hive中一般取top n时,row_number(),rank,dense_ran()常用三个函数
一、 分区函数Partition By与row_number()、rank()、dense_rank()的用法(获取分组(分区)中前几条记录)
一、数据准备

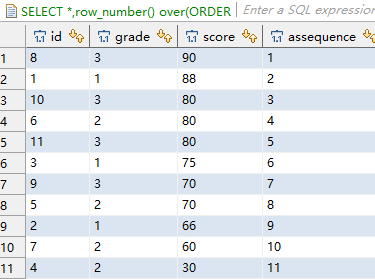
二、分区函数partition by与row_number()的用法
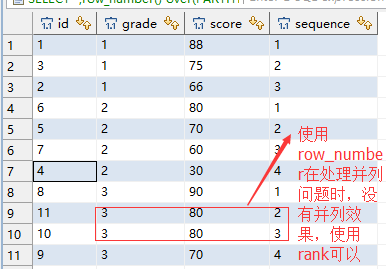
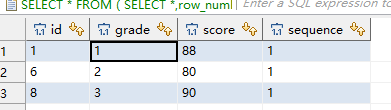
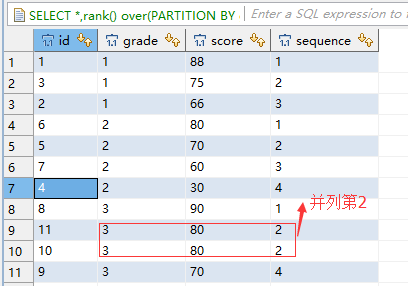
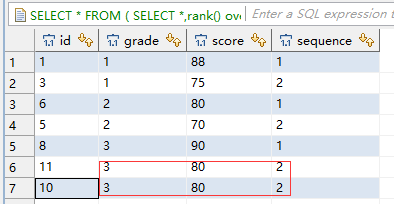
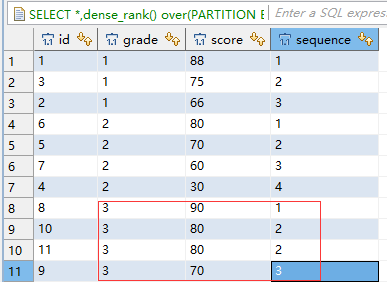
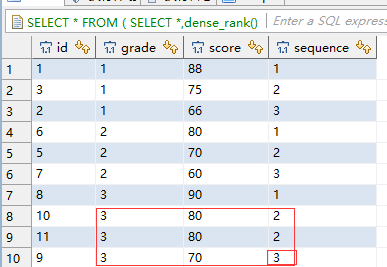
三、分区函数partition by与排序rank()的用法
hive中一般取top n时,row_number(),rank,dense_ran()常用三个函数的更多相关文章
- hive 中窗口函数row_number,rank,dense_ran,ntile分析函数的用法
hive中一般取top n时,row_number(),rank,dense_ran()这三个函数就派上用场了, 先简单说下这三函数都是排名的,不过呢还有点细微的区别. 通过代码运行结果一看就明白了. ...
- hive中分组取前N个值的实现
背景 假设有一个学生各门课的成绩的表单,应用hive取出每科成绩前100名的学生成绩. 这个就是典型在分组取Top N的需求. 解决思路 对于取出每科成绩前100名的学生成绩,针对学生成绩表,根据学科 ...
- hive分组排序 取top N
pig可以轻松获取TOP n.书上有例子 hive中比较麻烦,没有直接实现的函数,可以写udf实现.还有个比较简单的实现方法: 用row_number,生成排名序列号.然后外部分组后按这个序列号多虑, ...
- 在hive中查询导入数据表时FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
当我们出现这种情况时 FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least ...
- sqoop 从oracle导数据到hive中,date型数据时分秒截断问题
oracle数据库中Date类型倒入到hive中出现时分秒截断问题解决方案 1.问题描述: 用sqoop将oracle数据表倒入到hive中,oracle中Date型数据会出现时分秒截断问题,只保留了 ...
- 为什么在ucos向stm32f103移植时说os_cpu_c.c中有三个函数如OS_CPU_SysTickInit()需要注释掉
我在看os_cpu_c.c代码时对下面这段话困惑了半天总是在百度的帮助下找到了答案 /* 申明几个函数,这里要注意最后三个函数需要注释掉,为什么呢? OS_CPU_SysTickHandler ...
- Hive中使用Python实现Transform时遇到Broken pipe错误排查
Hive中有一表,列分隔符为冒号(:),有一列utime是Timestamp格式,需要转成Weekday存到新表. 利用Python写一个Pipeline的Transform,weekday.py的代 ...
- SQL Server 分组取 Top 笔记(row_number + over 实现)
先看SQL语句(注意:这是在SQL Server 2005+ [包括2005] 的版本才支持的哦,o(∩_∩)o 哈哈~) SELECT col1,col2,col3 FROM table1 AS a ...
- 从m个数中取top n
将题目具体一点,例如,从100个数中取出从大到小排前10的数 方法1:使用快速排序 因为快速排序一趟下来,小于K的数都在K的前面,大于K的数都在K的后面 如果,小于K的数有35个,大于K的数有64个 ...
随机推荐
- PyQt(Python+Qt)学习随笔:QListView的selectionRectVisible属性
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QListView的selectionRectVisible属性用于控制视图中的选择矩形框是否可见, ...
- PyQt(Python+Qt)学习随笔:Designer中属性设置界面的属性字体使用粗黑体的含义
老猿Python博文目录 老猿Python博客地址 使用了好几个月的Designer,今天才发现属性编辑界面的属性名有的为粗而黑,有的则不是,如图: 稍微测试了一下,发现是对属性值进行过调整,不再是缺 ...
- JS "&&"操作符妙用
首先来了解一下 "&&"操作符的工作原理: "&&"连接两个表达式,当两侧表达式都为真时,返回TRUE.有一个为假则返回FALS ...
- js数组快速排序和冒泡排序
1.快速排序 var arr = [1, 2, 5, 6, 3, 1, 4]; function mySort(arr) { if (arr.length <= 1) { return arr; ...
- 最简 Spring AOP 源码分析!
前言 最近在研究 Spring 源码,Spring 最核心的功能就是 IOC 容器和 AOP.本文定位是以最简的方式,分析 Spring AOP 源码. 基本概念 上面的思维导图能够概括了 Sprin ...
- spark有个节点特别慢,解决办法
除解决数据倾斜问题外,还要开启推测执行,寻找另一个executor执行task,哪个先完成就取哪个结果,再kill掉另一个.
- NPM相关知识点
1.Windows环境变量的配置 npm config set prefix "D:\Program Files\nodejs\node_global" npm config se ...
- linux之文本编辑器vi常用命令
由于经常在linux下面文本操作,所以这里稍微系统的总结一下自己常用的vi命令 1.打开命令: vi+filename (还有各种打开的姿势,只不过我比较顺手这个) 2.退出命令: :q 退出而 ...
- 安装VisualStudioCode
下载VisualStudioCode https://code.visualstudio.com/ 安装插件
- Docker(三):Docker安装MySQL
查找MySQL镜像 镜像仓库 https://hub.docker.com/ 下拉镜像 docker pull mysql:5.7 查看镜像 docker images 创建MySQL容器 命令式启动 ...