我深信实践中得到的经验是最珍贵的,书本知识只是一个引导.本篇来源于<I ...
- SQL性能分析之执行计划
一直想找一些关于SQL语句性能调试的权威参考,但是有参考未必就能够做好调试的工作.我深信实践中得到的经验是最珍贵的,书本知识只是一个引导.本篇来源于<Inside Microsoft SQL S ...
- SQL Server 执行计划分析
当一个查询到达数据库引擎时,SQL Server执行两个主要的步骤来产生期望的查询结果: 第一步:查询编译,生成查询计划. 第二步:执行这个查询计划. 1. 用于演示分析执行计划的查询语句 /* 查询 ...
- 分析oracle的执行计划(explain plan)并对对sql进行优化实践
基于oracle的应用系统很多性能问题,是由应用系统sql性能低劣引起的,所以,sql的性能优化很重要,分析与优化sql的性能我们一般通过查看该sql的执行计划,本文就如何看懂执行计划,以及如何通过分 ...
- SqlServer 中如何查看某一个Sql语句是复用了执行计划,还是重新生成了执行计划
我们知道SqlServer的查询优化器会将所执行的Sql语句的执行计划作缓存,如果后续查询可以复用缓存中的执行计划,那么SqlServer就会为后续查询复用执行计划而不是重新生成一个新的执行计划,因为 ...
随机推荐
- 合并果子(lgP1090)
贪心. 每次取最小的两堆合并,最后即为正确答案.(我也不会证明/wq) 所以说主要问题就是怎么找最小的两堆. 由于中间不断有插入和删除,所以用优先队列. 扯不下去了 直接看代码吧. #include& ...
- 2022-10-22 CSP赛前隔离时的模拟赛 2:3
T1 简单红题,不懈于写. 锐评:镜子反射出来的竟然没有镜像一下. T2 坑人东西调了 2h. 类似于 round1 的 T4. 线性 \(\Theta(n)\) 过. T3 T4 其实简单,负边权要 ...
- 2D物理引擎 Box2D for javascript Games 第六章 关节和马达
2D物理引擎 Box2D for javascript Games 第六章 关节和马达 关节和马达 到现在你所见到的所有类型的刚体有着一些共同点:它们都是自由的并且在除碰撞的请款之外,彼此没有依赖. ...
- 一个类似于Gridster的栅格布局系统Vue组件
哈喽,我是老鱼,一名致力于在技术道路上的终身学习者.实践者.分享者! Vue Grid Layout是一个类似于Gridster的栅格布局系统, 适用于Vue.js,灵感来源于React Grid L ...
- @ApiImplicitParam dataType属性失效
最近在弄swagger,老是碰到注解属性失效问题.百度看了一大推,都是说什么版本问题.但是都不是我遇到的情况,下面直接上我遇到的问题及答案 可以看到,我直接用Integer,或者int,去到swa ...
- 搓一个Pythonic list
总所周知,Python语言当中的list是可以存储不同类型的元素的,对应到现代C++当中,可以用std::variant或者std::any实现类似的功能.而Python官方的实现当中用到了二级指 ...
- coco漫画获取隐藏的图片链接
网站分析 打开目标网站:https://www.cocomanhua.com/, 随便打开一部漫画: https://www.cocomanhua.com/10330/1/205.html F12 打 ...
- el-table 多表格弹窗嵌套数据显示异常错乱问题
1.业务背景 使用vue+element开发报表功能时,需要列表上某列的超链接按钮弹窗展示,在弹窗的el-table列表某列中再次使用超链接按钮点开弹窗,以此类推多表格弹窗嵌套,本文以弹窗两次为例 最 ...
- UVA529 加成序列
传送门 题目分析 一道 dfs,迭代加深 我们可以很快的猜出来最终 \(m\) 的长度必然是小于 \(10\) 的. 而这种浅深度的问题正好适用于迭代加深. 之后考虑剪枝 优化搜索顺序 : 我们要让序 ...
- 文心一言 VS 讯飞星火 VS chatgpt (140)-- 算法导论11.4 5题
五.用go语言,考虑一个装载因子为a的开放寻址散列表.找出一个非零的a值,使得一次不成功查找的探查期望数是一次成功查找的探查期望数的 2 倍.这两个探查期望数可以使用定理11.6 和定理 11.8 中 ...