DAOS 分布式异步对象存储|存储模型
概述
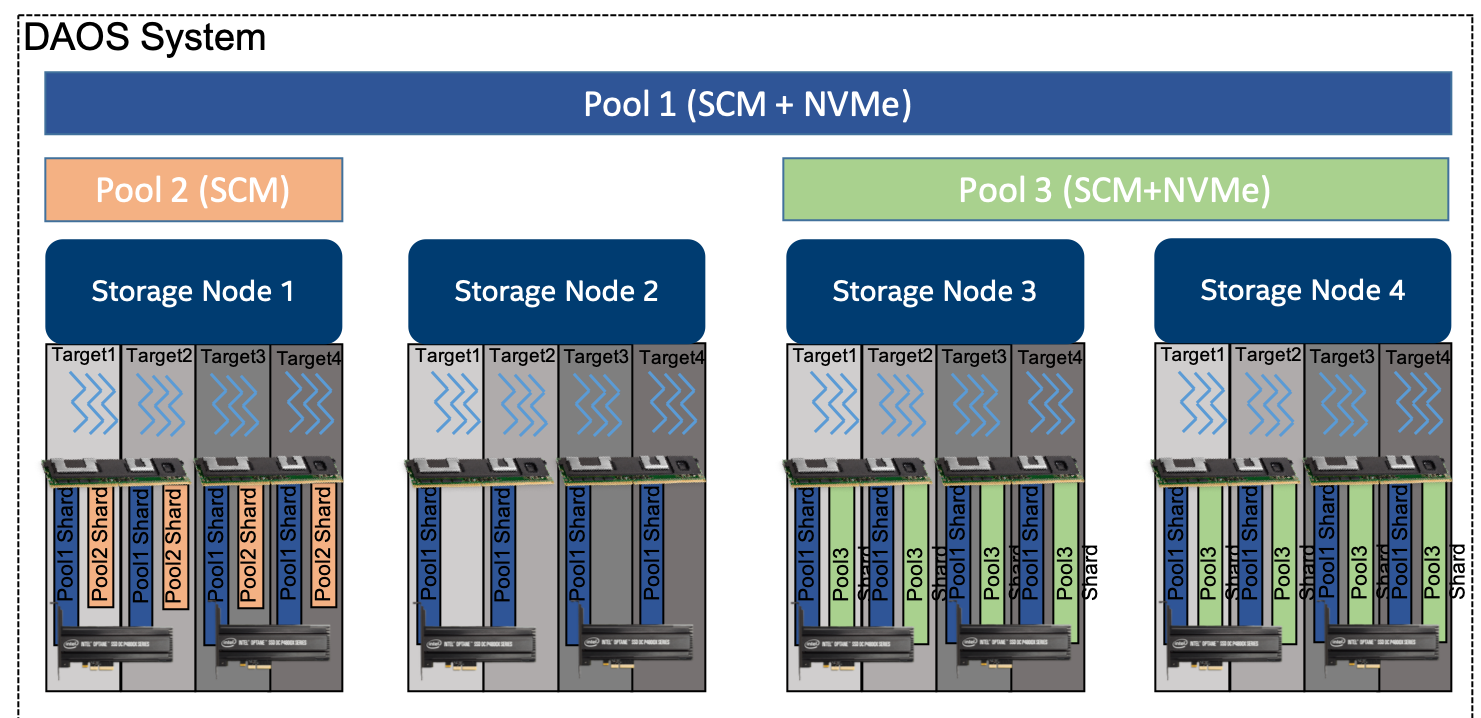
DAOS Pool 是分布在 Target 集合上的存储资源预留。分配给每个 Target 上的 Pool 的实际空间称为 Pool Shard。
分配给 Pool 的总空间在创建时确定,后期可以通过调整所有 Pool Shard 的大小(在每个 Target 专用的存储容量限制内)或跨越更多 Target(添加更多 Pool Shard)来随时间扩展。
Pool 提供了存储虚拟化,是资源调配和隔离的单元。DAOS Pool 不能跨多个系统。
一个 Pool 可以承载多个称为 DAOS Container 的事务对象存储。每个 Container 都是一个私有的对象地址空间,可以对其进行事务性修改,并且独立于存储在同一 Pool 中的其他 Container。Container 是快照和数据管理的单元。属于 Container 的 DAOS 对象可以分布在当前 Pool 的任何一个 Target 上以提高性能和恢复能力,并且可以通过不同的 API 访问,从而高效地表示结构化、半结构化和非结构化数据。
下表显示了每个 DAOS 概念的目标可伸缩性级别:
| DAOS 概念 | 可伸缩性(数量级) |
|---|---|
| System | \(10^5\) Servers and \(10^2\) Pools |
| Server | \(10^1\) Targets |
| Pool | \(10^2\) Containers |
| Container | \(10^9\) Objects |
DAOS Pool
Pool 由唯一的 Pool UUID 标识,并在称为 Pool 映射的持久版本控制列表中维护 Target 成员身份。成员资格是确定的和一致的,成员资格的变更是按顺序编号的。Pool 映射不仅记录活跃 Target 的列表,还以树的形式包含存储拓扑,用于标识共享公共硬件组件的 Target。例如,树的第一级可以表示共享同一主板的 Target,第二级可以表示共享同一机架的所有主板,最后第三级可以表示同一机房中的所有机架。
该框架有效地表示了层次化的容错域,然后使用这些容错域来避免将冗余数据放置在发生相关故障的 Target 上。在任何时候,都可以将新 Target 添加到 Pool 映射中,并且可以排除失败的 Target。此外,Pool 映射是完全版本化的,这有效地为映射的每次修改分配了唯一的序列,特别是对于失败节点的删除。
Pool Shard 是永久内存的预留,可以选择与特定 Target 上 NVMe 预先分配的空间相结合。它有一个固定的容量,满了就不能运行。可以随时查询当前空间使用情况,并报告 Pool Shard 中存储的任何数据类型所使用的总字节数。
一旦 Target 失败并从 Pool 映射中排除,Pool 中的数据冗余将自动在线恢复。这种自愈过程称为重建。重建进度定期记录在永久内存中存储的 Pool 中的特殊日志中,以解决级联故障。添加新 Target 时,数据会自动迁移到新添加的 Target,以便在所有成员之间平均分配占用的空间。这个过程称为空间再平衡,使用专用的持久性日志来支持中断和重启。
Pool 是分布在不同存储节点上的一组 Target,在这些节点上分布数据和元数据以实现水平可伸缩性,并使用复制或纠删码 (erasure code) 确保持久性和可用性。
创建 Pool 时,必须定义一组系统属性以配置 Pool 支持的不同功能。此外,用户还可以定义将持久存储的属性。
Pool 只能由经过身份验证和授权的应用程序访问。DAOS 支持多种安全框架,例如 NFSv4 访问控制列表或基于第三方的身份验证 (Kerberos)。连接到 Pool 时强制执行安全性检查。成功连接到 Pool 后,将向应用程序进程返回连接上下文。
如前文所述,Pool 存储许多不同种类的持久性元数据,如 Pool 映射、身份验证和授权信息、用户属性、特性和重建日志。这些元数据非常关键,需要最高级别的恢复能力。因此,Pool 的元数据被复制到几个来自不同高级容错域的节点上。对于具有数十万个存储节点的非常大的配置来说,这些节点中只有很小的一部分(大约几十个)运行 Pool 元数据服务。在存储节点数量有限的情况下,DAOS 可以依赖一致性算法来达成一致,在出现故障时保证一致性,避免脑裂。
要访问 Pool,用户进程应该连接到 Pool 并通过安全检查。一旦授权,Pool 就可以与任何或所有对等应用程序进程(类似 openg() POSIX 扩展)共享(通过 local2global() 和 global2local() 操作)连接。这种集体连接机制有助于在数据中心上运行大规模分布式作业时避免元数据请求风暴。当发出连接请求的原始进程与 Pool 断开连接时,Pool 连接将被注销。
DAOS Container
Container 代表 Pool 中的对象地址空间,由 Container UUID 标识。
下图显示了用户(I/O 中间件、特定领域的数据格式、大数据或 AI 框架等)如何使用 Container 来存储相关数据集:
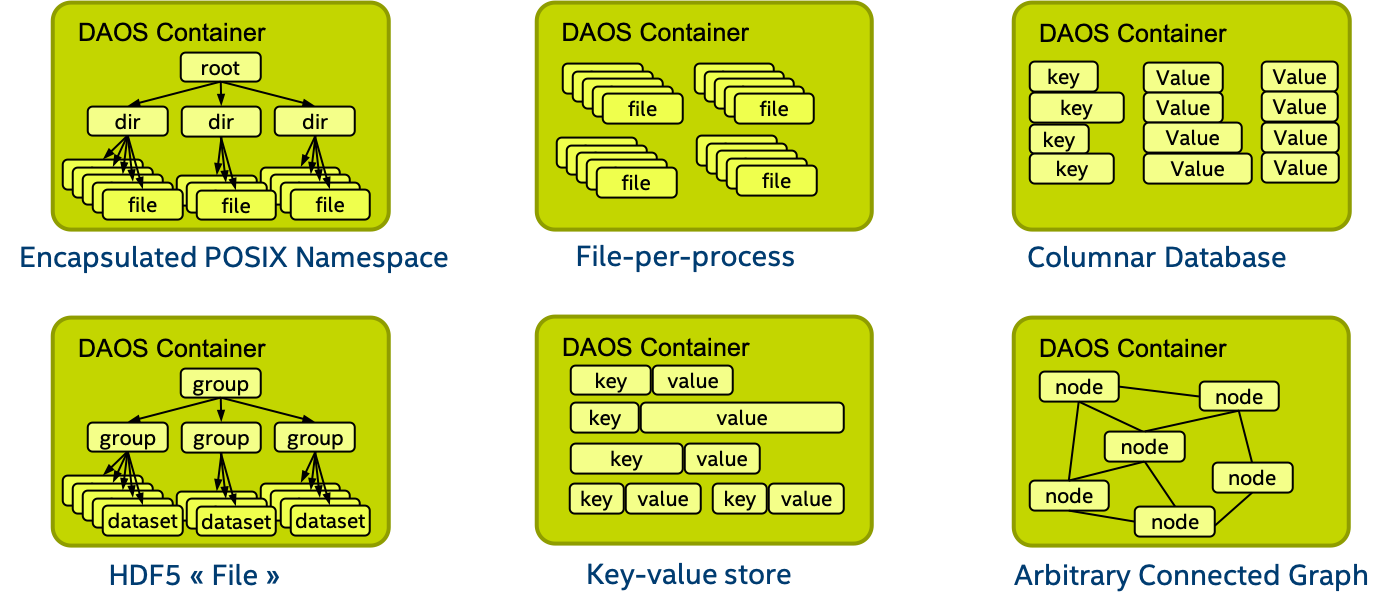
与 Pool 一样,Container 可以存储用户属性。Container 在创建时必须传递一组属性,以配置不同的功能,例如校验和。
要访问 Container,应用程序必须首先连接到 Pool,然后打开 Container。如果应用程序被授权访问 Container,则返回 Container 句柄,它的功能包括授权应用程序中的任何进程访问 Container 及其内容。打开进程可以与所有对等进程共享此句柄。它们的功能在 Container 关闭时被撤销。
Container 中的对象可能具有不同的模式,用于处理数据分布和 Target 上的冗余,定义对象模式所需的一些参数包括动态或静态条带化、复制或纠删码。Object 类定义了一组对象的公共模式属性,每个 Object 类都被分配一个唯一的标识符,并在 Pool 级别与给定的模式相关联。一个新的 Object 类可以在任何时候用一个可配置的模式来定义,这个模式在创建之后是不可变的(或者至少在属于这个类的所有对象都被销毁之前)。
为了方便起见,在创建 Pool 时,默认情况下会预定义几个最常用的 Object 类:
| Object Class (RW = read/write, RM = read-mostly | Redundancy | Layout (SC = stripe count, RC = replica count, PC = parity count, TGT = target |
|---|---|---|
| Small size & RW | Replication | static SCxRC, e.g. 1x4 |
| Small size & RM | Erasure code | static SC+PC, e.g. 4+2 |
| Large size & RW | Replication | static SCxRC over max #targets) |
| Large size & RM | Erasure code | static SCx(SC+PC) w/ max #TGT) |
| Unknown size & RW | Replication | SCxRC, e.g. 1x4 initially and grows |
| Unknown size & RM | Erasure code | SC+PC, e.g. 4+2 initially and grows |
如下所示,Container 中的每个对象都由一个唯一的 128 位对象地址标识。对象地址的高 32 位保留给 DAOS 来编码内部元数据,比如 Object 类。剩下的 96 位由用户管理,在 Container 中应该是唯一的。只要保证唯一性,栈的上层就可以使用这些位来编码它们的元数据。DAOS API 为每个 Container 提供了 64 位可伸缩对象 ID 分配器。应用程序要存储的对象 ID 是完整的 128 位地址,该地址仅供一次性使用,并且只能与单个对象模式相关联。
<---------------------------------- 128 bits ---------------------------------->
--------------------------------------------------------------------------------
|DAOS Internal Bits| Unique User Bits |
--------------------------------------------------------------------------------
<---- 32 bits ----><------------------------- 96 bits ------------------------->
Container 是事务和版本控制的基本单元。所有的对象操作都被 DAOS 库隐式地标记为一个称为 epoch 的时间戳。DAOS 事务 API 允许组合多个对象更新到单个原子事务中,并基于 epoch 顺序进行多版本并发控制。所有版本更新都可以定期聚合,以回收重叠写入所占用的空间,并降低元数据复杂性。快照是一个永久引用,可以放置在特定的 epoch 上以防止聚合。
Container 元数据(快照列表、打开的句柄、对象类、用户属性、属性和其他)存储在持久性内存中,并由专用 Container 元数据服务维护,该服务使用与父元数据 Pool 服务相同的复制引擎或自己的引擎,这在创建 Container 时是可配置的。
与 Pool 一样,对 Container 的访问由 Container 句柄控制。要获取有效的句柄,应用程序进程必须打开 Container 并通过安全检查。然后,可以通过 Container 的 local2global() 和 global2local() 操作与其他对等应用程序进程共享此句柄。
DAOS Object
为了避免传统存储系统常见的扩展问题和开销,DAOS 有意将对象简化,不提供类型和架构之外的默认对象元数据。这意味着系统不维护时间、大小、所有者、权限,甚至不跟踪开启者。
为了实现高可用性和水平伸缩性,DAOS 提供了许多对象模式(复制/纠删码、静态/动态条带化等)。模式框架是灵活的,并且易于扩展,以允许将来使用新的自定义模式类型。模式布局是在对象标识符和 Pool 映射打开的对象上通过算法生成的。通过在网络传输和存储期间使用校验和保护对象数据,确保了端到端的完整性。
可以通过不同的 API 访问 DAOS 对象:
- Multi-level key-array API 是具有局部性特征的本机对象接口。密钥分为分发密钥 (dkey) 和属性密钥 (akey)。dkey 和 akey 都可以是可变长度的类型(字符串、整数或其它复杂的数据结构)。同一 dkey 下的所有条目都保证在同一 Target 上并置。与 akey 关联的值可以是不能部分修改的单个可变长度值,也可以是固定长度值的数组。akeys 和 dkey 都支持枚举。
- Key-value API 提供了一个简单的键和可变长度值接口。它支持传统的 put、get、remove 和 list 操作。
- Array API 实现了一个由固定大小的元素组成的一维数组,该数组的寻址方式是 64 位偏移寻址。DAOS 数组支持任意范围的读、写和 punch 操作。
相关信息
GitHub: https://github.com/storagezhang
Emai: debugzhang@163.com
华为云社区: https://bbs.huaweicloud.com/blogs/253715
DAOS 分布式异步对象存储|存储模型的更多相关文章
- 从两个模型带你了解DAOS 分布式异步对象存储
摘要:分布式异步对象存储 (DAOS) 是一个开源的对象存储系统,专为大规模分布式非易失性内存 (NVM, Non-Volatile Memory) 设计,利用了 SCM(Storage-Class ...
- DAOS 分布式异步对象存储|架构设计
分布式异步对象存储 (DAOS) 是一个开源的对象存储系统,专为大规模分布式非易失性内存 (NVM, Non-Volatile Memory) 设计,利用了SCM(Storage-Class Memo ...
- DAOS 分布式异步对象存储|故障模型
DAOS 依靠大规模分布式单端口存储.因此,每个 Target 实际上都是一个单独的失败点. DAOS 通过在不同的容错域中提供 Target 间的冗余来实现数据和元数据的可用性和持久性.DAOS 内 ...
- DAOS 分布式异步对象存储|事务模型
DAOS API 支持分布式事务,允许将针对属于同一 Container 的对象的任何更新操作组合到单个 ACID 事务中.分布式一致性是通过基于多版本时间戳排序的无锁乐观并发控制机制提供的.DAOS ...
- DAOS 分布式异步对象存储|相关组件
DAOS 的安装涉及多个组件,这些组件可以是集中式的,也可以是分布式的. DAOS 软件定义存储 (software-defined storage, SDS) 框架依赖于两种不同的通信通道: 用于带 ...
- DAOS 分布式异步对象存储|数据平面
DAOS 通过两个紧密集成的平面进行运转.数据平面处理繁重的运输操作,而控制平面负责进程编排和存储管理,简化数据平面的操作. 模块接口 I/O 引擎支持一个模块接口,该接口允许按需加载服务器端代码.每 ...
- DAOS 分布式异步对象存储|安全模型
DAOS 使用了一个灵活的安全模型,将身份验证和授权分离开来.它的设计令其对 I/O 的影响被降到最小. DAOS 对用于 I/O 传输的网络结构没有提供任何传输安全性保障.在部署 DAOS 时,管理 ...
- (转-经典-数据段)C++回顾之static用法总结、对象的存储,作用域与生存期
转自:https://blog.csdn.net/ab198604/article/details/19158697相关知识补充:https://www.cnblogs.com/rednodel/p/ ...
- Atitit. 类与对象的存储实现
Atitit. 类与对象的存储实现 1. 类的结构和实现1 2. 类的方法属性都是hashtable存储的.2 3. Class的分类 常规类(T_CLASS), 抽象类(T_ABSTRACT T_C ...
随机推荐
- CSS BFC in depth
CSS BFC in depth BFC (Block Formatting Context) https://developer.mozilla.org/en-US/docs/Web/Guide/C ...
- free online markdown editor
free online markdown editor markdown https://blog.csdn.net/xgqfrms/article/details/50129317 In-brows ...
- git stash & git stash pop
git stash & git stash pop $ git checkout feature/select-seat-system $ git checkout feature/app-d ...
- 关于TCP的Total Length
TCP/IP传输层 文档 随便找了个发送的TCP: 70 89 cc ee 84 2c 3c 2c 30 a6 a2 d0 08 00 45 00 00 4c c7 a8 40 00 80 06 00 ...
- NGK生态所即将启程!助力NGK公链建立全方位区块链生态系统!
据NGK官方消息,NGK生态所将暂定于2月15日正式上线.据了解,这是全球首个基于公链打造的生态所,也是NGK生态重要的应用之一. 此前,NGK灵石团队CTO通过多方媒体透露,NGK生态所采用去中心化 ...
- java初学者必看之构造方法详细解读
java初学者必看之构造方法详细解读 构造方法是专门用来创建对象的方法,当我们通过关键字new来创建对象时,其实就是在调用构造方法. 格式 public 类名称(参数类型 参数名称){ 方法体 } 注 ...
- 移动端时间回显iphone出现的问题
new Date(item.startTime.replace(/-/g, '/') dateFormat('hh:mm', new Date(item.startTime.replace(/-/g, ...
- 创建时间和更新时间两个选一个的情况和select case when ... then ... else ... end from 表 的使用
1.查询时间,如果更新时间update_time为空就查创建时间create_time,否则查更新时间update_time select update_time,create_time, case ...
- eclipse从接口快速跳转到实现类
1.只跳转到实现类上 按住Ctrl键,把鼠标的光标放在要跳转的接口上面,选择第二个 2.直接跳转大实现的方法上 按住Ctrl键,把鼠标的光标放在要跳转的方法上面,选择第二个 对比可以发现,操作都是一样 ...
- matlab load函数用法 实例
一 语法: load(filename) load(filename,variables) load(filename,'-ascii') load(filename,'-mat') load(fil ...