Hive 中的四种排序详解,再也不会混淆用法了
Hive 中的四种排序
排序操作是一个比较常见的操作,尤其是在数据分析的时候,我们往往需要对数据进行排序,hive 中和排序相关的有四个关键字,今天我们就看一下,它们都是什么作用。
数据准备
下面我们有一份温度数据,tab 分割
2008 32.0
2008 21.0
2008 31.5
2008 17.0
2013 34.0
2015 32.0
2015 33.0
2015 15.9
2015 31.0
2015 19.9
2015 27.0
2016 23.0
2016 39.9
2016 32.0
建表加载数据
create table ods_temperature(
`year` int,
temper float
)
row format delimited fields terminated by '\t';
load data local inpath '/Users/liuwenqiang/workspace/hive/temperature.data' overwrite into table ods_temperature;
1. order by(全局排序)
order by会对输入做全局排序,因此只有一个Reducer(多个Reducer无法保证全局有序),然而只有一个reducer,会导致当输入规模较大时,消耗较长的计算时间
- 降序:desc
- 升序:asc 不需要指定,默认是升序
需要注意的是它受hive.mapred.mode的影响,在严格模式下,必须使用limit 对排序的数据量进行限制,因为数据量很大只有一个reducer的话,会出现OOM 或者运行时间超长的情况,所以严格模式下,不适用limit 则会报错,更多请参考Hive的严格模式和本地模式
Error: Error while compiling statement: FAILED: SemanticException 1:39 Order by-s without limit are disabled for safety reasons. If you know what you are doing, please set hive.strict.checks.orderby.no.limit to false and make sure that hive.mapred.mode is not set to 'strict' to proceed. Note that you may get errors or incorrect results if you make a mistake while using some of the unsafe features.. Error encountered near token 'year' (state=42000,code=40000)
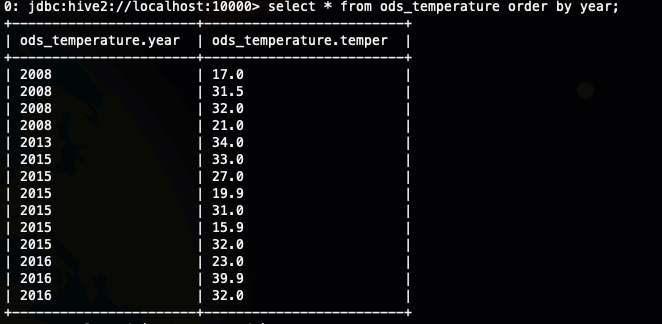
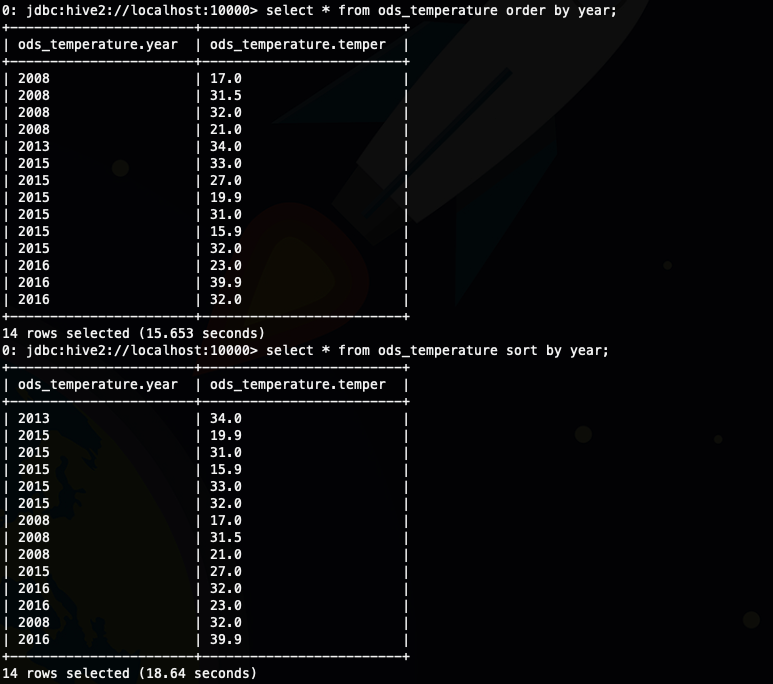
接下来我们看一下order by的排序结果select * from ods_temperature order by year;
2. sort by(分区内排序)
不是全局排序,其在数据进入reducer前完成排序,也就是说它会在数据进入reduce之前为每个reducer都产生一个排序后的文件。因此,如果用sort by进行排序,并且设置mapreduce.job.reduces>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
它不受Hive.mapred.mode属性的影响,sort by的数据只能保证在同一个reduce中的数据可以按指定字段排序。使用sort by你可以指定执行的reduce个数(通过set mapred.reduce.tasks=n来指定),对输出的数据再执行归并排序,即可得到全部结果。
set mapred.reduce.tasks=3;
select * from ods_temperature sort by year;
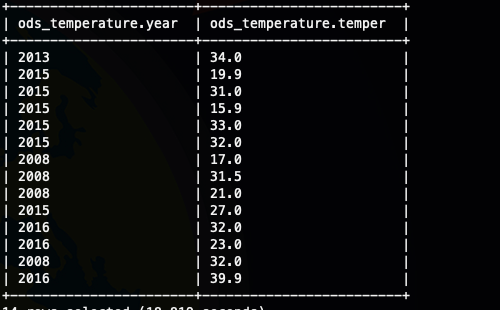
发现上面的输出好像看不出来啥,只能看到不是有序的,哈哈,那我们换一种方法,将数据输出到文件,因为我们设置了reduce数是3,那应该会有三个文件输出
set mapred.reduce.tasks=3;
insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t' select * from ods_temperature sort by year;
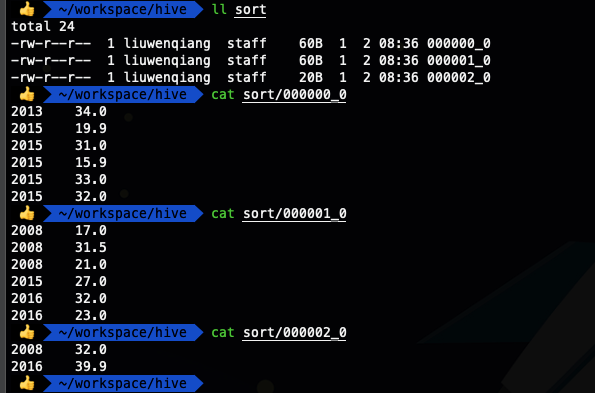
可以看出这下就清楚多了,我们看到一个分区内的年份并不同意,那个年份的数据都有
sort by 和order by 的执行效率
首先我们看一个现象,一般情况下我们认为sort by 应该是比 order by 快的,因为 order by 只能使用一个reducer,进行全部排序,但是当数据量比较小的时候就不一定了,因为reducer 的启动耗时可能远远数据处理的时间长,就像下面的例子order by 是比sort by快的
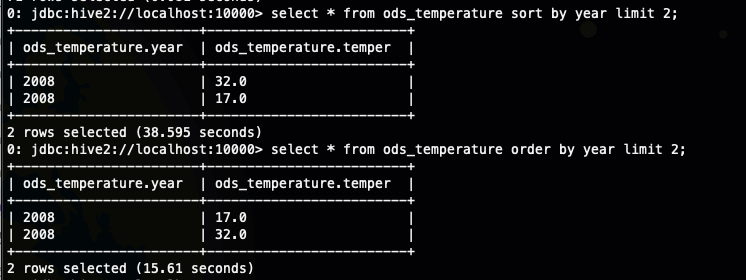
sort by 中的limt
可以在sort by 用limit子句减少数据量,使用limit n 后,传输到reduce端的数据记录数就减少到 n *(map个数),也就是说我们在sort by 中使用limit 限制的实际上是每个reducer 中的数量,然后再根据sort by的排序字段进行order by,最后返回n 条数据给客户端,也就是说你在sort by 用limit子句,最后还是会使用order by 进行最后的排序
order by 中使用limit 是对排序好的结果文件去limit 然后交给reducer,可以看到sort by 中limit 子句会减少参与排序的数据量,而order by 中的不行,只会限制返回客户端数据量的多少。
从上面的执行效率,我们看到sort by limit 几乎是 order by limit 的两倍了 ,大概才出来应该是多了某个环节
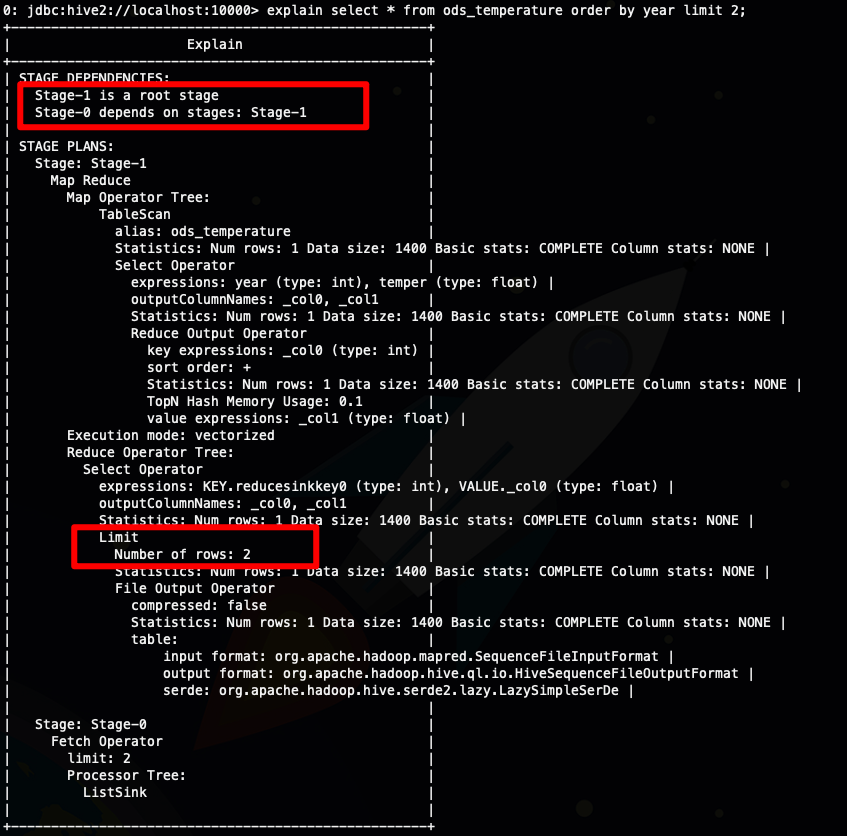
接下来我们分别看一下order by limit 和 sort by limit 的执行计划
explain select * from ods_temperature order by year limit 2;
explain select * from ods_temperature sort by year limit 2;
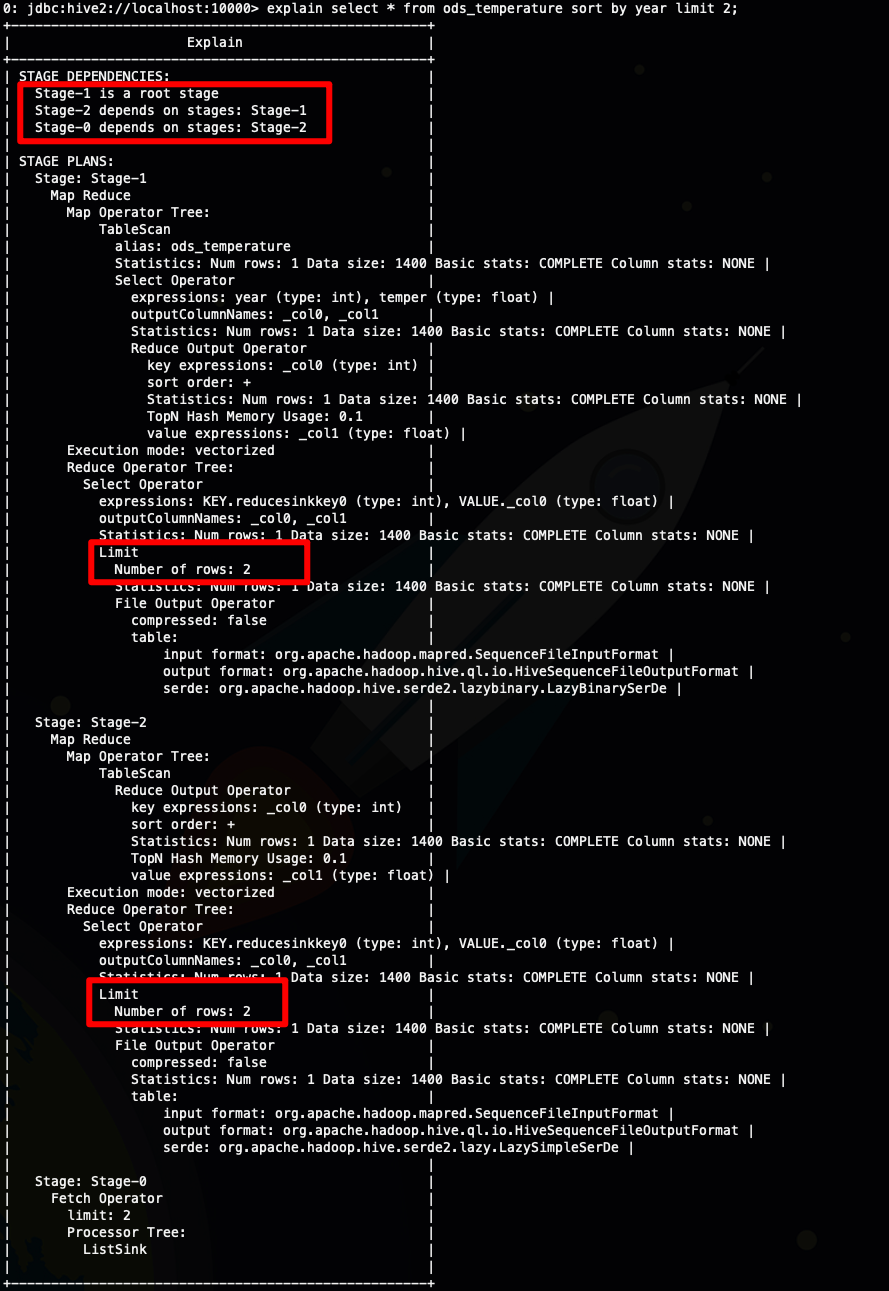
从上面截图我圈出来的地方可以看到
- sort by limit 比 order by limit 多出了一个stage(order limit)
- sort by limit 实际上执行了两次limit ,减少了参与排序的数据量
3. distribute by(数据分发)
distribute by是控制在map端如何拆分数据给reduce端的。类似于MapReduce中分区partationer对数据进行分区
hive会根据distribute by后面列,将数据分发给对应的reducer,默认是采用hash算法+取余数的方式。
sort by为每个reduce产生一个排序文件,在有些情况下,你需要控制某写特定的行应该到哪个reducer,这通常是为了进行后续的聚集操作。distribute by刚好可以做这件事。因此,distribute by经常和sort by配合使用。
例如上面的sort by 的例子中,我们发现不同年份的数据并不在一个文件中,也就说不在同一个reducer 中,接下来我们看一下如何将相同的年份输出在一起,然后按照温度升序排序
首先我们尝试一下没有distribute by 的SQL的实现
insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t' select * from ods_temperature sort by temper ;
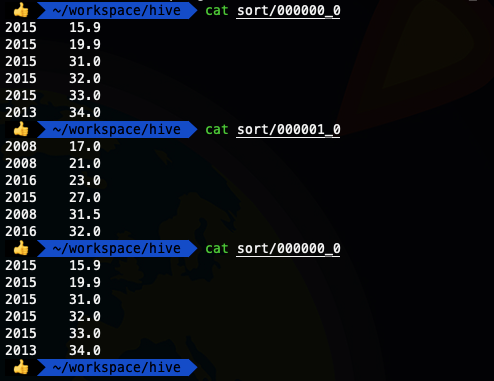
发现结果并没有把相同年份的数据分配在一起,接下来我们使用一下distribute by
insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t'
select * from ods_temperature distribute by year sort by temper ;
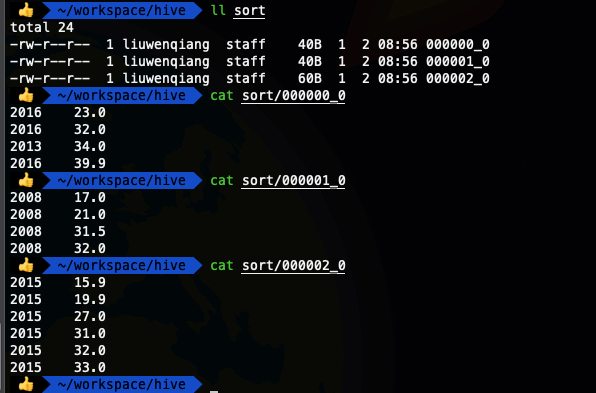
这下我们看到相同年份的都放在了一下,可以看出2013 和 2016 放在了一起,但是没有一定顺序,这个时候我们可以对 distribute by 字段再进行一下排序
insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t'
select * from ods_temperature distribute by year sort by year,temper ;
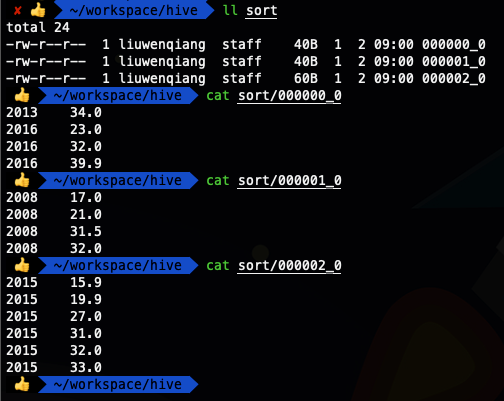
4. cluster by
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
当分区字段和排序字段相同cluster by可以简化distribute by+sort by 的SQL 写法,也就是说当distribute by和sort by 字段相同时,可以使用cluster by 代替distribute by和sort by
insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t'
select * from ods_temperature distribute by year sort by year ;
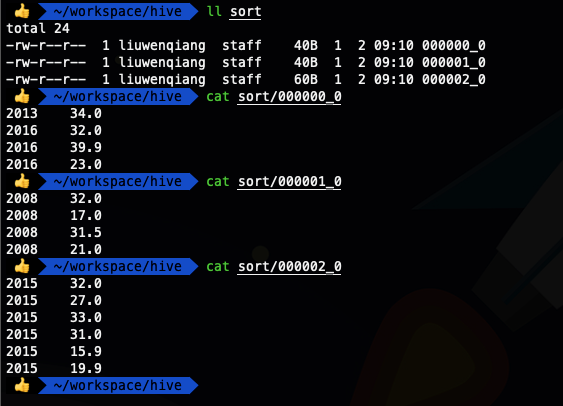
insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t'
select * from ods_temperature cluster by year;
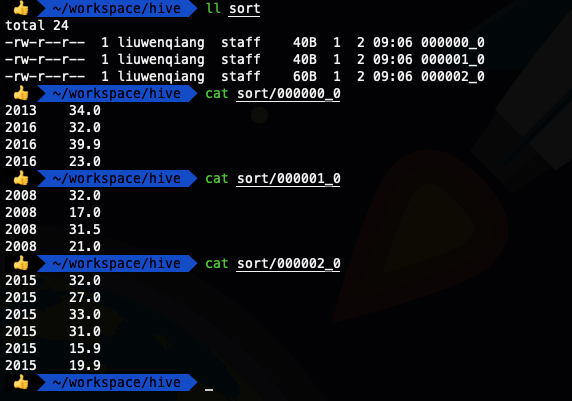
我们看到上面两种SQL写法的输出结果是一样的,这也就证明了我们的说法,当distribute by和sort by 字段相同时,可以使用cluster by 代替distribute by和sort by
当你尝试给cluster by 指定排序方向的时候,你就会得到如下错误。
Error: Error while compiling statement: FAILED: ParseException line 2:46 extraneous input 'desc' expecting EOF near '<EOF>' (state=42000,code=40000)
总结
- order by 是全局排序,可能性能会比较差;
- sort by分区内有序,往往配合distribute by来确定该分区都有那些数据;
- distribute by 确定了数据分发的规则,满足相同条件的数据被分发到一个reducer;
- cluster by 当distribute by和sort by 字段相同时,可以使用cluster by 代替distribute by和sort by,但是cluster by默认是升序,不能指定排序方向;
- sort by limit 相当于每个reduce 的数据limit 之后,进行order by 然后再limit ;
Hive 中的四种排序详解,再也不会混淆用法了的更多相关文章
- [ 转载 ] Java开发中的23种设计模式详解(转)
Java开发中的23种设计模式详解(转) 设计模式(Design Patterns) ——可复用面向对象软件的基础 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类 ...
- AES加密的四种模式详解
对称加密和分组加密中的四种模式(ECB.CBC.CFB.OFB) 一. AES对称加密: A ...
- PHP中引入文件的四种方式详解
四种语句 PHP中有四个加载文件的语句:include.require.include_once.require_once. 基本语法 require:require函数一般放在PHP脚本的最前面,P ...
- Java开发中的23种设计模式详解
[放弃了原文访问者模式的Demo,自己写了一个新使用场景的Demo,加上了自己的理解] [源码地址:https://github.com/leon66666/DesignPattern] 一.设计模式 ...
- Java开发中的23种设计模式详解(转)
设计模式(Design Patterns) ——可复用面向对象软件的基础 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类编目的.代码设计经验的总结.使用设计模式是为了 ...
- 0. Java开发中的23种设计模式详解(转)
设计模式(Design Patterns) ——可复用面向对象软件的基础 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类编目的.代码设计经验的总结.使用设计模式是为了 ...
- (转)Java开发中的23种设计模式详解
原文出自:http://blog.csdn.net/zhangerqing 一.设计模式的分类 总体来说设计模式分为三大类: 创建型模式,共五种:工厂方法模式.抽象工厂模式.单例模式.建造者模式.原型 ...
- 【java】java开发中的23种设计模式详解
设计模式(Design Patterns) ——可复用面向对象软件的基础 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类编目的.代码设计经验的总结.使用设计模式是为了 ...
- Java开发中的23种设计模式详解(转载)
前学习过一段时间的设计模式,总是感觉学习的不够清楚.现在再重新复习一下,原文地址:https://blog.csdn.net/doymm2008/article/details/13288067 一. ...
随机推荐
- 第8.33节 Python中__getattr__以及__getattr__与__ getattribute__的关系深入剖析
一. 引言 前面几节分别介绍了Python中属性操作捕获的三剑客:__ getattribute__方法.__setattr__方法.__delattr__方法,为什么__ getattribute_ ...
- APP非功能测试
1.移动APP启动时间测试 问题:如何获取启动时间? 答:通过adb的logcat来获取Activity启动时间.用户体验时间=Activity启动时间+启动中异步UI绘制的时间. 启动时间的测试主要 ...
- 小齐读者拿到快手、百度、网易等 offer 的独门秘籍!
小齐说: 这篇文章来自读者冰红茶,他刚结束了秋招,拿了很多家 offer. 和他聊完之后,我觉得他的备考思路也完全适用于美国的面试,只是分值要调整一下,但是具体每一块的内容,地球村通用.所以分享给大家 ...
- 团队作业part6--复审与事后分析
一.Alpha阶段项目复审:https://www.cnblogs.com/3Jax/p/13127401.html 二.事后诸葛亮分析:https://www.cnblogs.com/3Jax/p/ ...
- (数据科学学习手札100)搞定matplotlib中的字体设置
本文示例文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 matplotlib作为数据可视化的利器,被广泛 ...
- SpringBoot + SpringSecurity + Mybatis-Plus + JWT实现分布式系统认证和授权
1. 简介 Spring Security是一个功能强大且易于扩展的安全框架,主要用于为Java程序提供用户认证(Authentication)和用户授权(Authorization)功能. ...
- js下 Day19、综合案例
一.吸顶楼层 效果图: 功能思路分析: 1. 面向对象框架 2. 渲染导航 \1. 数据 \2. 对象结构的数据用for in遍历 \3. 渲染时将属性名设为锚点(a标签的href) 3. 渲染车系 ...
- Kudu的特点
Kudu的特点 0.原理 列式存储管理器 一个列式存储数据的地方,跟mysql差不多,只是mysql是行式存储. 他是一个集群,能分布式存储. 查询也是写sql语句. 列式存储效率高. 1.为什么会有 ...
- metinfo小于v6.2.0版本SQL盲注利用脚本
#coding=utf-8 import requests import re import sys import time #获取config_safe.php中的 key def getKey(u ...
- svn add . 报错,不能add全部,因为有一些文件已经在版本库中了
svn add 目录名 --force SVN commit -m '' 目录名