JVM大作业5——指令集
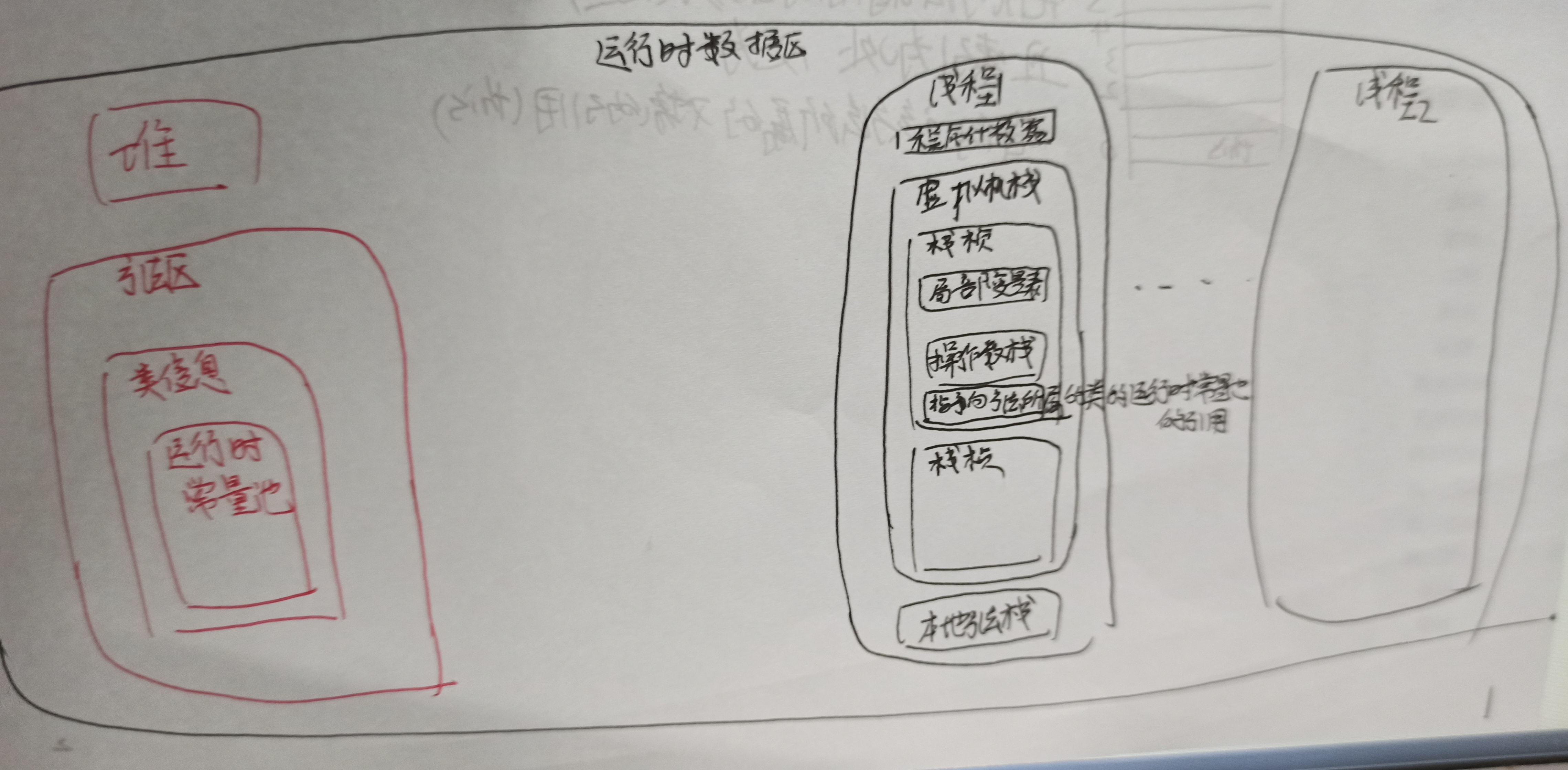
JVM的每一个线程都有一个虚拟机栈,方法调用时,JVM会在虚拟机栈内为该方法创建一个栈帧。
一条线程,只有正在执行的方法对应的栈帧时可活动的,这个栈帧被称为当前栈帧,当前栈帧对应的方法被称为当前方法,当前方法对应的类被称为当前类
任何对于局部变量表和操作数栈的操作,都是对当前栈帧的局部变量表和操作数栈的操作
方法开始时,栈帧入栈。方法结束时,栈帧出栈,栈帧把自己的执行结果传给前一个栈帧。
!!局部变量表中:long和double占2个位置(低32位先入,后32位后入),其他的都占一个位置。
!!操作数栈:long和double占2个位置(低32位占据index,高32位占据index+1),其他都占一个位置
操作数栈:有许多指令可以从操作数栈取出数据,操作数据,然后把操作结果重新入栈。
以下为代码实现
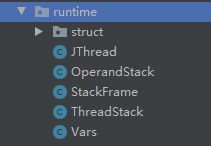
JTread类代表线程,StackFrame代表线程栈(虚拟机栈),ThreadStack为栈帧,Vars为局部变量表,OperandStack为操作数栈
以下探讨操作数栈中的double和long的存储
public void pushLong(long value) {//todo 向操作数栈中push一个long
int low32=(int)(value&0x00000000FFFFFFFF);
int high32=(int)(value>>32)&0x00000000FFFFFFFF;
if (top >= maxStackSize) throw new StackOverflowError();
slots[top].setValue(low32);
top++;
if (top >= maxStackSize) throw new StackOverflowError();
slots[top].setValue(high32);
top++;
}
public long popLong() {//todo 从操作数栈顶pop一个long
top--;
if (top < 0) throw new EmptyStackException();
int high=slots[top].getValue();
slots[top] = new Slot();
top--;
if (top < 0) throw new EmptyStackException();
int low=slots[top].getValue();
slots[top] = new Slot();
long result=((long)high<<32)|low;
return result;
}
public void pushDouble(double value) {//todo
long longvalue=Double.doubleToLongBits(value);
int low32=(int)longvalue&0x00000000FFFFFFFF;
int high32=(int)(longvalue>>32)&0x00000000FFFFFFFF;
if (top >= maxStackSize) throw new StackOverflowError();
slots[top].setValue(low32);
top++;
if (top >= maxStackSize) throw new StackOverflowError();
slots[top].setValue(high32);
top++;
}
public double popDouble() {//todo 从操作数栈顶pop一个double
top--;
if (top < 0) throw new EmptyStackException();
int high=slots[top].getValue();
slots[top]=new Slot();
top--;
if (top < 0) throw new EmptyStackException();
int low=slots[top].getValue();
slots[top] = new Slot();
long resultLong=((long)high<<32)|low;
return Double.longBitsToDouble(resultLong);
}
以下为vars中存储long和double的操作
public void setLong(int index, long value) {
if (index < 0 || index >= maxSize) throw new IndexOutOfBoundsException();
int low=(int)(value&0x00000000FFFFFFFF);
int high=(int)((value>>32)&0x00000000FFFFFFFF);
varSlots[index].setValue(low);
varSlots[index+1].setValue(high);
}
/**
* TODO:从局部变量表读取一个long类型变量
* @param index 变量的起始下标
* @return 变量的值
*/
public long getLong(int index){
if (index < 0 || index + 1 >= maxSize) throw new IndexOutOfBoundsException();
int low=varSlots[index].getValue();
int high=varSlots[index+1].getValue();
long result=((long)high<<32)|low;
return result;
}
public void setDouble(int index, double value) {
if (index < 0 || index + 1 >= maxSize) throw new IndexOutOfBoundsException();
long longvalue=Double.doubleToLongBits(value);
int low32=(int)longvalue&0x00000000FFFFFFFF;
int high32=(int)(longvalue>>32)&0x00000000FFFFFFFF;
varSlots[index].setValue(low32);
varSlots[index+1].setValue(high32);
}
public double getDouble(int index) {
if (index < 0 || index + 1 >= maxSize) throw new IndexOutOfBoundsException();
int low=varSlots[index].getValue();
int high=varSlots[index+1].getValue();
long resultLong=((long)high<<32)|low;
return Double.longBitsToDouble(resultLong);
}
DLOAD指令集
public class DLOAD extends Index8Instruction {
@Override
public void execute(StackFrame frame) {
System.out.println("执行了DLOAD的execute");
OperandStack stack=frame.getOperandStack();
Vars vars=frame.getLocalVars();
//一个double拆成两个int存在局部变量表中
int value1=vars.getInt(index);
int value2=vars.getInt(index+1);
long resultLong=((long)value2)<<32|value1;
double result=Double.longBitsToDouble(resultLong);
stack.pushDouble(result);
}
}
!!位运算要注意通过类型转换来扩充或减小位数
JVM大作业5——指令集的更多相关文章
- 数据库大作业--由python+flask
这个是项目一来是数据库大作业,另一方面也算是再对falsk和python熟悉下,好久不用会忘很快. 界面相比上一个项目好看很多,不过因为时间紧加上只有我一个人写,所以有很多地方逻辑写的比较繁琐,如果是 ...
- 程设大作业xjb写——魔方复原
鸽了那么久总算期中过[爆]去[炸]了...该是时候写写大作业了 [总不能丢给他们不会写的来做吧 一.三阶魔方的几个基本定义 ↑就像这样,可以定义面的称呼:上U下D左L右R前F后B UD之间的叫E,LR ...
- 大作业NABC分析结果
大作业NABC分析结果 这次的大作业计划制作一款关于七巧板的游戏软件.关于编写的APP的NABC需求分析: N:需求 ,本款软件主要面向一些在校的大学生,他们在校空闲时间比较多,而且热衷于一些益智类游 ...
- [留念贴] C#开发技术期末大作业——星月之痕
明天就要去上海大学参加 2015赛季 ACM/ICPC最后一场比赛 —— EC-Final,在这之前,顺利地把期末大作业赶出来了. 在这种期末大作业10个人里面有9个是从网上下载的国内计算机水平五六流 ...
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- 爬虫综合大作业——网易云音乐爬虫 & 数据可视化分析
作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075 爬虫综合大作业 选择一个热点或者你感兴趣的主题. 选择爬取的对象 ...
- 期末Java Web大作业----简易的学生管理系统
学生信息管理系统(大作业) 2018-12-21:此文章已在我的网站更新,添加视图介绍等信息,源码请移步下载https://www.jeson.xin/javaweb-sims.html PS:首先不 ...
- CSAPP HITICS 大作业 hello's P2P by zsz
摘 要 摘要是论文内容的高度概括,应具有独立性和自含性,即不阅读论文的全文,就能获得必要的信息.摘要应包括本论文的目的.主要内容.方法.成果及其理论与实际意义.摘要中不宜使用公式.结构式.图表和非公知 ...
- #006 C语言大作业学生管理系统第三天
还差最后两部分 读取文件 恢复删除的学生信息 先学会处理文件的 知识点,再继续跟着视频做这个作业. 应该明天周六能把视频里手把手教的学生管理系统敲完 第二周尽量自己能完成C语言课本最后面那道学生管理系 ...
随机推荐
- PHP xml_set_element_handler() 函数
定义和用法 xml_set_element_handler() 函数规定在 XML 文档中元素的起始和终止调用的函数. 如果成功,该函数则返回 TRUE.如果失败,则返回 FALSE.高佣联盟 www ...
- PHP hex2bin() 函数
实例 把十六进制值转换为 ASCII 字符: <?phpecho hex2bin("48656c6c6f20576f726c6421");?> 以上实例输出结果: He ...
- PHP fprintf() 函数
实例 把一些文本写入到名为 "test.txt" 的文本文件: <?php高佣联盟 www.cgewang.com$number = 9;$str = "Beiji ...
- C/C++编程笔记:《C语言》—— 数组知识详解,学编程建议收藏!
作者:龙跃十二链接:https://www.imooc.com/article/300814 ,微信公众号:龙跃十二 数组的基本概念 我们把一组数据的集合称为数组(Array),它所包含的每一个数据叫 ...
- P4274 [NOI2004]小H的小屋 dp 贪心
LINK:小H的小屋 尽管有论文 但是 其证明非常的不严谨 结尾甚至还是大胆猜测等字样... 先说贪心:容易发现m|n的时候此时均分两个地方就是最优的. 关于这个证明显然m在均分的时候的分点一定是n的 ...
- 【02python基础-函数,类】
1.函数中的全局变量与局部变量全局变量:在函数和类定义之外声明的变量.作用域为定义的模块,从定义位置开始到模块结束.全局变量降低了函数的通用性和可读性,要尽量避免全局变量的使用.全局边个两一般作为常量 ...
- UML科普文,一篇文章掌握14种UML图
前言 上一篇文章写了一篇建造者模式,其中有几个UML类图,有的读者反馈看不懂了,我们今天就来解决一哈. 什么是UML? UML是Unified Model Language的缩写,中文是统一建模语言, ...
- ubuntu apt-get 安装找不到包问题
1.首先 sudo gedit /etc/apt/sources.list 删除全部换成国内源 (推荐163) 2.考虑 ubuntu apt-get update失败 1.出现错误:E:Could ...
- Zabbix5 Frame 嵌套
Zabbix5 Frame 嵌套 Zabbix 默认不允许嵌套在其他页面上,通过修改配置允许嵌套 找到 Zabbix 下面的 include/defines.inc.php 文件,末尾有一行 defi ...
- HRNet