day23 常用模块(中)
一、json&pickle模块
1 什么是序列化
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
2 为什么要序列化
2.1 持久保存状态
程序和软件的运行就是在处理一系列状态的变化,运行时是保存在内存中的,但是内存断电就会丢失数据,我们要在断电前把数据保存到文件中这就是序列化
2.2 跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,unpickling。
3 如何序列化
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
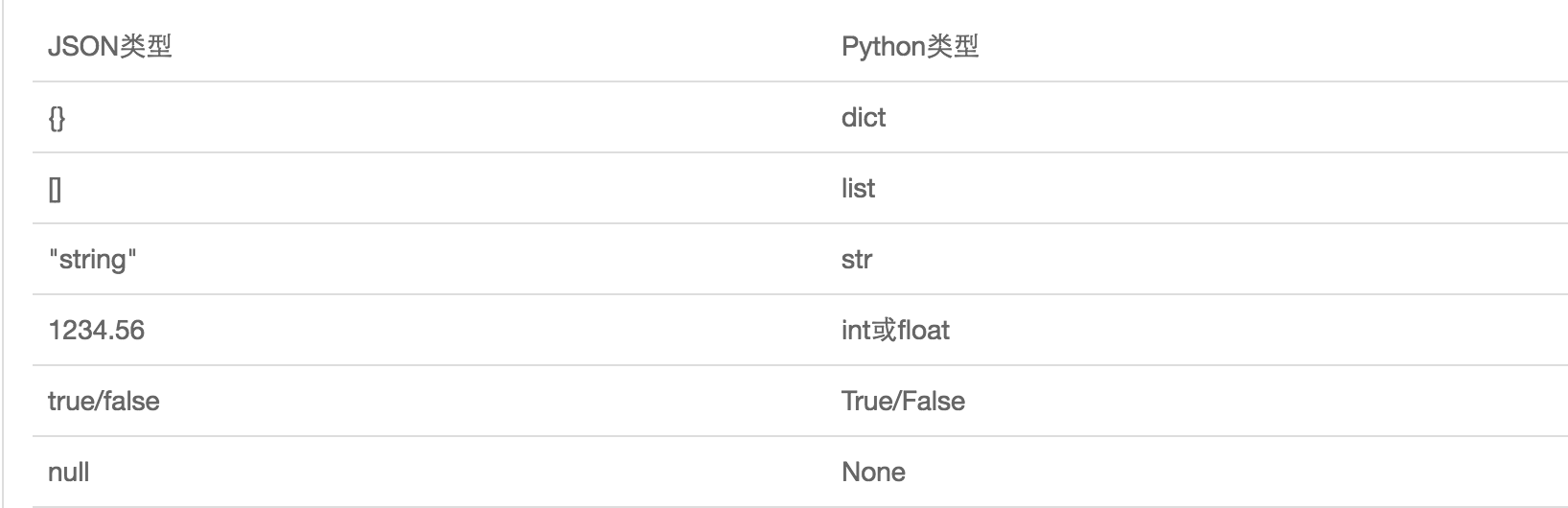
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:

import json
l = [1,'a',True,False]
#序列化
with open("b.txt","w",encoding="utf-8")as f :
#麻烦方式
# json_l = json.dumps(l)
# f.write(json_l)
#简单方法
json.dump(l,f)
#反序列化
with open("a.txt","r",encoding='utf-8')as f:
#麻烦方式
# srt = f.read()
# res= json.loads(srt)
# print(res)
#简单方法
l = json.load(f)
print(l)
补充:猴子补丁
# 一.什么是猴子补丁?
猴子补丁的核心就是用自己的代码替换所用模块的源代码,详细地如下
1,这个词原来为Guerrilla Patch,杂牌军、游击队,说明这部分不是原装的,在英文里guerilla发音和gorllia(猩猩)相似,再后来就写了monkey(猴子)。
2,还有一种解释是说由于这种方式将原来的代码弄乱了(messing with it),在英文里叫monkeying about(顽皮的),所以叫做Monkey Patch。
# 二. 猴子补丁的功能(一切皆对象)
1.拥有在模块运行时替换的功能, 例如: 一个函数对象赋值给另外一个函数对象(把函数原本的执行的功能给替换了)
class Monkey:
def hello(self):
print('hello')
def world(self):
print('world')
def other_func():
print("from other_func")
monkey = Monkey()
monkey.hello = monkey.world
monkey.hello()
monkey.world = other_func
monkey.world()
# 三.monkey patch的应用场景
如果我们的程序中已经基于json模块编写了大量代码了,发现有一个模块ujson比它性能更高,
但用法一样,我们肯定不会想所有的代码都换成ujson.dumps或者ujson.loads,那我们可能
会想到这么做
import ujson as json,但是这么做的需要每个文件都重新导入一下,维护成本依然很高
此时我们就可以用到猴子补丁了
只需要在入口处加上
, 只需要在入口加上:
import json
import ujson
def monkey_patch_json():
json.__name__ = 'ujson'
json.dumps = ujson.dumps
json.loads = ujson.loads
monkey_patch_json() # 之所以在入口处加,是因为模块在导入一次后,后续的导入便直接引用第一次的成果
#其实这种场景也比较多, 比如我们引用团队通用库里的一个模块, 又想丰富模块的功能, 除了继承之外也可以考虑用Monkey
Patch.采用猴子补丁之后,如果发现ujson不符合预期,那也可以快速撤掉补丁。个人感觉Monkey
Patch带了便利的同时也有搞乱源代码的风险!
猴子补丁与ujson
pickle

import pickle
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=pickle.dumps(dic)
print(type(j))#<class 'bytes'>
f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f)
f.close()
#-------------------------反序列化
import pickle
f=open('序列化对象_pickle','rb')
data=pickle.loads(f.read())# 等价于data=pickle.load(f)
print(data['age'])
二、shelve模块
import shelve
#shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,
#可读可写;key必须为字符串,而值可以是python所支持的数据类型
f=shelve.open(r'sheve.txt')
# f['stu1_info']={'name':'egon','age':18,'hobby':['piao','smoking','drinking']}
# f['stu2_info']={'name':'gangdan','age':53}
# f['school_info']={'website':'http://www.pypy.org','city':'beijing'}
print(f['stu1_info']['hobby'])
f.close()
三、configparser模块
可以通过创建ini后缀的文档来存放配置信息
配置文件如下:
# 注释1
; 注释2
[section1]
k1 = v1
k2:v2
user=egon
age=18
is_admin=true
salary=31
[section2]
k1 = v1
读取:
import configparser
config=configparser.ConfigParser()
config.read('a.cfg')
#查看所有的标题
res=config.sections() #['section1', 'section2']
print(res)
#查看标题section1下所有key=value的key
options=config.options('section1')
print(options) #['k1', 'k2', 'user', 'age', 'is_admin', 'salary']
#查看标题section1下所有key=value的(key,value)格式
item_list=config.items('section1')
print(item_list) #[('k1', 'v1'), ('k2', 'v2'), ('user', 'egon'), ('age', '18'), ('is_admin', 'true'), ('salary', '31')]
#查看标题section1下user的值=>字符串格式
val=config.get('section1','user')
print(val) #egon
#查看标题section1下age的值=>整数格式
val1=config.getint('section1','age')
print(val1) #18
#查看标题section1下is_admin的值=>布尔值格式
val2=config.getboolean('section1','is_admin')
print(val2) #True
#查看标题section1下salary的值=>浮点型格式
val3=config.getfloat('section1','salary')
print(val3) #31.0
四、hashlib模块
1 什么时候hash
hash是一种算法,该算法接受传入的内容,经过运算得到一串hash值
hash值的特点
只要传入的内容一样,得到的hash值必然一样
=======》用于明文传输密码和文件完整性校验
不能由hash值返解成内容
=======》把密码做成hash值,不应该在网络传输明文密码、
只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的
hash加密的基本操作:
import hashlib
m = hashlib.md5()
m.update("aaaa".encode("utf-8"))
print(m.hexdigest())
>>>74b87337454200d4d33f80c4663dc5e5
m.update("bbbb".encode("utf-8"))
print(m.hexdigest())
>>>c622054d9e6f17b43814ad5d61cab239
五、subprocess模块
import subprocess
'''
sh-3.2# ls /Users/egon/Desktop |grep txt$
mysql.txt
tt.txt
事物.txt
'''
res1=subprocess.Popen('ls /Users/jieli/Desktop',shell=True,stdout=subprocess.PIPE)
res=subprocess.Popen('grep txt$',shell=True,stdin=res1.stdout,
stdout=subprocess.PIPE)
print(res.stdout.read().decode('utf-8'))
#等同于上面,但是上面的优势在于,一个数据流可以和另外一个数据流交互,可以通过爬虫得到结果然后交给grep
res1=subprocess.Popen('ls /Users/jieli/Desktop |grep txt$',shell=True,stdout=subprocess.PIPE)
print(res1.stdout.read().decode('utf-8'))
#windows下:
# dir | findstr 'test*'
# dir | findstr 'txt$'
import subprocess
res1=subprocess.Popen(r'dir C:\Users\HZ\PycharmProjects\py学习测试代码\pystudy\aaaa\bbbb.py',shell=True,stdout=subprocess.PIPE)
res=subprocess.Popen('findstr test*',shell=True,stdin=res1.stdout,
stdout=subprocess.PIPE)
print(res.stdout.read().decode('gbk')) #subprocess使用当前系统默认编码,得到结果为bytes类型,在windows下需要用gbk解码
day23 常用模块(中)的更多相关文章
- Python常用模块中常用内置函数的具体介绍
Python作为计算机语言中常用的语言,它具有十分强大的功能,但是你知道Python常用模块I的内置模块中常用内置函数都包括哪些具体的函数吗?以下的文章就是对Python常用模块I的内置模块的常用内置 ...
- python基础:os模块中关于文件/目录常用的函数使用方法
Python是跨平台的语言,也即是说同样的源代码在不同的操作系统不需要修改就可以同样实现 因此Python的作者就倒腾了OS模块这么一个玩意儿出来,有了OS模块,我们不需要关心什么操作系统下使用什么模 ...
- os模块中关于文件/目录常用的函数使用方法
os模块中关于文件/目录常用的函数使用方法 函数名 使用方法 getcwd() 返回当前工作目录 chdir(path) 改变工作目录 listdir(path='.') 列举指定目录中的文件名('. ...
- 18 os/os.path模块中关于文件/目录常用的函数使用方法 (转)
os模块中关于文件/目录常用的函数使用方法 函数名 使用方法 getcwd() 返回当前工作目录 chdir(path) 改变工作目录 listdir(path='.') 列举指定目录中的文件名('. ...
- os、os.path模块中关于文件、目录常用的函数使用方法
os模块中关于文件/目录常用的函数使用方法 函数名 使用方法 getcwd() 返回当前工作目录 chdir(path) 改变工作目录 listdir(path='.') 列举 ...
- python编程os、os.path 模块中关于文件、目录常用的函数使用方法
os模块中关于文件/目录常用的函数使用方法 函数名 使用方法 getcwd() 返回当前工作目录 chdir(path) 改变工作目录 listdir(path='.') 列举指定目录中的文件名( ...
- selenium.webdriver.common.keys 模块中常用的变量
表11-5 selenium.webdriver.common.keys 模块中常用的变量属性 含义Keys.DOWN, Keys.UP, Keys.LEFT,Keys.RIGHT 键盘箭头键Keys ...
- python—— 文件的打开模式和文件对象方法 & os、os.path 模块中关于文件、目录常用的函数使用方法
引用自“鱼c工作室” 文件的打开模式和文件对象方法 : https://fishc.com.cn/forum.php?mod=viewthread&tid=45279&ext ...
- python 中 模块,包, 与常用模块
一 模块 模块:就是一组功能的集合体, 我们的程序可以直接导入模块来复用模块里的功能 导入方式 一般为 : import 模块名 在python中, 模块一般分为四个通用类别 1使用python编写. ...
随机推荐
- 拉勾网 + selenium
目录 方式一 selenium 方式二普通方法 方式一 selenium from selenium import webdriver import time from selenium.webdri ...
- Mini Linux的制作过程
- 数列计算I(整理四舍五入)
问题 C: 数列计算I(点击) 时间限制: 1 Sec 内存限制: 128 MB ...
- python基础001----Python+pycharm环境搭建
一.Python下载安装 1.python下载-----下载地址:https://www.python.org/downloads/windows/ 在python的官网下载python版本,需要下载 ...
- 附024.Kubernetes全系列大总结
Kubernetes全系列总结如下,后期不定期更新.欢迎基于学习.交流目的的转载和分享,禁止任何商业盗用,同时希望能带上原文出处,尊重ITer的成果,也是尊重知识.若发现任何错误或纰漏,留言反馈或右侧 ...
- JVM对算术运算做了什么??
java可以进行数字的加减乘除,但是JVM的运算步骤是什么样子呢?从一个神奇的式子入手,研究下JVM到底做了什么? 先看下图:
- 磨皮美颜算法 附完整C代码
前言 2017年底时候写了这篇<集 降噪 美颜 虚化 增强 为一体的极速图像润色算法 附Demo程序> 这也算是学习过程中比较有成就感的一个算法. 自2015年做算法开始到今天,还有个把月 ...
- HTML躬行记(1)——SVG
<svg>是矢量图的根元素,通过xmlns属性声明命名空间,从而告诉用户代理标记名称属于哪个XML方言.在下面的示例中,为<svg>元素声明了宽度和高度(默认以像素为单位),其 ...
- Java将日期转化为大写格式(阿拉伯大写数字)
效果: 代码部分: public static void main(String[] args) { SimpleDateFormat sdf=new SimpleDateFormat("y ...
- 《Elasticsearch 权威指南》阅读笔记
书籍地址 https://www.elastic.co/guide/cn/elasticsearch/guide/current/languages.html