如何快速搭建hadoop集群
安装好虚拟机,重命名为master
配置网卡
命令:vi /etc/sysconfig/network-scripts/ifcfg-en(按tab键)
这里要配置ip,网关,域名解析
例如我的
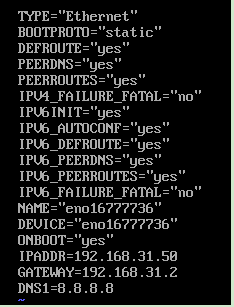
IPADDR=192.168.31.50
GATEWAY=192.168.31.2
DNS1=8.8.8.8
接着我们需要重启网卡才能生效
[root@localhost ~]# :service network restart
检验外网是否能连接
[root@localhost ~]#(以百度为例):ping www.baidu.com
(配置网卡完)
修改主机名(不能含有空格及特殊字符)
[root@localhost ~]# vi /etc/hostnname

添加映射(使三台虚拟机能够相互通信)
[root@localhost ~]# vi /etc/hosts

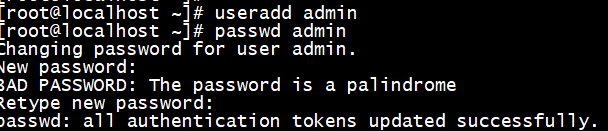
添加一个普通用户(admin),并设置密码
[root@localhost ~]# useradd admin
[root@localhost ~]# passwd admin
将我们添加的用户(admin)写入到配置文件中
[root@localhost ~]# visudo
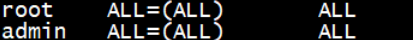
将hadoop和jdk的压缩包上传并解压
[root@localhost software]#tar -zxf hadoop-2.5.0.tar.gz -C /opt/modoules/
[root@localhost software]#tar -zxf jdk-7u79-linux-x64.tar.gz -C /opt/modoules/

将压缩文件修改为普通(admin)用户,并开放所有权限
[root@localhost modoules]#chown admin:admin -R hadoop-2.5.0/
[root@localhost modoules]#chown admin:admin -R jdk1.7.0_79/
[root@localhost modoules]# chmod 777 -R hadoop-2.5.0/
[root@localhost modoules]# chmod 777 -R jdk1.7.0_79/

添加配置文件
[root@localhost modoules]# vi /etc/profile

在hadoop-2.5.0下创建一个文件,并进行更名和权限赋予
用途:(用来指定hadoop运行时产生文件的存储目录 )
[root@localhost hadoop-2.5.0]# mkdir -p data/tmp
[root@localhost hadoop-2.5.0]# chown admin:admin -R data
[root@localhost hadoop-2.5.0]# chown 777 -R data
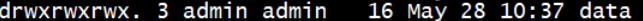
切换至hadoop目录,进行配置文件的更改
[root@localhost hadoop-2.5.0]# cd ./etc/hadoop

我们需要修改的配置文件如下
[root@localhost hadoop]# vi hadoop-env.sh

[root@localhost hadoop]# vi yarn-env.sh

(#代表注释,需要进行删除,才能生效)
[root@localhost hadoop]# vi mapred-env.sh

(#代表注释,需要进行删除,才能生效)
[root@localhost hadoop]# vi core-site.xml
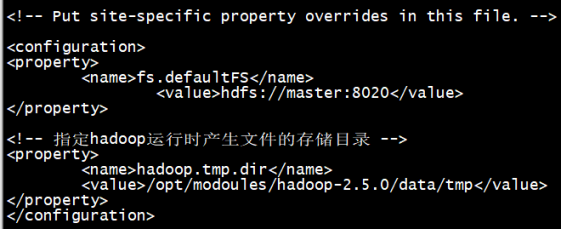
[root@localhost hadoop]# vi yarn-site.xml
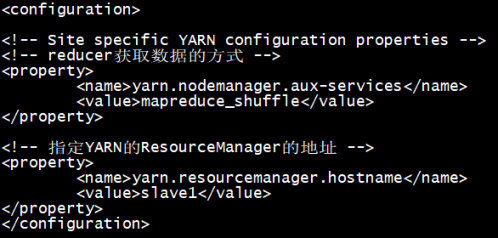
[root@localhost hadoop]# vi hdfs-site.xml
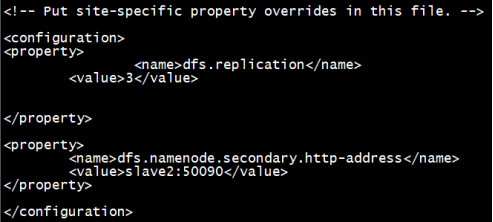
对mapred-site.xml.template文件进行更名,再进行配置
[root@localhost hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@localhost hadoop]# vi mapred-site.xml
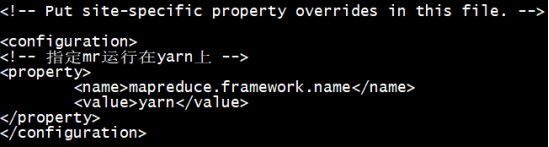
[root@localhost hadoop]# vi slaves
关闭防火墙状态
[root@localhost ~]# systemctl stop firewalld.service
[root@localhost ~]# systemctl disable firewalld.service

[root@localhost selinux]# cd /etc/selinux
[root@localhost selinux]# vi config

查看防火墙状态(查看之前先进行重启,否则不生效)
[root@localhost ~]# sestatus

克隆两台机器(虚拟机必须处于关机状态才能克隆,此外,选择完整克隆,不要链接克隆)
(并对另外两台网卡的ip,主机名做相应的更改)
(否则三台机器会出现ip冲突,或者意外报错)
master(主节点)
slave1(从节点)
slave2(从节点)
三台机器配置完成

设置免密登录
(让三台机器进行无密钥通信)最好是用普通用户
[root@master ~]# su admin
[admin@master root]$ ssh-keygen(三次回车)
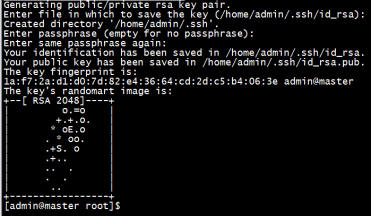
[admin@master root]$ ssh copy-id master

(以下操作会问:是否愿意给密钥给xxx,回答yes,其他机器皆如此)
同意之后它会要求进行密码的验证(如果三次输入密码错误,将会自动退出并进行从新输入)

(说明密钥已成功给出)
[admin@master root]$ ssh-copy-id slave1

(说明密钥已成功给出)

(说明密钥已成功给出)
slave1,slave2需要重复以上操作
(否则三台机器会因为没有共同的密钥,从而导致无法访问)
切换目录,开始准备启动hadoop
[admin@master root]$ cd /opt/modoules/hadoop-2.5.0
进行格式化(只能操作一次,除非是配置文件错误,才能进行二次格式化,否则会出现一大堆的报错信息)
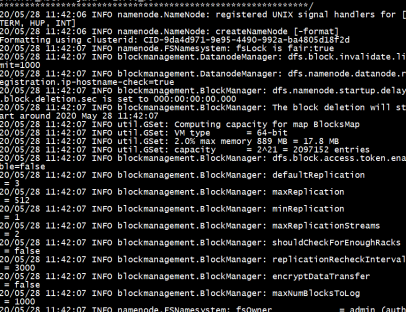
[admin@master hadoop-2.5.0]$ bin/hdfs namenode -format
格式化成功
(只能出现INFO,如果是error,expectation说明配置文件发生异常,需要返回进行检查并做相应的更改,不要忘记更改之后要进行格式化)
启动dfs
[admin@master hadoop-2.5.0]$ sbin/start-dfs.sh
(显示如下进程说明启动成功)
启动yarn
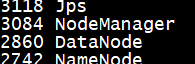
[admin@slave1 hadoop-2.5.0]$ sbin/statr-yarn.sh
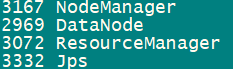
用jps查看MapReduce的进程
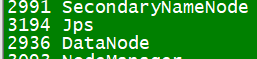
(以上就是hadoop的搭建)
查看能否访问web页面
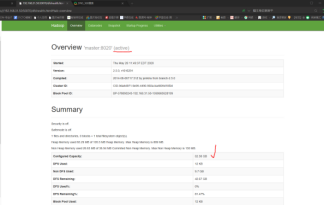
(active提示页面是可用,查看内存是否正常,如果是0说明非正常状态)
查看我们的datenode节点是否有三台虚拟机,如果只有1台或2台说明集群未能启动

如何快速搭建hadoop集群的更多相关文章
- VMware 克隆linux后找不到eth0(学习hadoop,所以想快速搭建一个集群)
发生情况: 由于在学习hadoop,所以想快速搭建一个集群出来.所以直接在windows操作系统上用VMware安装了CentOS操作系统,配置好hadoop开发环境后,采用克隆功能,直接克 ...
- 环境搭建-Hadoop集群搭建
环境搭建-Hadoop集群搭建 写在前面,前面我们快速搭建好了centos的集群环境,接下来,我们就来开始hadoop的集群的搭建工作 实验环境 Hadoop版本:CDH 5.7.0 这里,我想说一下 ...
- 使用Windows Azure的VM安装和配置CDH搭建Hadoop集群
本文主要内容是使用Windows Azure的VIRTUAL MACHINES和NETWORKS服务安装CDH (Cloudera Distribution Including Apache Hado ...
- virtualbox 虚拟3台虚拟机搭建hadoop集群
用了这么久的hadoop,只会使用streaming接口跑任务,各种调优还不熟练,自定义inputformat , outputformat, partitioner 还不会写,于是干脆从头开始,自己 ...
- 搭建Hadoop集群 (三)
通过 搭建Hadoop集群 (二), 我们已经可以顺利运行自带的wordcount程序. 下面学习如何创建自己的Java应用, 放到Hadoop集群上运行, 并且可以通过debug来调试. 有多少种D ...
- 搭建Hadoop集群 (一)
上面讲了如何搭建Hadoop的Standalone和Pseudo-Distributed Mode(搭建单节点Hadoop应用环境), 现在我们来搭建一个Fully-Distributed Mode的 ...
- 搭建Hadoop集群 (二)
前面的步骤请看 搭建Hadoop集群 (一) 安装Hadoop 解压安装 登录master, 下载解压hadoop 2.6.2压缩包到/home/hm/文件夹. (也可以从主机拖拽或者psftp压缩 ...
- Linux下搭建Hadoop集群
本文地址: 1.前言 本文描述的是如何使用3台Hadoop节点搭建一个集群.本文中,使用的是三个Ubuntu虚拟机,并没有使用三台物理机.在使用物理机搭建Hadoop集群的时候,也可以参考本文.首先这 ...
- Hadoop入门进阶步步高(五)-搭建Hadoop集群
五.搭建Hadoop集群 上面的步骤,确认了单机能够运行Hadoop的伪分布运行,真正的分布式运行无非也就是多几台slave机器而已,配置方面的有一点点差别,配置起来就很easy了. 1.准备三台se ...
随机推荐
- 一些vue项目
https://segmentfault.com/a/1190000010330905
- 【自用】Notice
读题 不要把 \(\sum a \oplus b\) 看成异或和. 注意读完整,有可能对原有符号有新的约定,不要想当然. 注意模数的 0 数清楚. 卡常&时间 打题之前一般先搞个自己的缺省源. ...
- AtCoder Regular Contest 107(VP)
Contest Link Official Editorial 比赛体验良好,网站全程没有挂.题面简洁好评,题目质量好评.对于我这个蒟蒻来说非常合适的一套题目. A. Simple Math Prob ...
- css处理文字不换行、换行截断、溢出省略号
1.使文字不换行 white-space: nowrap; 值 描述 normal 默认.空白会被浏览器忽略. pre 空白会被浏览器保留.其行为方式类似 HTML 中的 <pre> 标签 ...
- Spring 中常用的注解
(1).用于注册bean对象的注解 1.1@Component: 作用: 调用无参构造创建一个bean对象,并把对象存入spring的Ioc容器,交由spring容器进行管理.相当于在xml中配置一个 ...
- Spring Boot 日志各种使用姿势,是时候捋清楚了!
@ 目录 1. Java 日志概览 1.1 总体概览 1.2 日志级别 1.3 综合对比 1.4 最佳实践 2. Spring Boot 日志实现 2.1 Spring Boot 日志配置 2.2 L ...
- 交换机配置OSPF负载分担
组网图形 OSPF负载分担简介 等价负载分担ECMP(Equal-Cost Multiple Path),是指在两个网络节点之间同时存在多条路径时,节点间的流量在多条路径上平均分摊.负载分担的作用是减 ...
- 洛谷题解 P1051 【谁拿了最多奖学金】
其实很水 链接: P1051 [谁拿了最多奖学金] 注意: 看好信息,不要看漏或看错因为信息很密集 AC代码: 1 #include<bits/stdc++.h>//头文件 2 using ...
- Javascript JQuery select选择之Safari与Firefox
发现在苹果IOS手机及Safari浏览其中,如下代码不工作. $("#users option[value='hello']").attr("selected" ...
- 钩子与API截获
http://www.pudn.com/Download/type/id/19.html