《Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering》论文整理
融合异构知识进行常识问答
论文标题 —— 《Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering》
论文来源
论文代码
任务介绍
任务概述
以CSQA(常识问答)为例,针对未提及背景知识的问题,要求考虑背景知识并作出回答
任务形式
输入:问题Q=q_1 q_2⋯q_m和包含n个答案的候选答案集合A={a_1,a_2,⋯,a_n}
目标:从候选集合中选出正确答案
评价指标:准确率
面临的问题
在与问题相关的背景知识中如何获取evidence信息(抽取三元组,为知识源构建图)
如何基于获取到的evidence信息做出预测(图表示学习+图推理来解决)
解决方案
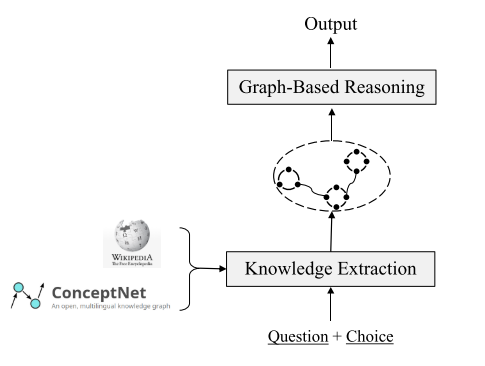
从外部知识库抽取evidence
方法
人工标注——耗时耗力耗财
仅从同构(结构化/非结构化)知识源中抽取evidence——没有同时利用不同来源的知识,得到的evidence可能不够全面
融合结构化与非结构化知识库中的知识,例如融合结构化的ConceptNet库和纯文本的Wikipedia库,并从中抽取evidence
具体实施
从ConceptNet中抽取
在ConceptNet中确定不同的问题和选项中出现的实体;
从ConceptNet中抽取从问题中的实体到候选中的实体的路径(小于 3 hops)
从Wikipedia中抽取
使用 Spacy 从中抽取出 107M 个句子,并用 Elastic Search 工具构建句子索引;
对于每个训练样例,去除问句和候选中的停用词,然后将所有词串联,作为检索查询 ;
使用 Elastic 搜索引擎 在检索查询和所有句子之间进行排序,选择出 top-K 个句子作为 Wikipedia 提供的证据信息(在实验中 K=10);
为每个知识源构建图
方法
对于ConceptNet库,用其自身的三元组即可
对于Wikipedia库,通过语义角色标注SRL(semantic role labeling)来抽取句子中的三元组
具体实施
构建ConceptNet图
把从ConceptNet中抽取出的路径拆分成三元组的形式,将每个三元组看做一个节点,融合到图中;对于含有相同实体的三元组,给图中对应到的节点加上一条边;
为了获取ConceptNet中节点的上下文词表示,将三元组根据关系模板转化为自然语言语句;
构建Wikipedia图
使用SRL抽出句子中的每个谓词的论元,谓词和论元作为节点,它们之间的关系作为边
同样地,为了增强构建图的连通性,基于两条给定的规则进行节点a,b之间的加边:
- b 中包含 a 且 a 的词数大于3
- a 与 b 仅有一个不同的词,并且 a 和 b 包含的词数都大于3
编码图信息、聚集evidence信息
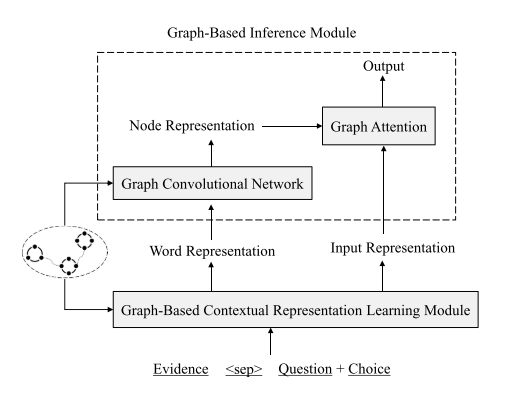
具体实施
利用Topology Sort算法,根据知识抽取部分得到的图结构,对evidence句的顺序进行重排;
利用得到的图的结构,通过重定义evidence词之间的相对位置,来让语义相关的词的相对位置更加接近;
利用evidence内部的关系结构获取更好的上下文表示;排好顺序的从ConceptNet库、Wikipedia库中抽出的evidence句、问题、所有选项
以上4个部分的串接,在使用了[sep]进行分隔后,作为XLNet的输入进行编码
进行最终的预测
具体实施
把两个evidence图看作一个无向图,利用GCN对知识图和XLNet编码提供的问答+evidence的词级向量表示,来进行编码来获得节点层次的表示
evidence传播:
- 从邻居节点聚集信息;
- 组合、更新节点表示
利用图注意力网络对经过GCN得到的节点表示以及XLNet的input表示进行处理,聚集图级别的表示,进而进行最终的预测打分
重点模块及方法阐述
SRL
语义角色标注(Semantic Role Labeling,SRL)以句子的谓词为中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构。并用语义角色来描述这些结构关系,是许多自然语言理解任务(如信息抽取,篇章分析,深度问答等)的一个重要中间步骤。在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元和它们的语义角色。
ConceptNet
ConceptNet:常识知识库,它以三元组形式的关系型知识构成。
ElaticSearch
ElasticSearch:一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,是当前流行的企业级搜索引擎。
Topology Sort

处理ConceptNet
将三元组转化为自然语句,例如,(mammals, HasA, hair) -> mammals has hair
处理Wikipedia
以evidence句作为句子图中的节点来构建句子图,如果在构建wikipedia图的过程中,节点p和q分别在句子s和t中,则为句子图中的代表两个相应句子的节点添加一条边。
利用拓扑排序算法对这些构建的句子图中的节点进行排序。
XLNET
使用XLNet而不采用BERT的原因,总结起来有以下几点:
BERT训练数据和测试数据之间的不一致性,这也叫作Discrephancy。当我们训练BERT的时候,
会随机的Mask掉一些单词的,但实际上在使用的过程当中,我们却没有MASK这类的标签,
所以这个问题就导致训练的过程和使用(测试)的过程其实不太一样,这是一个主要的问题。BERT并不能用来生成数据。由于BERT本身是依赖于DAE的结构来训练的,所以不像那些基于语言模型训练出来的模型具备很好地生成能力。
之前的方法比如NNLM,ELMo是基于语言模型生成的,所以用训练好的模型可以生成出一些句子、文本等。
但基于这类生成模型的方法论本身也存在一些问题,因为理解一个单词在上下文里的意思的时候,语言模型只考虑了它的上文,而没有考虑下文!
基于这些BERT的缺点,学者们提出了XLNet, 而且也借鉴了语言模型,还有BERT的优缺点。具体做法如下:
首先,生成模型是单向的,即便我们使用Bidirectional LSTM类模型,其实本质是使用了两套单向的模型。
通过使用permutation language model, 也就是把所有可能的permutation全部考虑进来。另外,为了迎合这种改变,他们在原来的Transformer Encoder架构上做了改进,引入双流注意力机制,
而且为了更好地处理较长的文本,进而使用的是Transformer-XL。
GCN
图卷积神经网络,实际上跟CNN的作用一样,就是一个特征提取器,只不过它的对象是图数据(结构十分不规则,数据不具有平移不变性,
这让适用于处理图片、语言这类欧氏空间数据的传统的CNN、RNN瞬间失效)。
GCN精妙地设计了一种从图数据中提取特征的方法,从而让我们可以使用这些特征去对图数据进行节点分类
(node classification)、图分类(graph classification)、边预测(link prediction),还可以顺便得到图的嵌入表示(graph embedding)。
在Step 4对evidence图进行编码的过程,实际上就相当于对图数据进行了特征的提取。
GCN也是一个神经网络层,层与层之间的传播方式如下(利用了拉普拉斯矩阵):
\]
需要说明的是
\(\tilde{A}=A+I\)为图的邻接矩阵,I为单位阵。
\(\tilde{D}\) 为 \(\tilde{A}\) 的度矩阵。\(H\) 为每一层的特征。对于输入层 \(H=X\).
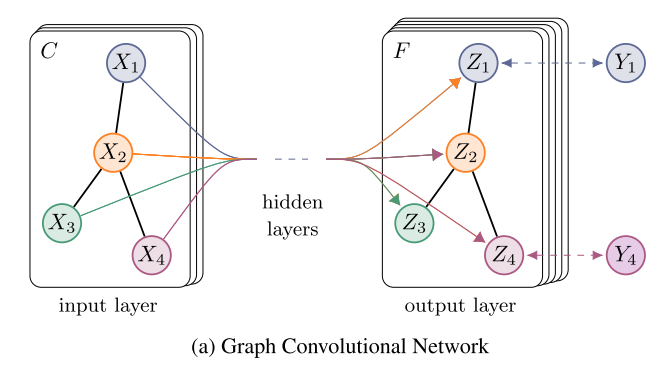
若构造一个两层的GCN来进行分类任务,激活函数分别采用ReLU和softmax,则整体的正向传播公式为:
\]
上图中的GCN输入一个图,通过若干层GCN每个node的特征从X变成了Z,但是,无论中间有多少层,node之间的连接关系,即A,都是共享的。
GCN的特别之处:即使不训练,完全使用随机初始化的参数W,GCN提取出来的特征就已经非常优秀了!
GAT
和所有的attention mechanism一样,GAT的计算也分为两步走:
计算注意力系数;对于顶点i,注意计算它与它的邻接节点的相似系数
\[e_{i j}=a\left(W \overrightarrow{h_{i}}, W \overrightarrow{h_{j}}\right)
\]其中共享参数W的线性映射给顶点的特征进行了增强,a(·)把拼接后的高维特征映射到一个实数上,
这个过程一般通过一个单层的前馈神经网络来实现.对相关系数用softmax进行归一化便得到了注意力系数。
要理解计算过程可见下图。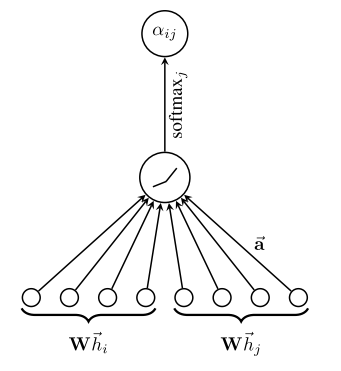
加权求和。把计算好的注意力系数进行加权求和,加上多头机制进行增强
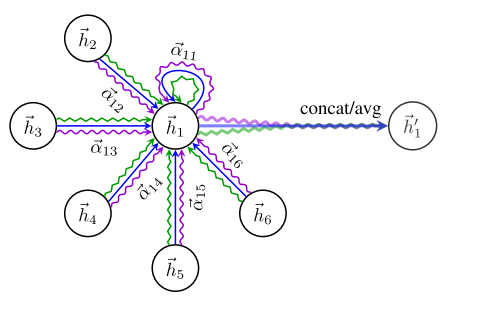
GCN与GAT的异同
- 同:GCN与GAT都是将邻居顶点的特征聚合到中心顶点上(一种aggregate运算),利用graph上的局部平稳性学习新的顶点特征表达。
- 异:GCN利用了拉普拉斯矩阵,GAT利用attention系数。
为什么要融合异构知识源?
- 结构化知识 (Structured Knowledge Source):包含大量的三元组信息(概念及其之间的关系),利于推理,但是存在覆盖度低的问题;
- 非结构化知识 (Unstructured Knowledge Source):即 Plain-Text,包含大量冗余的、覆盖范围广的信息,可以辅助/补充结构化知识;
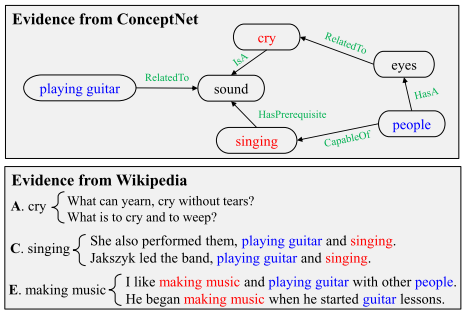
在结构化知识和非结构化知识的协同作用下,模型选出了最佳答案。
《Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering》论文整理的更多相关文章
- Improving Commonsense Question Answering by Graph-based Iterative Retrieval over Multiple Knowledge Sources —— 基于多知识库迭代检索的常识问答系统
基于多知识库迭代检索的问答系统 论文地址 背景 常识问答任务需要引入外部知识来帮助模型更好地理解自然语言问题,现有的解决方案大都采用两阶段框架: 第一阶段 -- 从广泛的知识来源中找到与给定问题相关的 ...
- Graph Based SLAM 基本原理
作者 | Alex 01 引言 SLAM 基本框架大致分为两大类:基于概率的方法如 EKF, UKF, particle filters 和基于图的方法 .基于图的方法本质上是种优化方法,一个以最小化 ...
- 论文笔记:Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering
Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering 2019-04-25 21: ...
- Learning Conditioned Graph Structures for Interpretable Visual Question Answering
Learning Conditioned Graph Structures for Interpretable Visual Question Answering 2019-05-29 00:29:4 ...
- 论文阅读-Temporal Phenotyping from Longitudinal Electronic Health Records: A Graph Based Framework
- cvpr2015papers
@http://www-cs-faculty.stanford.edu/people/karpathy/cvpr2015papers/ CVPR 2015 papers (in nicer forma ...
- Official Program for CVPR 2015
From: http://www.pamitc.org/cvpr15/program.php Official Program for CVPR 2015 Monday, June 8 8:30am ...
- CVPR 2015 papers
CVPR2015 Papers震撼来袭! CVPR 2015的文章可以下载了,如果链接无法下载,可以在Google上通过搜索paper名字下载(友情提示:可以使用filetype:pdf命令). Go ...
- 一次关于关系抽取(RE)综述调研的交流心得
本文来自于一次交流的的记录,{}内的为个人体会. 基本概念 实事知识:实体-关系-实体的三元组.比如, 知识图谱:大量实时知识组织在一起,可以构建成知识图谱. 关系抽取:由于文本中蕴含大量事实知识,需 ...
随机推荐
- [LeetCode]647. 回文子串(DP)
###题目 给定一个字符串,你的任务是计算这个字符串中有多少个回文子串. 具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被计为是不同的子串. 示例 1: 输入: "abc&q ...
- [HDU2553]N皇后问题(DFS)
题目链接 http://acm.hdu.edu.cn/showproblem.php?pid=2553 题意 n<=10,输出N皇后问题的方法数. 题解 可以使用各种方法.这里使用DFS. 使用 ...
- docker 部署 zabbix
docker部署zabbix 我相信大家都已经会再物理机上跑zabbix并且监控了,那么有没有想过在docker中跑zabbix?下面咱们来看看如何在docker中搭建zabbix并且监控 部署环 ...
- hystrix熔断器之metrics
Metric概述 HystrixCommands和HystrixObservableCommands执行过程中,会产生执行的数据,这些数据对于观察调用的性能表现非常有用. 命令产生数据后,Metric ...
- java中对 闰年的计算 以及月份天数
import java.io.*;//局部变量的使用import java.util.Scanner; public class HelloJava { public static void ...
- 7种jvm垃圾回收器,这次全部搞懂
前言 之前我们讲解了jvm的组成结构与垃圾回收算法等知识点,今天我们来讲讲jvm最重要的堆内存是如何使用垃圾回收器进行垃圾回收,并且如何使用命令去配置使用这些垃圾回收器. 堆内存详解 上面这个图大家应 ...
- jQuery中使用$.each()遍历数组时要注意的地方
使用jQuery中 $.each()遍历数组,要遍历的数组不能为空(arry!="") 例如: $.each(arry, function (i, item) ...
- windows10 + docker利用文件映射进行编程开发
0. 以安装swoole框架"easyswoole"举例,建议使用powershell或者cmder输入命令 1. 首先准备好window10专业版开启Hyper-V,然后下载 ...
- 实验 6:OpenDaylight 实验——OpenDaylight 及 Postman 实现流表下发
一.实验目的 熟悉 Postman 的使用;熟悉如何使用 OpenDaylight 通过 Postman 下发流表. 二.实验任务 流表有软超时和硬超时的概念,分别对应流表中的 idle_timeou ...
- OpenCV计算机视觉学习(2)——图像算术运算 & 掩膜mask操作(数值计算,图像融合,边界填充)
在OpenCV中我们经常会遇到一个名字:Mask(掩膜).很多函数都使用到它,那么这个Mask到底是什么呢,下面我们从图像基本运算开始,一步一步学习掩膜. 1,图像算术运算 图像的算术运算有很多种,比 ...