Linux 搭建ELK日志收集系统
在搭建ELK之前,首先要安装Redis和JDK,安装Redis请参考上一篇文章。
首先安装JDK及配置环境变量
1.解压安装包到/usr/local/java目录下
[root@VM_0_9_centos ~]# tar xvf /ryt/soft/jdk-11.0.3_linux-x64_bin.tar.gz -C /usr/local/java/
2.配置环境变量(在尾部追加内容如下)
[root@VM_0_9_centos ~]# vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk-11.0.3
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
3.重启配置文件,使其立即生效
[root@VM_0_9_centos ~]# source /etc/profile
ELK搭建详细过程
安装程序:filebeat,elasticsearch,logstash,kibana
1.安装Elasticsearch
1)解压安装包到路径/usr/local/elk下
[root@VM_0_9_centos ~]# tar -zxvf /ryt/soft/elk/elasticsearch-7.2.0-linux-x86_64.tar.gz -C /usr/local/elk/
2.创建用户并赋权
[root@VM_0_9_centos elk]# useradd es_user
[root@VM_0_9_centos elk]# groupadd esgroup
[root@VM_0_9_centos elk]# chown -R es_user:esgroup /usr/local/elk/elasticsearch-7.2.0/
3)修改ES配置文件:
[root@VM_0_9_centos elk]# vim /usr/local/elk/elasticsearch-7.2.0/config/elasticsearch.yml
#这里指定的是集群名称,需要修改为对应的,开启了自发现功能后,ES会按照此集群名称进行集群发现cluster.name: elk-application
node.name: node-1
#目录需要手动创建
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
#ES监听地址
network.host: 0.0.0.0 #允许外网个访问
http.port: 9200
discovery.seed_hosts: ["172.17.0.9"] #内网ip
cluster.initial_master_nodes: ["node-1"]
4)修改系统参数#添加参数
vm.max_map_count=655360注:ES启动的时候回占用特别大的资源所以需要修改下系统参数,若不修改资源启动会异常退出[root@VM_0_9_centos elk]# vim /etc/sysctl.conf
5)重新载入配置
[root@VM_0_9_centos elk]# sysctl -p /etc/sysctl.conf6)修改资源参数[root@VM_0_9_centos elk]# vim /etc/security/limits.conf
修改内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 65536
* hard nproc 131072
7)设置用户资源参数
[root@VM_0_9_centos elk]# vim /etc/security/limits.d/20-nproc.conf
#添加
es_user soft nproc 65536
8)创建数据和日志目录并修改目录权限
[root@VM_0_9_centos elk]# mkdir -pv /usr/local/elk/{data,logs}
[root@VM_0_9_centos elk]# chown -R es_user:esgroup/data/elasticsearch/[root@VM_0_9_centos elk]# chown -R es_user:esgroup /usr/local/elk/elasticsearch-7.2.0
9)切换用户并后台启动ES
[root@VM_0_9_centos elk]# su esuser
[es_user@VM_0_9_centos elk]$ /usr/local/elk/elasticsearch-7.2.0/bin/elasticsearch &
2.安装logstash
1.解压安装包并移到/usr/local/elk目录下
[root@VM_0_9_centos filebeat-7.2.0]# tar -zvxf /ryt/soft/elk/logstash-7.2.0.tar.gz -C /usr/local/elk/
2.创建软连接
[root@VM_0_9_centos elk]# ln -s /usr/local/elk/logstash-7.2.0 /usr/local/elk/logstash
注:Java HotSpot(TM) 64-Bit Server VM warning:
INFO: os::commit_memory(0x00000000c5330000, 986513408, 0) failed;
error='Not enough space' (errno=12)
[root@VM_0_9_centos elk]# vim ./elasticsearch-7.2.0/config/jvm.options
3.在/usr/local/elk/logstash/config/下新建文件logstash.config
内容如下:
input {
redis {
data_type => "list" #存储类型
type => "redis-input"
key => "logstash:redis" #key值,后面要与spring boot中key保持一致
host => "localhost"
port => 6379
# threads => 5 #启动线程数量
codec => "json"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "springboot-elk" #index是定义将过滤后的日志推送到Elasticsearch后存储的名字
}
stdout { codec => rubydebug} #是否在控制台打印
}
4.载入配置
[root@VM_0_9_centos config]# ../bin/logstash -f logstash-elasticsearch.conf -t
3.安装filebeat
1)解压安装包到路径/usr/local/elk下
[root@VM_0_9_centos elk]# tar xvf filebeat-7.2.0-linux-x86_64.tar.gz -C /usr/local/elk/
2)修改配置文件,使filebeat获取的日志进入redis:
注:此处演示获取spring cloud框架中eureka日志,其他程序日志都可相同方法获取
[root@VM_0_9_centos filebeat-7.2.0]#
[root@VM_0_9_centos filebeat-7.2.0]# pwd
/usr/local/elk/filebeat-7.2.0
[root@VM_0_9_centos filebeat-7.2.0]# vim ./filebeat.yml
#修改的内容有一家几个字段
enabled:true
paths:程序日志路径
#output只能有一个
#output.logstash:
# hosts:["服务器IP:5044"]
output.redis:
hosts:127.0.0.1 #redis所在服务器IP
port:6379 #redis端口3)设置开机启动
修改配置rc.local,后面追加 /usr/local/elk/filebeat-7.2.0/filebeat > /tmp/filebeat.log 2>&1
[root@VM_0_9_centos filebeat-7.2.0]# vim /etc/rc.local
4)后台启动filebeat
[root@VM_0_9_centos filebeat-7.2.0]# /usr/local/elk/filebeat-7.2.0/filebeat & 5)查看启动,filebeat有没有监听端口,主要看日志和进程
[root@VM_0_9_centos filebeat-7.2.0]# ps -ef | grep filebeat
[root@VM_0_9_centos filebeat-7.2.0]# tailf logs/filebeat

4.启动logstash
测试一下logstash不指定配置文件启动
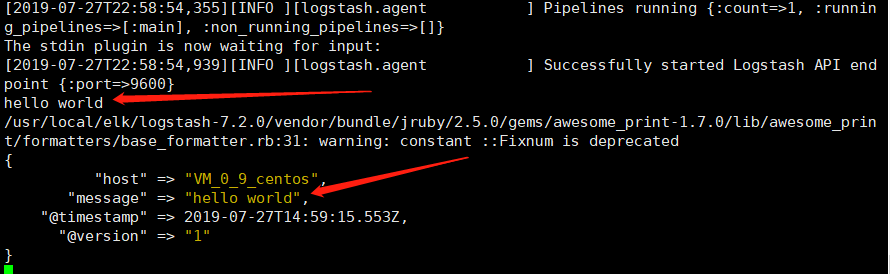
[root@VM_0_9_centos config]# /usr/local/elk/logstash/bin/logstash -e 'input { stdin { } } output { stdout {} }'
注:手动输入 hello world,它也会输出 hello world
5.安装kibana
1)解压安装包到路径/usr/local/elk下
[root@VM_0_9_centos ~]# tar -zxvf /ryt/soft/elk/kibana-7.2.0-linux-x86_64.tar.gz -C /usr/local/elk/
2)编辑kibana配置文件
[root@VM_0_9_centos ~]# vim /usr/local/elk/kibana-7.2.0/config/kibana.yml
3)后台启动kibana
[root@VM_0_9_centos ~]# /usr/local/elk/kibana-7.2.0/bin/kibana --allow-root &
6.ELK logstash启动慢解决方案
使用如下命令查询
[root@VM_0_9_centos ~]# cat /proc/sys/kernel/random/entropy_avail 如果返回值小于1000, 那么就需要安装haveged包。
[root@VM_0_9_centos ~]# yum -y install haveged
我在安装了以后, logstash启动慢的问题解决,在10秒内启动。
参考链接:https://wiki.archlinux.org/index.php/Haveged_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87)
Linux 搭建ELK日志收集系统的更多相关文章
- 快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana)
快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana) 概要说明 需求场景,系统环境是CentOS,多个应用部署在多台服务器上,平时查看应用日志及排查问题十 ...
- 用ElasticSearch,LogStash,Kibana搭建实时日志收集系统
用ElasticSearch,LogStash,Kibana搭建实时日志收集系统 介绍 这套系统,logstash负责收集处理日志文件内容存储到elasticsearch搜索引擎数据库中.kibana ...
- ELK 日志收集系统
传统系统日志收集的问题 在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常底下. 通常,日志被分 ...
- 快速搭建ELK日志分析系统
一.ELK搭建篇 官网地址:https://www.elastic.co/cn/ 官网权威指南:https://www.elastic.co/guide/cn/elasticsearch/guide/ ...
- Kubernetes 系列(八):搭建EFK日志收集系统
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch.Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案. Elasticsearch 是一个 ...
- Docker搭建EFK日志收集系统,并自定义es索引名
EFK架构图 一.EFK简介 EFK不是一个软件,而是一套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志系统. EFK是三个开源软件的缩写,分 ...
- ELK日志收集系统搭建
架构图 ELK 架构图:其中es 是集群,logstash 是单节点(猜想除非使用nginx对log4j的网络输出分发),kibana是单机(用不着做成集群). 1.拓扑图 2.logstash ...
- Windows系统搭建ELK日志收集服务器
一.ELK是什么?ELK是由Elasticsearch.Logstash.Kibana这3个软件的首字母缩写. Elasticsearch是一个分布式搜索分析引擎,稳定.可水平扩展.易于管理是它的主要 ...
- 十九,基于helm搭建EFK日志收集系统
目录 EFK日志系统 一,EFK日志系统简介: 二,EFK系统部署 1,EFK系统部署方式 2,基于Helm方式部署EFK EFK日志系统 一,EFK日志系统简介: 关于系统日志收集处理方案,其实有很 ...
随机推荐
- 【GIT】命令笔记
1.将本地代码提交到github等仓库 1.创建仓库省略 2.切换到本地需要上传的地址 :初始化仓库 git init 3.配置git,告诉git你是谁 git config --global use ...
- SpringBoot的条件注解源码解析
SpringBoot的条件注解源码解析 @ConditionalOnBean.@ConditionalOnMissingBean 启动项目 会在ConfigurationClassBeanDefini ...
- 【python】Matplotlib作图中有多个Y轴
在作图过程中,需要绘制多个变量,但是每个变量的数量级不同,在一个坐标轴下作图导致曲线变化很难观察,这时就用到多个坐标轴.本文除了涉及多个坐标轴还包括Axisartist相关作图指令.做图中label为 ...
- 第一次UML作业
这个作业属于哪个课程 https://edu.cnblogs.com/campus/fzzcxy/2018SE2/ 这个作业要求在哪里 https://edu.cnblogs.com/campus/f ...
- Fiddler 4 (过滤器的使用)
1.先找到过滤器并且勾选 2.勾选 并填写要过滤的地址 3.运行 最终效果如下
- opencv-python imread、imshow浏览目录下的图片文件
☞ ░ 前往老猿Python博文目录 ░ 一.几个知识点 1.1.使用Python查找目录下的文件 具体请参考<Python正则表达式re模块和os模块实现文件搜索模式匹配>. 1.2.o ...
- 第8.17节 Python __repr__方法和__str__方法、内置函数repr和str的异同点对比剖析
一. 引言 记得刚开始学习Python学习字符串相关内容的时候,查了很多资料,也做了些测试,对repr和str这两个函数的返回值老猿一直没有真正理解,因为测试发现这两个函数基本上输出时一样的.到现在老 ...
- Python的富比较方法__eq__和__ne__之间的关联关系分析
Python的富比较方法包括__lt__.__gt__.__le__.__ge__.__eq__和__ne__六个方法,分别表示:小于.大于.小于等于.大于等于.等于和不等于,对应的操作运算符为:&l ...
- 第11.10节 Python正则表达式的非贪婪模式的重复匹配:'*?', '+?',和 '??'
在<第11.9节 Pytho正则表达式的贪婪模式和非贪婪模式>老猿简单介绍了贪婪模式和非贪婪模式,并说明'', '+',和 '?' 修饰符都是 贪婪的:它们在字符串进行尽可能多的匹配.有时 ...
- ATT&CK 实战 - 红日安全 vulnstack (二) 环境部署(劝退水文)
靶机下载地址:http://vulnstack.qiyuanxuetang.net/vuln/detail/3/ 靶场简述 红队实战系列,主要以真实企业环境为实例搭建一系列靶场,通过练习.视频教程.博 ...