从0到1进行Spark history分析
一、总体思路
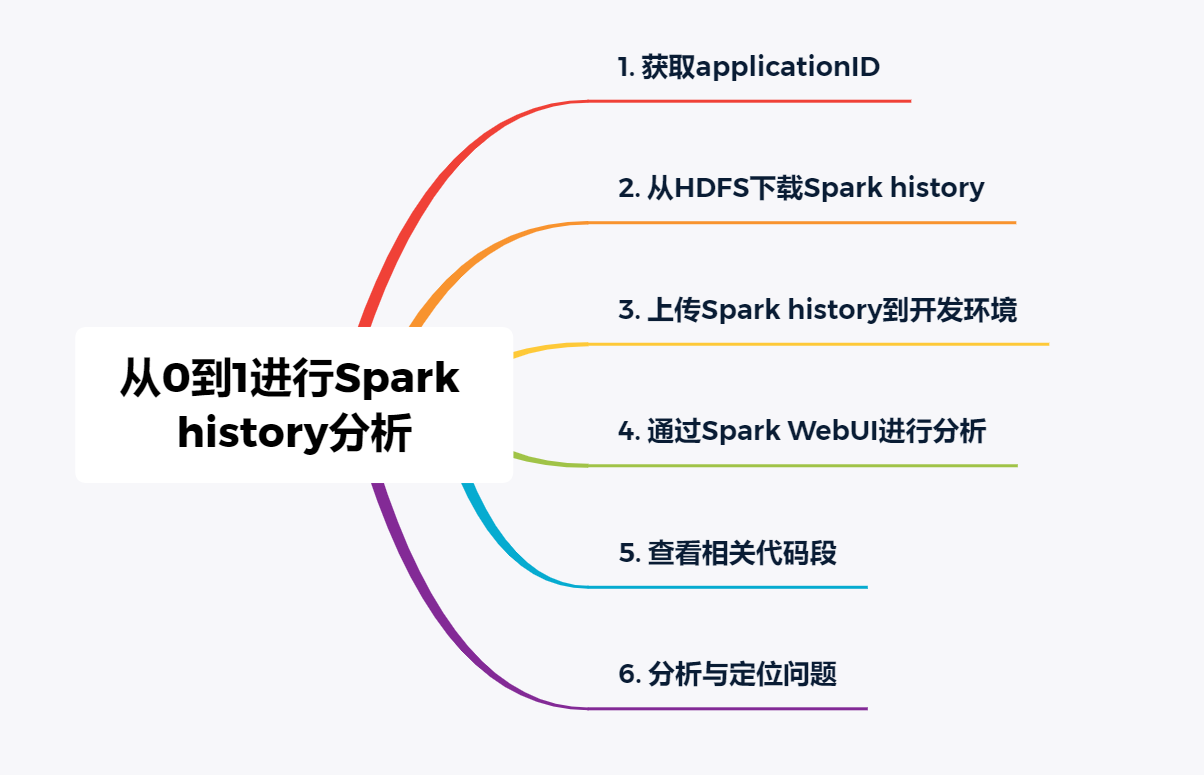
以上是我在平时工作中分析spark程序报错以及性能问题时的一般步骤。当然,首先说明一下,以上分析步骤是基于企业级大数据平台,该平台会抹平很多开发难度,比如会有调度日志(spark-submit日志)、运维平台等加持,减少了开发人员直接接触生成服务器命令行的可能,从物理角度进行了硬控制,提高了安全性。
下面我将带领大家从零到一,从取日志,到在Spark WebUI进行可视化分析相关报错、性能问题的方法。
二、步骤
(一)获取applicationID
1.从调度日志获取
一般企业级大数据平台会相对重视日志的采集,这不仅有助于事后对相关问题、现象的分析;同时也是相关审计环节的要求。
我们知道,spark的调度是通过spark-submit执行触发的,每一次spark-submit都会有对应的applicationID生成,所以,一般我们可以在调度日志中可以找到本次调度的applicationID。
2.从运维平台获取
企业级大数据平台为了减少开发、运维人员直接通过ftp、putty、xshell等工具直连生产服务器,避免误操作等风险发生,一般会提供一个运维平台,在页面上便可直接查看到job粒度的作业运行情况,以及其唯一标志applicationID,缩短了开发、运维人员获取applicationID的“路径”,减少了机械性的步骤。
(二)从HDFS下载Spark history
我们假设我们的大数据平台把spark history保存到了HDFS的/sparkJobHistory/ 目录下,下面我们来看看具体如何获取我们对应applicationID的spark history。
1.命令行下载HDFS文件
hadoop fs -get /sparkJobHistory/applicationID_xxxxx_1-meta localfile
hadoop fs -get /sparkJobHistory/applicationID_xxxxx_1-part1 localfile
2.HUE工具下载HDFS文件
我们使用租户登录HUE工具,进入到File Browser页面,并通过页面上的目录访问按钮进入到sparkJobHistory目录下,然后在搜索框中输入applicationID ,就可以看到该applicationID对应的spark history(meta和part1两个文件)显示在了页面中,勾选并下载,便可以将spark history下载到我们本地。
(三)上传Spark history到开发环境
接下来我们要做的工作就是将从生产上获取到的spark history放到我们开发环境上,以便进行后续分析。
1.命令行推送spark history到HDFS上
首先我们需要将从生产下载到本地的spark history上传到我们测试环境的任意一个节点上,这里我们将其上传到测试环境01节点的${WORK_ROOT}/etluser/tmp/spark_history/applicationID_xxxxx/路径下,接下来在测试环境命令行执行以下命令,将spark history上传到HDFS:
hadoop fs -put ${WORK_ROOT}/etluser/tmp/spark_history/applicationID_xxxxx/* /sparkJobHistory/
2.HUE工具上传spark history到HDFS上
这个步骤和我们在生产HUE类似,首先使用租户登录到测试环境HUE,然后进入File Browser的/sparkJobHistory/路径下,点击Upload按钮,上传spark history到该路径下即可。
(四)Spark WebUI进行分析
1.搜索applicationID
进入Spark WebUI页面,在搜索框输入applicationID,即可筛选出该applicationID的spark history。
2.进行stage可视化分析
点击该App ID进去即可看到该applicationID的每一个Job详细运行情况;点击进一个Job,即可看到该Job的DAG图,以及对应的stage运行情况;点击进一个stage,即可看到该stage下所有的task运行情况。通过每一个页面上的运行耗时、GC时间、input/output数据量大小等,根据这些信息即可分析出异常的task、stage、job。
(五)查看相关代码段
1.定位异常Job
通过applicationID进入到我们要分析的Job的运行情况页面后,可以看到该App ID下每一个Job,一般通过观察每一个Job的运行时长可以识别出哪一个Job是异常的,通常运行时间过长的Job就是异常的,可以进入该Job的详细页面进行进一步分析。
2.回溯Job对应代码段
一般定位到异常的Job我们就可以知道对应的代码段,通常这个Job运行情况页会显示其对应的代码行,通过回到代码中找到这个代码行,其前后一小部分代码段就是这个异常Job的执行代码段。
(六)分析与定位问题
1.列出代码段涉及的源表
如果是SparkSQL代码,可以通过SQL直观获取到其所涉及的源表,将这些源表记录下来,以便后续分析。
如果是SparkRDD代码,可以通过代码中所使用的数据集追溯到该数据集所对应的源表,同样,我们把它们记录下来,以便后续进行分析。
2.分析源表的使用方式:广播、普通关联、…
我们可以通过代码中分析出这些源表的使用方式。最常见的应该是对小表进行广播的方式。所谓广播,就是把小表的数据完整地发送到集群的各个DataNode本地缓存起来,当大表与之进行关联操作时,存在于各个DataNode之上的大表数据块便可以根据就近计算原则,与小表数据进行关联计算,从而减少了网络传输,提高了运行速度。
在SparkSQL中,一般如果大表和小表进行关联,会通过hint语法对小表进行广播,具体来说是使用/*mapjoin(small_table_name)*/这样的形式。
而在SparkRDD中,一般也会对小表进行广播操作,通过broadcast()接口进行实现。在Java中,具体来说是使用Broadcast data_broadcast = JavaSparkContext.broadcast(table_data.collect());这样的语法进行实现。
对于普通关联,即没有对表进行特殊处理的关联。这种写法一般在大小表关联的场景下容易出现性能问题,需要特别关注。经常可以作为问题分析的切入点。
3.查看源表数据量
一般通过第一步把问题代码段中所涉及的源表罗列出来后,就需要到生产查看这些源表的数据量是多少,以方便分析是否是因为数据量过大而导致的性能问题,一般如果是数据量导致的问题,多半是因为资源不足,可以考虑通过调整资源数量来解决。
当然,除了常规的查看源表的记录数外,还可以查看该表在HDFS上占用的空间大小。
查看源表记录数SQL:
select count(1) as cnt from db_name.table_name where pt_dt=’xxxx-xx-xx’;
查看源表占用的空间大小,这里使用GB为单位(102410241024)显示:
hadoop fs -du /user/hive/warehouse/db_name.db/ table_name/pt_dt='xxxx-xx-xx' | awk ‘${SUM+=$1} END {print SUM/(1024*1024*1024)}'
4.查看源表数据块分布情况
有时候源表的数据量并不算大,但是还是出现了性能瓶颈,这时候通过观察tasks数的多少,大致可以猜测到是因为源表的数据块大小分布不均匀,或是数据块过少导致的。可以通过以下命令查看源表的数据块分布情况:
hadoop fs -ls -h /user/hive/warehouse/db_name.db/ table_name/pt_dt='xxxx-xx-xx'
通过该命令的输出我们可以看到源表的每一个数据块大小,以此有多少个数据块。举个例子,如果数据块只有2~3块,第一个数据块有80MB,第二、第三个数据块分别只有1KB,那基本可以判定这几个数据块分布不合理。
数据块分布不合理可以通过对源表数据进行重分布(repartition)或设置spark处理的每个map数据块大小上限来前置将过大的数据块分散到各个task中处理,以减少关键task的处理耗时,提升程序性能。
三、总结
本文深入浅出,具体到步骤和实际操作,带领大家从获取作业applicationID,到下载Spark history,再到上传Spark history至开发环境,再进行Spark WebUI分析异常stage,再而定位到问题代码段,最后给出一般问题的分析方向以及分析方法。
对于Spark相关问题的分析,最直接有效的就是对Spark history的分析了,希望大家能通过练习和实操掌握这项技能。当然,平时进行Spark、Hadoop生态体系的理论知识积累也是必不可少的,所谓万丈高楼平地起,根基要稳,才能让楼起得更高。
从0到1进行Spark history分析的更多相关文章
- Apache Spark 2.2.0 中文文档 - Spark RDD(Resilient Distributed Datasets)论文 | ApacheCN
Spark RDD(Resilient Distributed Datasets)论文 概要 1: 介绍 2: Resilient Distributed Datasets(RDDs) 2.1 RDD ...
- Spark集群之Spark history server额外配置
Note: driver在SparkContext使用stop()方法后才将完整的信息提交到指定的目录,如果不使用stop()方法,即使在指定目录中产生该应用程序的目录,history server ...
- Spark源代码分析之六:Task调度(二)
话说在<Spark源代码分析之五:Task调度(一)>一文中,我们对Task调度分析到了DriverEndpoint的makeOffers()方法.这种方法针对接收到的ReviveOffe ...
- 【转】Spark History Server 架构原理介绍
[From]https://blog.csdn.net/u013332124/article/details/88350345 Spark History Server 是spark内置的一个http ...
- Apache Spark 2.2.0 中文文档 - Spark RDD(Resilient Distributed Datasets)
Spark RDD(Resilient Distributed Datasets)论文 概要 1: 介绍 2: Resilient Distributed Datasets(RDDs) 2.1 RDD ...
- Android 9.0 默认输入法的设置流程分析
Android 输入法设置文章 Android 9.0 默认输入法的设置流程分析 Android 9.0 添加预置第三方输入法/设置默认输入法(软键盘) 前言 在上一篇文章 Android 9.0 ...
- Spark History Server配置使用
Spark history Server产生背景 以standalone运行模式为例,在运行Spark Application的时候,Spark会提供一个WEBUI列出应用程序的运行时信息:但该WEB ...
- Spark学习笔记-使用Spark History Server
在运行Spark应用程序的时候,driver会提供一个webUI给出应用程序的运行信息,但是该webUI随着应用程序的完成而关闭端口,也就是 说,Spark应用程序运行完后,将无法查看应用程序的历史记 ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
随机推荐
- Python の 在 VSCode 中使用 IPython Kernel 的方法
本文介绍,在 VSCode 使用 IPython Kernel,的设置方法. 要达到的效果: 只需按下 Ctrl+:,选中的几行代码,就会自动发送到 IPython Kernel,并运行,得到结果!当 ...
- web前端笔记(包含php+laravel)
概况 熟悉HTML5.CSS3.JavaScript.ES6规范 熟悉JQuery框架 熟悉BootStrap 熟悉Less.Sass 熟悉Vue 熟悉Git postman Bootstrap 布局 ...
- webservice的某些配置
ajax调用的时候配置 <system.webServer> <validation validateIntegratedModeConfiguration="false& ...
- 企业邮箱选择,商务办公为什么选TOM企业邮箱?
企业邮箱是工作中的重要工具,它可以帮助我们更规范的上传下达.更高效的管理工作,也是拓展合作伙伴的敲门砖及必杀技.比如写一封诚意满满的合作邀请,再比如重要关头写一封合作协议.毫不夸张,企业邮箱不仅能节省 ...
- Mybatis源码如何阅读,教你一招!!!
前言 前一篇文章简单的介绍了Mybatis的六个重要组件,这六剑客占据了Mybatis的半壁江山,和六剑客搞了基友,那么Mybatis就是囊中之物了.对六剑客感兴趣的朋友,可以看看这篇文章:Mybat ...
- Book of Shaders 02 - 矩阵:二维仿射变换练习
0x00 一些废话 如果要深入学习 CG (Computer Graphics,计算机图形学),必然要学习相关的数学知识.CG 涉及到多个不同的领域,根据所研究领域的不同,也会涉及到不同的数学分支.但 ...
- 分布式系统监视zabbix讲解三之用户和用户组
概述 Zabbix 中的所有用户都通过 Web 前端去访问 Zabbix 应用程序.并为每个用户分配唯一的登陆名和密码. 所有用户的密码都被加密并储存于 Zabbix 数据库中.用户不能使用其用户名和 ...
- Node.js 从零开发 web server博客项目[express重构博客项目]
web server博客项目 Node.js 从零开发 web server博客项目[项目介绍] Node.js 从零开发 web server博客项目[接口] Node.js 从零开发 web se ...
- archaius(3) 配置管理器
基于上一节介绍的配置源,我们来继续了解配置管理器.配置源只是抽象了配置的获取来源,配置管理器是基于配置源的基础上对这些配置项进行管理.配置管理器的主要功能是将配置从目标位置加载到内存中,并且管理内存配 ...
- 11.深入k8s:kubelet工作原理及源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 kubelet信息量是很大的,通过我这一篇文章肯定是讲不全的,大家可 ...