DataLeap的Catalog系统近实时消息同步能力优化
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
摘要
字节数据中台DataLeap的Data Catalog系统通过接收MQ中的近实时消息来同步部分元数据。Apache Atlas对于实时消息的消费处理不满足性能要求,内部使用Flink任务的处理方案在ToB场景中也存在诸多限制,所以团队自研了轻量级异步消息处理框架,很好的支持了字节内部和火山引擎上同步元数据的诉求。本文定义了需求场景,并详细介绍框架的设计与实现。
背景
动机
字节数据中台DataLeap的Data Catalog系统基于Apache Atlas搭建,其中Atlas通过Kafka获取外部系统的元数据变更消息。在开源版本中,每台服务器支持的Kafka Consumer数量有限,在每日百万级消息体量下,经常有长延时等问题,影响用户体验。
在2020年底,我们针对Atlas的消息消费部分做了重构,将消息的消费和处理从后端服务中剥离出来,并编写了Flink任务承担这部分工作,比较好的解决了扩展性和性能问题。然而,到2021年年中,团队开始重点投入私有化部署和火山公有云支持,对于Flink集群的依赖引入了可维护性的痛点。
在仔细的分析了使用场景和需求,并调研了现成的解决方案后,我们决定投入人力自研一个消息处理框架。当前这个框架很好的支持了字节内部以及ToB场景中Data Catalog对于消息消费和处理的场景。
本文会详细介绍框架解决的问题,整体的设计,以及实现中的关键决定。
需求定义
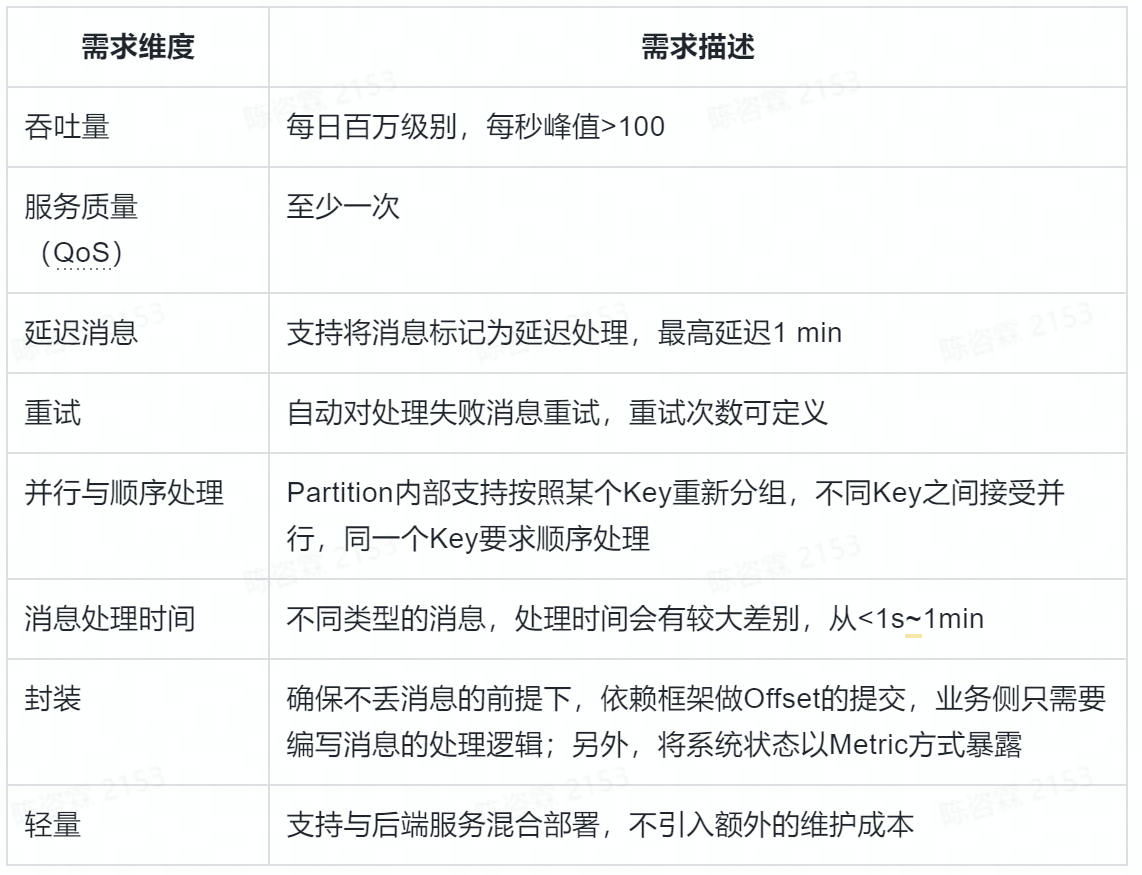
使用下面的表格将具体场景定义清楚。
相关工作
在启动自研之前,我们评估了两个比较相关的方案,分别是Flink和Kafka Streaming。
Flink是我们之前生产上使用的方案,在能力上是符合要求的,最主要的问题是长期的可维护性。在公有云场景,那个阶段Flink服务在火山云上还没有发布,我们自己的服务又有严格的时间线,所以必须考虑替代;在私有化场景,我们不确认客户的环境一定有Flink集群,即使部署的数据底座中带有Flink,后续的维护也是个头疼的问题。另外一个角度,作为通用流式处理框架,Flink的大部分功能其实我们并没有用到,对于单条消息的流转路径,其实只是简单的读取和处理,使用Flink有些“杀鸡用牛刀”了。
另外一个比较标准的方案是Kafka Streaming。作为Kafka官方提供的框架,对于流式处理的语义有较好的支持,也满足我们对于轻量的诉求。最终没有采用的主要考虑点是两个:
对于Offset的维护不够灵活:我们的场景不能使用自动提交(会丢消息),而对于同一个Partition中的数据又要求一定程度的并行处理,使用Kafka Streaming的原生接口较难支持。
与Kafka强绑定:大部分场景下,我们团队不是元数据消息队列的拥有者,也有团队使用RocketMQ等提供元数据变更,在应用层,我们希望使用同一套框架兼容。
设计
概念说明
MQ Type:Message Queue的类型,比如Kafka与RocketMQ。后续内容以Kafka为主,设计一定程度兼容其他MQ。
Topic:一批消息的集合,包含多个Partition,可以被多个Consumer Group消费。
Consumer Group:一组Consumer,同一Group内的Consumer数据不会重复消费。
Consumer:消费消息的最小单位,属于某个Consumer Group。
Partition:Topic中的一部分数据,同一Partition内消息有序。同一Consumer Group内,一个Partition只会被其中一个Consumer消费。
Event:由Topic中的消息转换而来,部分属性如下。
Event Type:消息的类型定义,会与Processor有对应关系;
Event Key:包含消息Topic、Partition、Offset等元数据,用来对消息进行Hash操作;
Processor:消息处理的单元,针对某个Event Type定制的业务逻辑。
Task:消费消息并处理的一条Pipeline,Task之间资源是相互独立的。
框架架构
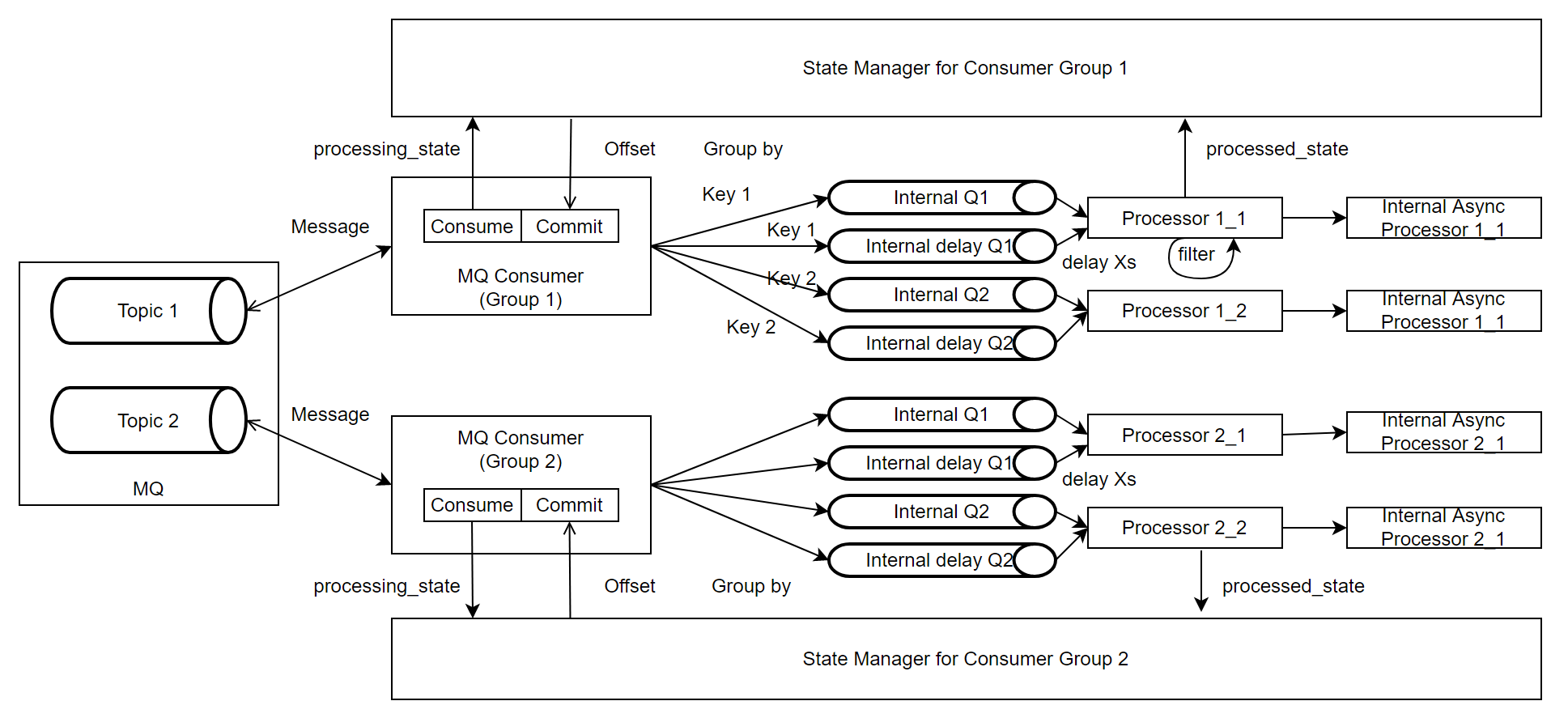
整个框架主要由MQ Consumer, Message Processor和State Manager组成。
MQ Consumer:负责从Kafka Topic拉取消息,并根据Event Key将消息投放到内部队列,如果消息需要延时消费,会被投放到对应的延时队列;该模块还负责定时查询State Manager中记录的消息状态,并根据返回提交消息Offset;上报与消息消费相关的Metric。
Message Processor:负责从队列中拉取消息并异步进行处理,它会将消息的处理结果更新给State Manager,同时上报与消息处理相关的Metric。
State Manager:负责维护每个Kafka Partition的消息状态,并暴露当前应提交的Offset信息给MQ Consumer。
实现
线程模型

每个Task可以运行在一台或多台实例,建议部署到多台机器,以获得更好的性能和容错能力。
每台实例中,存在两组线程池:
Consumer Pool:负责管理MQ Consumer Thread的生命周期,当服务启动时,根据配置拉起一定规模的线程,并在服务关闭时确保每个Thread安全退出或者超时停止。整体有效Thread的上限与Topic的Partition的总数有关。
Processor Pool:负责管理Message Processor Thread的生命周期,当服务启动时,根据配置拉起一定规模的线程,并在服务关闭时确保每个Thread安全退出或者超时停止。可以根据Event Type所需要处理的并行度来灵活配置。
两类Thread的性质分别如下:
Consumer Thread:每个MQ Consumer会封装一个Kafka Consumer,可以消费0个或者多个Partition。根据Kafka的机制,当MQ Consumer Thread的个数超过Partition的个数时,当前Thread不会有实际流量。
Processor Thread:唯一对应一个内部的队列,并以FIFO的方式消费和处理其中的消息。
StateManager
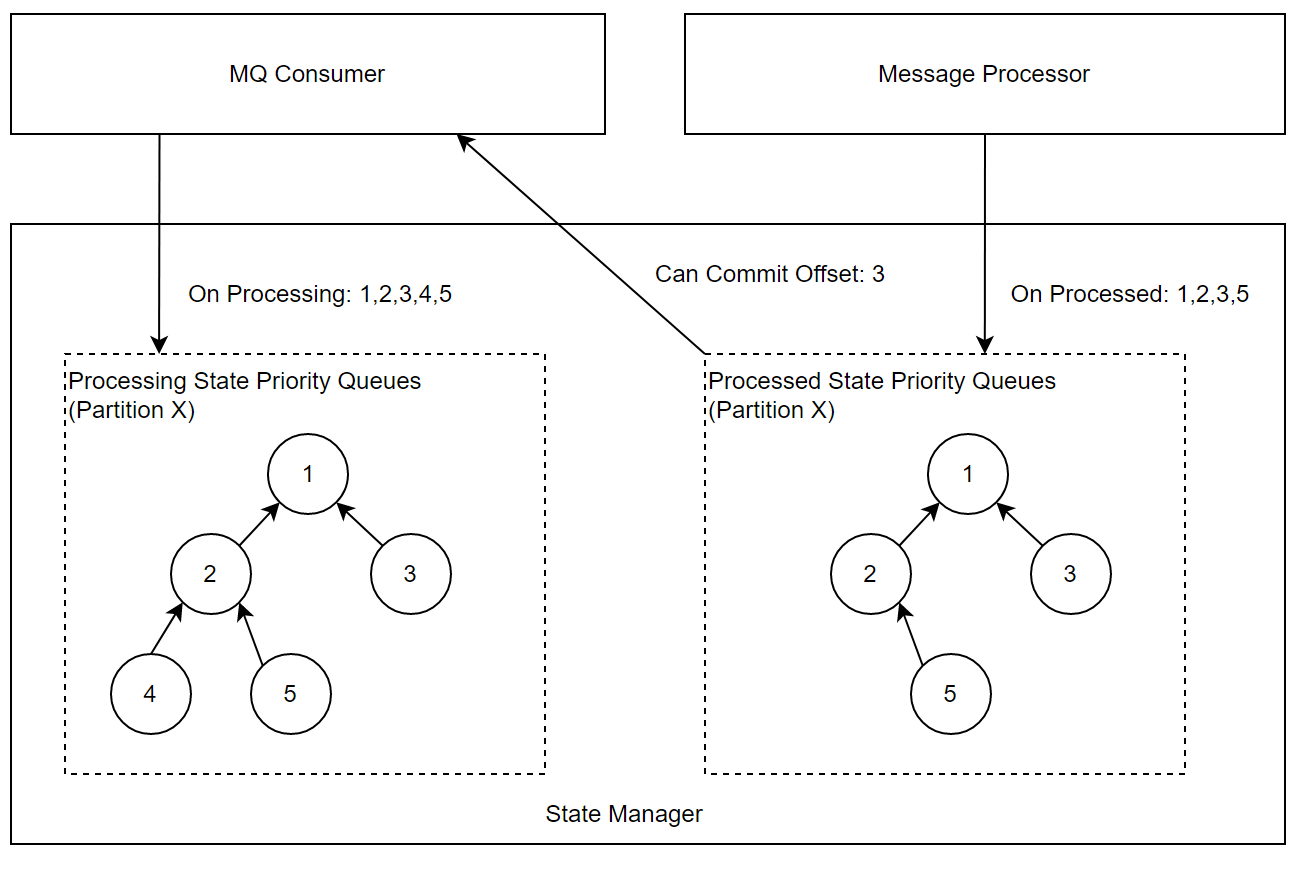
在State Manager中,会为每个Partition维护一个优先队列(最小堆),队列中的信息是Offset,两个优先队列的职责如下:
处理中的队列:一条消息转化为Event后,MQ Consumer会调用StateManager接口,将消息Offset 插入该队列。
处理完的队列:一条消息处理结束或最终失败,Message Processor会调用StateManager接口,将消息Offset插入该队列。
MQ Consumer会周期性的检查当前可以Commit的Offset,情况枚举如下:
处理中的队列堆顶 < 处理完的队列堆顶或者处理完的队列为空:代表当前消费回来的消息还在处理过程中,本轮不做Offset提交。
处理中的队列堆顶 = 处理完的队列堆顶:表示当前消息已经处理完,两边同时出队,并记录当前堆顶为可提交的Offset,重复检查过程。
处理中的队列堆顶 > 处理完的队列堆顶:异常情况,通常是数据回放到某些中间状态,将处理完的队列堆顶出堆。
注意:当发生Consumer的Rebalance时,需要将对应Partition的队列清空
KeyBy与Delay Processing的支持
因源头的Topic和消息格式有可能不可控制,所以MQ Consumer的职责之一是将消息统一封装为Event。
根据需求,会从原始消息中拼装出Event Key,对Key取Hash后,相同结果的Event会进入同一个队列,可以保证分区内的此类事件处理顺序的稳定,同时将消息的消费与处理解耦,支持增大内部队列数量来增加吞吐。
Event中也支持设置是否延迟处理属性,可以根据Event Time延迟固定时间后处理,需要被延迟处理的事件会被发送到有界延迟队列中,有界延迟队列的实现继承了DelayQueue,限制DelayQueue长度, 达到限定值入队会被阻塞。
异常处理
Processor在消息处理过程中,可能遇到各种异常情况,设计框架的动机之一就是为业务逻辑的编写者屏蔽掉这种复杂度。Processor相关框架的逻辑会与State Manager协作,处理异常并充分暴露状态。比较典型的异常情况以及处理策略如下:
处理消息失败:自动触发重试,重试到用户设置的最大次数或默认值后会将消息失败状态通知State Manager。
处理消息超时:超时对于吞吐影响较大,且通常重试的效果不明显,因此当前策略是不会对消息重试,直接通知State Manager 消息处理失败。
处理消息较慢:上游Topic存在Lag,Message Consumer消费速率大于Message Processor处理速率时,消息会堆积在队列中,达到队列最大长度,Message Consumer 会被阻塞在入队操作,停止拉取消息,类似Flink框架中的背压。
监控
为了方便运维,在框架层面暴露了一组监控指标,并支持用户自定义Metrics。其中默认支持的Metrics如下表所示:

线上运维Case举例
实际生产环境运行时,偶尔需要做些运维操作,其中最常见的是消息堆积和消息重放。
对于Conusmer Lag这类问题的处理步骤大致如下:
查看Enqueue Time,Queue Length的监控确定服务内队列是否有堆积。
如果队列有堆积,查看Process Time指标,确定是否是某个Processor处理慢,如果是,根据指标中的Tag 确定事件类型等属性特征,判断业务逻辑或者Key设置是否合理;全部Processor 处理慢,可以通过增加Processor并行度来解决。
如果队列无堆积,排除网络问题后,可以考虑增加Consumer并行度至Topic Partition 上限。
消息重放被触发的原因通常有两种,要么是业务上需要重放部分数据做补全,要么是遇到了事故需要修复数据。为了应对这种需求,我们在框架层面支持了根据时间戳重置Offset的能力。具体操作时的步骤如下:
使用服务测暴露的API,启动一台实例使用新的Consumer GroupId: {newConsumerGroup} 从某个startupTimestamp开始消费
更改全部配置中的 Consumer GroupId 为 {newConsumerGroup}
分批重启所有实例
总结
为了解决字节数据中台DataLeap中Data Catalog系统消费近实时元数据变更的业务场景,我们自研了轻量级消息处理框架。当前该框架已在字节内部生产环境稳定运行超过1年,并支持了火山引擎上的数据地图服务的元数据同步场景,满足了我们团队的需求。
下一步会根据优先级排期支持RocketMQ等其他消息队列,并持续优化配置动态更新,监控报警,运维自动化等方面。
DataLeap的Catalog系统近实时消息同步能力优化的更多相关文章
- Vue 结合 SignalR 实现前后端实时消息同步
最近业务中需要实现服务器端与客户端的实时通信功能,对Signalr做了一点总结和整理. SignalR 作为 ASP.NET 的一个库,能够简单方便地为应用提供实时的服务器端与客户端双向通信功能. ...
- 基于Canal和Kafka实现MySQL的Binlog近实时同步
前提 近段时间,业务系统架构基本完备,数据层面的建设比较薄弱,因为笔者目前工作重心在于搭建一个小型的数据平台.优先级比较高的一个任务就是需要近实时同步业务系统的数据(包括保存.更新或者软删除)到一个另 ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 开源实时消息推送系统 MPush
系统介绍 mpush,是一款开源的实时消息推送系统,采用java语言开发,服务端采用模块化设计,具有协议简洁,传输安全,接口流畅,实时高效,扩展性强,可配置化,部署方便,监控完善等特点.同时也是少有的 ...
- Linux系统实时数据同步inotify+rsync
一.inotify简介 inotify是Linux内核的一个功能,它能监控文件系统的变化,比如删除.读.写和卸载等操作.它监控到这些事件的发生后会默认往标准输出打印事件信息.要使用inotify,Li ...
- alpakka-kafka(10)-用kafka实现分布式近实时交易
随着网上购物消费模式热度的不断提高,网上销售平台上各种促销手段也层出不穷,其中"秒购"已经是各种网站普遍流行的促销方式了."秒购"对数据的实效性和精确性要求非常 ...
- Tapdata 在线研讨会:实时数据同步应用场景及实现方案探讨
数字化时代的到来,企业业务敏捷度的提升,对传统的数据处理和可用性带来更高的要求,实时数据同步技术的发展,给基于数据的业务创新带来了更多的可能性.9月8日晚,Tapdata 联合MongoDB 中文社区 ...
- 我有 7种 实现web实时消息推送的方案,7种!
技术交流,公众号:程序员小富 大家好,我是小富- 我有一个朋友- 做了一个小破站,现在要实现一个站内信web消息推送的功能,对,就是下图这个小红点,一个很常用的功能. 不过他还没想好用什么方式做,这里 ...
- 7种实现web实时消息推送的方案
做了一个小破站,现在要实现一个站内信web消息推送的功能,对,就是下图这个小红点,一个很常用的功能. 不过他还没想好用什么方式做,这里我帮他整理了一下几种方案,并简单做了实现. 什么是消息推送(pus ...
- PHP Web实时消息后台服务器推送技术---GoEasy
越来越多的项目需要用到实时消息的推送与接收,怎样用php实现最方便呢?我这里推荐大家使用GoEasy, 它是一款第三方推送服务平台,使用它的API可以轻松搞定实时推送! 浏览器兼容性:GoEasy推送 ...
随机推荐
- 3种web会话管理的方式(session)
阅读目录 https://www.cnblogs.com/lyzg/p/6067766.html 1. 基于server端session的管理 2. cookie-based的管理方式 3. tok ...
- 微服务系列-基于Spring Cloud Eureka进行服务的注册与消费
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. 在之前的几个教程中,我们学了: 使用 RestTemplate 的 Spring Boot 微服务通信示例 使用 WebC ...
- python之特殊属性和特殊方法
目录 特殊属性 __dict__查看属性和方法 __class__查看对象所属类 __bases__查看子类的父类 __mro__查看类的层次结构 __subclasses__查看父类被继承的子类 特 ...
- C语言判断输入的正整数是否既是5又是7的整倍数。
#include<stdio.h> void main() { int n;//定义变量 while (1) { scanf_s("%d", &n); if ( ...
- 【scipy 基础】--稀疏矩阵
稀疏矩阵是一种特殊的矩阵,其非零元素数目远远少于零元素数目,并且非零元素分布没有规律.这种矩阵在实际应用中经常出现,例如在物理学.图形学和网络通信等领域. 稀疏矩阵其实也可以和一般的矩阵一样处理,之所 ...
- 【luogu题解】P9749 [CSP-J 2023] 公路
\(Meaning\) \(Solution\) 这道题我来讲一个不一样的解法:\(dp\) 在写 \(dp\) 之前,我们需要明确以下几个东西:状态的表示,状态转移方程,边界条件和答案的表示. 状态 ...
- AtCoder_abc328
A - Not Too Hard 题目链接 题目大意 给出\(N\)个数(\(S_1\) \(S_2\)...\(S_n\))和一个\(X\),输出所有小于等于\(X\)的\(S_i\)之和 解题思路 ...
- Linux笔记03: Linux常用命令_3.2目录操作命令
3.2 目录操作命令 3.2.1 ls命令 ●命令名称:ls. ●英文原意:list directory contents. ●所在路径:/usr/bin/ls. ●执行权限:所有用户. ●功能描述: ...
- [c/c++][考研复习笔记]内部排序篇学习笔记
考研排序复习笔记 插入排序 #include<stdio.h> #include<stdlib.h> #define MaxSize 9 //折半插入排序 void ZBIns ...
- Aop限流实现解决方案
01.限流 在业务场景中,为了限制某些业务的并发,造成接口的压力,需要增加限流功能. 02.限流的成熟解决方案 guava (漏斗算法 + 令牌算法) (单机限流) redis + lua + ip ...