bucket表:数仓存算分离中CU与DN解绑的关键
摘要:Bucket存储是数据共享中重要的一环,当前阶段,bucket存储可以将列存中的CU数据和DN节点解绑。
本文分享自华为云社区《存算分离之bucket表——【玩转PB级数仓GaussDB(DWS)】》,作者:yd_278301229 。
在云原生环境,用户可以自由配置cup型号、内存、磁盘、带宽等资源,需要在计算和IO之间做平衡;如果计算和存储耦合,扩缩容时数据要在节点之间移动,同时还要对外提供计算,性能会大受影响。如果存算分离,计算出和存储层可以独立增加节点互不干扰,这其中一个关键点是做到数据共享。Bucket存储是数据共享中重要的一环,当前阶段,bucket存储可以将列存中的CU数据和DN节点解绑。
一、bucket表在存算分离中的作用
通过存算分离,把DWS完全的shared nothing架构改造成计算层shared nothing + 存储层shared storage。使用OBS替换EVS,OBS对append only存储友好,与列存CU存储天然适配;由于存算分离数据共享,对写的并发性能不高,在OLAP场景下读多写少更有优势,这一点也是和列存相匹配的,目前主要实现的是列存的存算分。
在当前。bucket表在存储层共享中,为了将CU数据和DN节点解绑,主要做了两件关键的事,CUID和FILEID全局统一管理。我们来看看为什么这两件事能把CU和DN节点解绑以及带来的好处。
为了解释这个问题,先看看目前shared nothing架构中,建库和存储数据的过程。
二,当建立一张列存表并存储数据时,我们在做什么
建一张列存表时,主要要做以下两步:
1,系统表中建立表的数据。
2,为列存建立CUDesc表、Delta表等辅助表
当存储数据时,主要做以下几步:
1,根据数据分布方式,决定数据存储到哪个DN。
2,把列存存储时需要的辅助信息填入CUDesc表、Delta表等辅助表。
3,把存储用户数据的CU存储本地DN。
在上面的过程中,由于DN之间互不干扰,那就需要各自管理自己的存储的表的信息。
CUDesc表的一大功能是CU数据的“指路牌”,就像指针一样,指出CU数据存储的位置。靠的是CUID对应的CUPoint(偏移量),加上存储在DN的文件位置就能标注出具体的CU数据,而文件名就是系统表中的relfilenode。
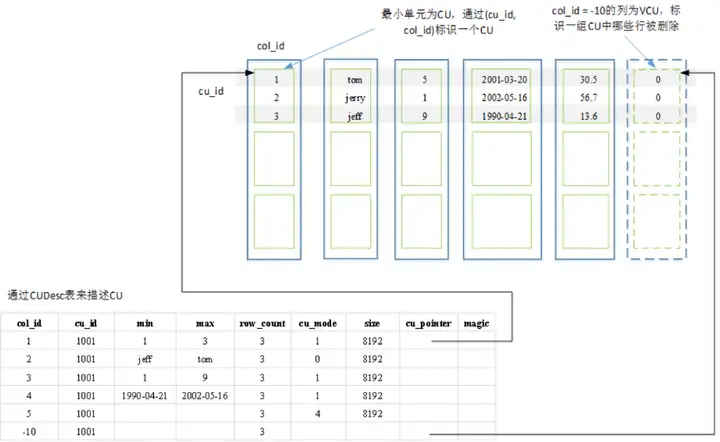
由于在MPPDB的存算一体中,数据都存储在DN节点,DN节点之间互不干扰,CUID和relfilenode各个DN节点自己管理,只要自己不出问题就行了,也就是“各人自扫门前雪莫管他人瓦上霜”,例如下图,显示一张列存表在集群中的存储状态。
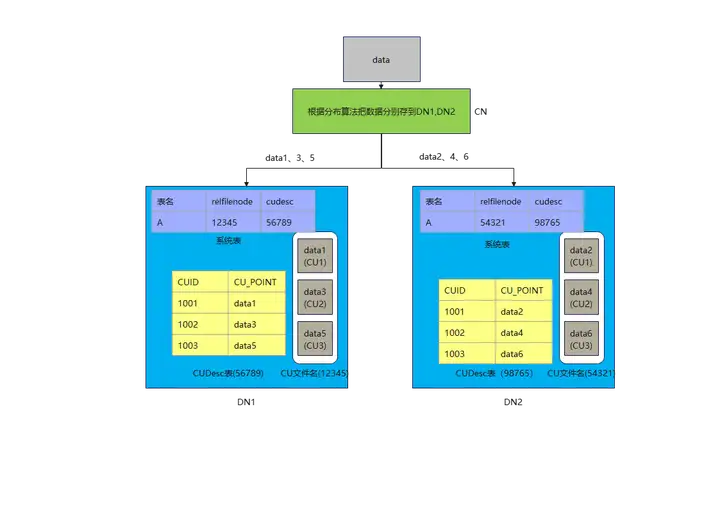
CN把要存储的数据根据分布算法(例如对DN数量做除法取余数)把1,3,5存到DN1,把2,4,6存到DN2。DN1此时生成存储CU文件的relfilenode是12345,每插入一次CUID,就把该表的CUDesc表CUID自增,DN1只要把自己的数据管理好,与DN2无关。DN2同理。
三,数据共享和扩缩容时,遇到的困难
1,数据共享时遇到的困难
如上所述,当用户想查询数据1,2,4,6时,该怎么办。因为DN1和DN2都不可能单独完成任务,就需要共享数据了。问题就来了,DN间肯定是想以最小代价来完成数据共享,系统表最小,CUDesc表也很小(就像指针一样,同等规模下,只有CU数据的1/3000左右),CU数据最大。假如最后决定以DN2来汇聚所有结果,就算DN1把系统表和CUDesc表中的数据传给DN2,DN2也看不懂,因为在DN2上,relfilenode为12345可能是另外一张表,cudesc表为中CUID为1001的CUPoint也不知道是指向哪儿了(data1,data2),没办法,只能是DN1自己计算,最后把data1的CU数据通过stream算子发送给DN2。DN1迫不得已选了最难的那条路,CU的数据量太大,占用了网络带宽,还需要DN1来参与计算,并发上不去。
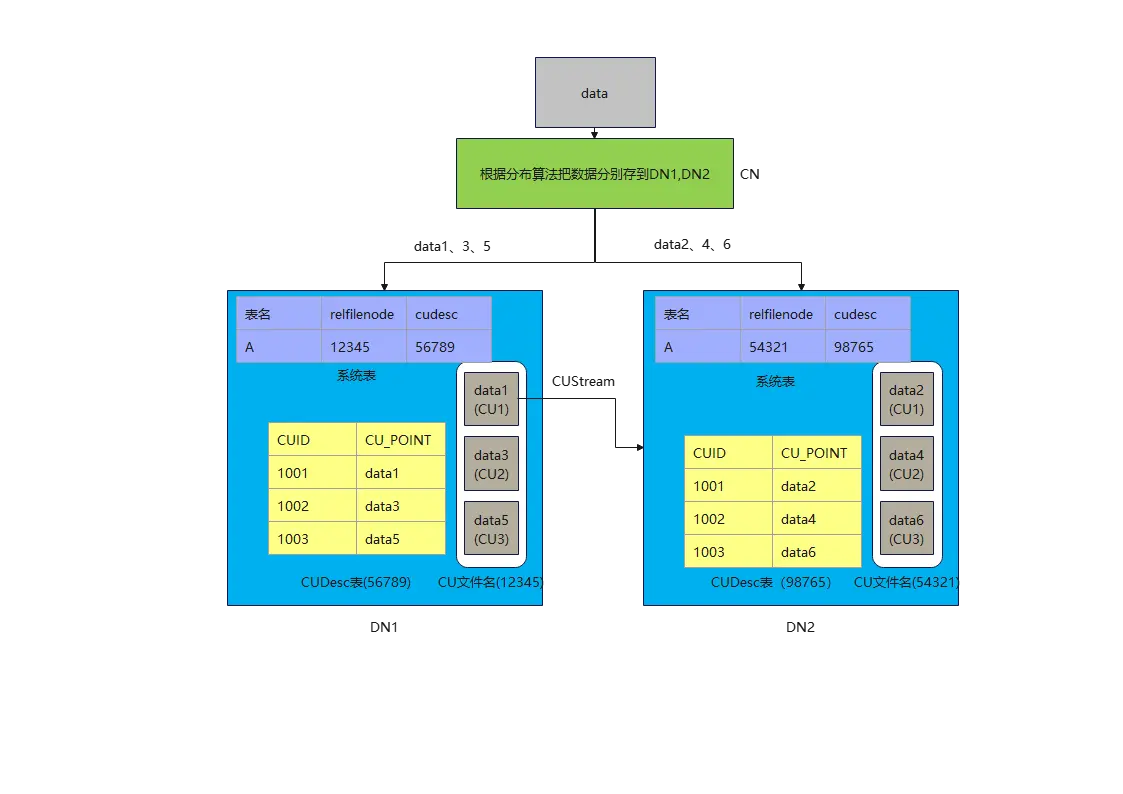
2,扩缩容时遇到的困难
当用户发现DN1,DN2节点不够用时,想要一个DN3,该怎么办。根据分布假设的算法(对DN数量做除法取余数),data3和data6应该要搬去DN3才对。系统表还比较好搬,无非是在DN3上新建一份数据,CUDesc表也好搬,因为数据量小,再把CUID和CUPoint按照DN3的逻辑写上数据就好了,CU数据也要搬,但是因为CU数据量大,会占用过多的计算资源和带宽,同时还要对外提供计算。真是打了几份工,就赚一份工资。

总结起来,困难主要是
1)系统表元数据(计算元数据)
每个节点有自己的系统表元数据,新增dn必须创建“自己方言”的系统表,而实际上这些系统表内容是“相同的”,但是dn之间互相不理解;
2)CUDesc元数据(存储元数据)
每个节点的CUID自己分配,同一个CUID在不同节点指向不同的数据,CU无法在dn之间迁移,因为迁移后会混乱,必须通过数据重分布生成dn “自己方言的CUID”
CU的可见性信息(clog/csnlog)各自独立管理,dn1读取dn2的cudesc行记录之后,不知道记录是否可见
3)CU用户数据
filepath(relfilenode) dn节点各自独立管理,dn1不知道到哪里读取dn2的数据
四、揭秘CU与DN解绑的关键——bucket表
1,存储映射
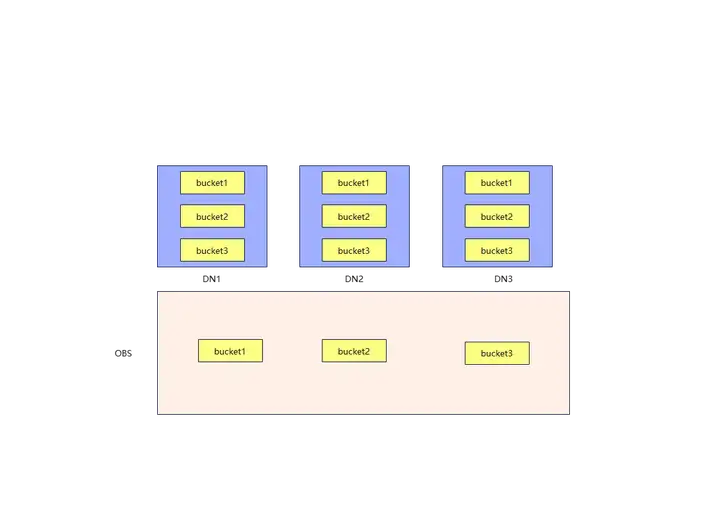
bucket表的存储方式如图,CU的管理粒度不再是DN,而是bucket,bucket是抽象出来的一个概念,DN存储的,是系统元数据和bucket对应的CUDesc元数据,由于在bucket作为存储粒度下,CUID和FILEID是全局统一管理的,DN只需要懂全局的规则,并且拿到别的bucket对应的CUDesc元数据,那就可以很方便的去OBS上拿到CU数据了。通过这种方式,把本该存储在DN上的CU数据,映射到OBS上,可以保证DN间共享数据时相互独立,换句话说,每个DN都读的懂其他DN的CUDesc数据,不再需要把CU数据喂到嘴边了。
2,全局CUID和FILEID表生成
CUID不再是各节点自己管理生成,而是全局唯一的。其原因是CUID与bucket号绑定,特定的bucket号只能生成特定的globalCUID,与此同时,relfilenode不再作为存储的文件名,而是作为存储路径。CU存放的文件名为relfilenode/C1_fileId.0,fileId的计算只与bukcet号和seqno有关。
这样V3表就建立起了一套映射关系(以V2表示存算一体表,V3表示为bucket表):
step 1,数据插入哪一个bucket由分布方式来确定,例如是RR分布,那么就是轮巡插入bucket。
step 2,CUID是多少,由bucket粒度级别的CUID来确定,比如+1自增作为下一个CUID。
step 3,在bucket上存储bucket粒度级别的fileId。
step 4,生成全局唯一fileId,由bucketid和bucket粒度级别的fileId来生成,对应生成的CU插入该fileId文件名的文件。
setp 5,生成全局唯一globalCUID。由bucketid和bucket粒度级别的CUID计算得到全局唯一的globalCUID。
CUDesc表中,也为bucket表新建了一个属性fileId,用来让DN查找到OBS上的CU数据所在的文件。

3,共享数据和扩缩容的便利
如上所述,DN可以通过全局CUID和FILEID来找到CU数据,在数据共享时,不再需要其他DN参与大量的计算和搬迁CU,扩缩容时,也不需要搬迁CU了,只需要正确生成系统表中的信息和搬迁CUDesc即可。
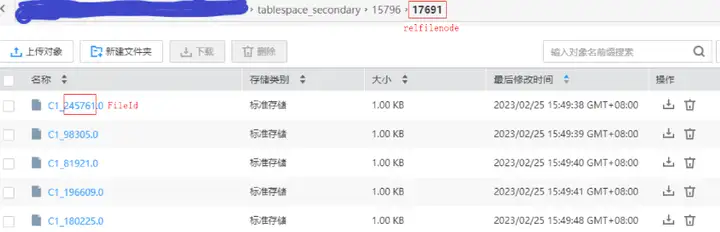
最后,来看一看bucket表在OBS上存储的CU数据:
bucket表:数仓存算分离中CU与DN解绑的关键的更多相关文章
- ClickHouse 存算分离架构探索
背景 ClickHouse 作为开源 OLAP 引擎,因其出色的性能表现在大数据生态中得到了广泛的应用.区别于 Hadoop 生态组件通常依赖 HDFS 作为底层的数据存储,ClickHouse 使用 ...
- 从 Hadoop 到云原生, 大数据平台如何做存算分离
Hadoop 的诞生改变了企业对数据的存储.处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变:随着云计算时代的到来, 存算分离的架构受到青睐,企业开开始对 Hado ...
- 存算分离下写性能提升10倍以上,EMR Spark引擎是如何做到的?
引言 随着大数据技术架构的演进,存储与计算分离的架构能更好的满足用户对降低数据存储成本,按需调度计算资源的诉求,正在成为越来越多人的选择.相较 HDFS,数据存储在对象存储上可以节约存储成本,但与此 ...
- 存算分离实践:JuiceFS 在中国电信日均 PB 级数据场景的应用
01- 大数据运营的挑战 & 升级思考 大数据运营面临的挑战 中国电信大数据集群每日数据量庞大,单个业务单日量级可达到 PB 级别,且存在大量过期数据(冷数据).冗余数据,存储压力大:每个省公 ...
- 腾讯云 CHDFS — 云端大数据存算分离的基石
随着网络性能提升,云端计算架构逐步向存算分离转变,AWS Aurora 率先在数据库领域实现了这个转变,大数据计算领域也迅速朝此方向演化. 存算分离在云端有明显优势,不但可以充分发挥弹性计算的灵活,同 ...
- ByteHouse云数仓版查询性能优化和MySQL生态完善
ByteHouse云数仓版是字节跳动数据平台团队在复用开源 ClickHouse runtime 的基础上,基于云原生架构重构设计,并新增和优化了大量功能.在字节内部,ByteHouse被广泛用于各类 ...
- 数仓建设 | ODS、DWD、DWM等理论实战(好文收藏)
本文目录: 一.数据流向 二.应用示例 三.何为数仓DW 四.为何要分层 五.数据分层 六.数据集市 七.问题总结 导读 数仓在建设过程中,对数据的组织管理上,不仅要根据业务进行纵向的主题域划分,还需 ...
- 文盘Rust -- rust 连接云上数仓 starwift
作者:京东云 贾世闻 最近想看看 rust 如何集成 clickhouse,又犯了好吃懒做的心理(不想自己建环境),刚好京东云发布了兼容ck 的云原生数仓 Starwfit,于是搞了个实例折腾一番. ...
- 数仓建模—建模工具PdMan(CHINER)介绍
数据仓库系列文章(持续更新) 数仓架构发展史 数仓建模方法论 数仓建模分层理论 数仓建模-宽表的设计 数仓建模-指标体系 数据仓库之拉链表 数仓-数据集成 数仓-数据集市 数仓-商业智能系统 数仓-埋 ...
- 【大数据面试】【数仓项目】分层:ODS层、DWD层、DWS层、ADS层构成、操作
一.ODS层 1.保持数据原貌,不做任何修改 2.数据压缩:LZO压缩,减少磁盘空间 3.创建的是分区表:可以防止后续的全表扫描 包括 用户行为:string line dt ods_start ...
随机推荐
- html部分兼容性总结
部分兼容性总结一下: 1.background-color的兼容性: 火狐正常,可以同时在后面加上!important(只有火狐识别,其他的不识别,火狐优先,位置必须放在开头). IE,谷歌,360, ...
- mysql语句操作
1.从login表中选出name字段包含admin的前10条结果所有信息的sql语句 select * from login where name like %admin% limit 0 ,10; ...
- 关于STM32F407ZGT6的USB损坏后使用ST-Link和USART1实现串口功能
开发板:STM32F407ZGT6: 目标:想使用软件"串口调试助手" 情况:开发板上的USB_UART口所在器件损坏或者直接没有: 解决办法:查看该开发板的原理图,可得:串口1的 ...
- Molecule 在构建工具中的选择
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品.我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值. 本文作者:修能 朝闻道,夕死可矣 何为 Molecule? 轻量级的 ...
- 一篇适合躺收藏夹的 Nexus3 搭建 NuGet&Docker 私有库的安装使用总结
前言 Nexus 是支持 Nuget.Docker.Npm 等多种包的仓库管理器,可用做私有包的存储分发,缓存官方包.本篇将手把手教学使用 Nexus 搭建自己的 NuGe t& Docker ...
- Vue 2.x源码学习:render方法、模板解析和依赖收集
内容乃本人学习Vue2源码的一点笔记,若有错误还望指正. 源码版本: vue: 2.6 vue-loader: 13.x vue-template-compiler: 2.6 之前的相关学习笔记: 应 ...
- P2360 地下城主
题目大意 背景是逃离\(3D\)地下监狱,也就是三维样例,你可以前往所在小格的前方,后方,左方,右方,上层,下层的小格,'.'表示可走,'x'表示墙壁,'S'表示起点,'E'表示终点.每走一小格花费一 ...
- Ubuntu 20.04 挂载局域网络共享硬盘
创建挂载目录 mkdir /media/nas 创建认证文件.若无密码可以忽略这一步. sudo vim /root/.examplecredentials 按照以下格式写入用户名密码: userna ...
- linux登陆防护fail2ban的优化配置
fail2ban 默认在iptables 防火墙filter表的input 链内设置规则,这样导致端口映射,和nat转发的流量不在fail2ban控制内. 如果修改配置文件/etc/fail2ban/ ...
- 12k Star、40万+开发者信赖的开源商城系统
前几天,有位读者问我有没有什么优秀的国产开源电商平台,他要拿来接单赚外快.我一听这话,精神头就来了. 所以,今天 HelloGitHub 就给大家找来了一款自用.二开都很方便的国产开源商城系统--CR ...