[MIT6.006] 6. AVL Trees, AVL Sort AVL树,AVL排序
之前第5节课留了个疑问,是关于“时间t被安排进R”的时间复杂度能不能为Ο(log2n)?”和BST时间复杂度Ο(h)的关系。第6节对此继续了深入的探讨。首先我们知道BST的h是指树的高,即从根到叶子结点最长路径的长度。但由于树结构不同平衡情况,高h的结果也不一样,如下图所示:

一、结点的高
由此可以看出,平衡树结构下的高h具有计算性。那么接下来我们再看下各结点的高(height of node)的计算方式,它是从该节点位置下到最底部的叶子节点的最长路径长度 (height of node = max(左子树高,右子树高) + 1):

二、AVL
我们如果想让Ο(h)=Ο(log2n),就必须把BST变为平衡树,但现实中,不一定所有数列都能构成完全的平衡树,但可以构成高度平衡树AVL(由Adelson-Velsky和E.M. Landis发明的),在该树下,每个结点的左右子树相差最多±1。如下图所示:
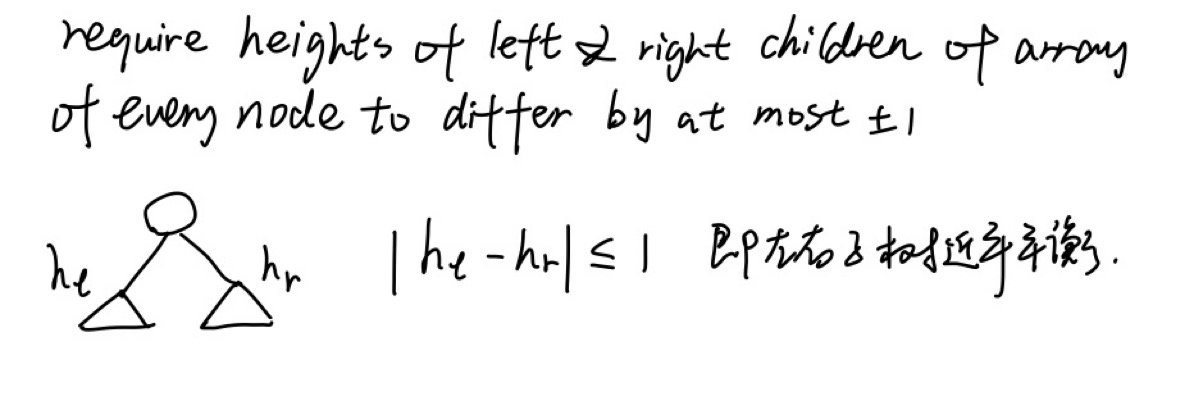
但有时会出现很糟糕的情况:右子树高比左子树高多1.

假设AVL节点数量为Nh,那么由上图,可得Nh = n = 1 + Nh-1 + Nh-2。这个如果算下去(课程没给出具体过程),会得到Nh > Fh = φh/√5,其中Fh是斐波那契数列(数字1,1,2,3,5,8-构成了一个序列。这个数列前面相邻两项之和,构成了后一项),φ=1.618,最后可以通过下图的得到h小于1.44log2n。
除了通过上述方法,还有种更简单的方法估算h的大小:
在该方法下得到的结果2log2n不如1.44log2n来的更为准确。
三、AVL的插入
AVL的插入分两步走:
- 简单的二分搜索树BST插入(simple BST insert);
- 从修改结点向上满足AVL属性,因为下面插入可能会影响上面的结果(Fix AVL property from changed node up)。
举个例子可能会更好的解释上面的步骤:
(注:蓝色箭头表明哪边子树比较重。)
上图我们给定了一个BST,然后按照BST插入的方法将23插入进去,我们会发现,29-26-23不符合AVL的属性。为了解决这个问题,AVL有个旋转Rotiation操作,如下图:
如果我们对29-26-23进行右旋转即可得到正确的AVL结构:
除了上面这种情况,如果出现下图这种插入55后的情况,可以使用双旋转操作(double/two rotation):
那么现在我们来假设一个通用场景,总结下AVL的调整方法。
假设x是最低违背AVL的结点,然后right(x)(或x.right)更高。出现下面两种情况则可以参考下面的旋转方案:
四、AVL排序
- 插入n个items - 每插入一个item要花费h时间,h在平衡树下为log2n,因此n个items为Ο(nlog2n) ;
- in-order traversal 按顺序遍历输出 - Ο(n) 。
五、总结
对于插入、删除、最小化,使用Heap和AVL就可以了,但是如果要求next_larger和next_smaller得要平衡二分查找树,不过现实很难满足完全平衡,那么用AVL高度平衡树来做也行。
[MIT6.006] 6. AVL Trees, AVL Sort AVL树,AVL排序的更多相关文章
- [MIT6.006] 4. Heaps and Heap Sort 堆,堆排序
第4节课仍然是讲排序,但介绍的是一种很高效的堆排序. 在编程过程中,有时候会需要进行extrat_max的操作,即从一个数列里挨个抽取最大值并将其它从原数列中移除.而排序问题也可以看作是一个extra ...
- Red Black Tree 红黑树 AVL trees 2-3 trees 2-3-4 trees B-trees Red-black trees Balanced search tree 平衡搜索树
小结: 1.红黑树:典型的用途是实现关联数组 2.旋转 当我们在对红黑树进行插入和删除等操作时,对树做了修改,那么可能会违背红黑树的性质.为了保持红黑树的性质,我们可以通过对树进行旋转,即修改树中某些 ...
- [MIT6.006] 7. Counting Sort, Radix Sort, Lower Bounds for Sorting 基数排序,基数排序,排序下界
在前6节课讲的排序方法(冒泡排序,归并排序,选择排序,插入排序,快速排序,堆排序,二分搜索树排序和AVL排序)都是属于对比模型(Comparison Model).对比模型的特点如下: 所有输入ite ...
- [MIT6.006] 1. Algorithmic Thinking, Peak Finding 算法思维,峰值寻找
[MIT6.006] 系列笔记将记录我观看<MIT6.006 Introduction to Algorithms, Fall 2011>的课程内容和一些自己补充扩展的知识点.该课程主要介 ...
- 定制对ArrayList的sort方法的自定义排序
java中的ArrayList需要通过collections类的sort方法来进行排序 如果想自定义排序方式则需要有类来实现Comparator接口并重写compare方法 调用sort方法时将Arr ...
- 用Java集合中的Collections.sort方法对list排序的两种方法
用Collections.sort方法对list排序有两种方法第一种是list中的对象实现Comparable接口,如下: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ...
- 简单选择排序 Selection Sort 和树形选择排序 Tree Selection Sort
选择排序 Selection Sort 选择排序的基本思想是:每一趟在剩余未排序的若干记录中选取关键字最小的(也可以是最大的,本文中均考虑排升序)记录作为有序序列中下一个记录. 如第i趟选择排序就是在 ...
- java中Collections.sort()方法实现集合排序
1.Integer/String泛型的List进行排序 List <Integer> integerlist = new ArrayList<Integer>(); //定 ...
- 【Python】 sort、sorted高级排序技巧
文章转载自:脚本之家 这篇文章主要介绍了python sort.sorted高级排序技巧,本文讲解了基础排序.升序和降序.排序的稳定性和复杂排序.cmp函数排序法等内容,需要的朋友可以参考下 Pyth ...
- python sort、sorted高级排序技巧
文章转载自:脚本之家 Python list内置sort()方法用来排序,也可以用python内置的全局sorted()方法来对可迭代的序列排序生成新的序列. 1)排序基础 简单的升序排序是非常容易的 ...
随机推荐
- 使用git 版本控制的代码在线修调试,如何还原
在线调试: 先切换成www用户进入项目的根目录比如/data/wwwroot/website su www cd /data/wwwroot/website vi ./api/controllers/ ...
- 《罗辑思维》试读:U盘化生存
<罗辑思维>试读:U盘化生存 何为"U盘" 记得有一次我到一个大学去讲课,我随机做了一个调查.我说大四啦,咱们班同学谁找着工作了,一堆人举手.我又问都加入什么样的组织了 ...
- 实验一 HTML基本标签及文本处理
实验一 HTML基本标签及文本处理 [实验目的] 1.掌握利用因特网进行信息游览.搜索,下载网页.图片.文字和文件: 2.对给定的网站,能指出网站的链接结构.目录结构.页面布局方式: 3.掌握HTML ...
- 2014年 实验五 Internet与网络工具的使用
实验五 Internet与网络工具的使用 [实验目的] ⑴.FTP服务器的架设和客户端的使用. ⑵.使用云盘和云笔记应用 ⑶.运用QQ的远程协助功能. (4).默认安装foxmail软件,进行邮件 ...
- 【数论】HAOI2012 容易题
题目大意 洛谷链接 有一个数列A已知对于所有的\(A[i]\)都是\(1~n\)的自然数,并且知道对于一些\(A[i]\)不能取哪些值,我们定义一个数列的积为该数列所有元素的乘积,要求你求出所有可能的 ...
- Spring 事件监听
Spring 的核心是 ApplicationContext,它负责管理 Bean的完整生命周期:当加载 Bean 时,ApplicationContext 发布某些类型的事件:例如,当上下文启动时, ...
- python自测100题
如果你在寻找python工作,那你的面试可能会涉及Python相关的问题. 通过对网络资料的收集整理,本文列出了100道python的面试题以及答案,你可以根据需求阅读测试.如果你看了还是不懂可以加我 ...
- 由反转链表想到python链式交换变量
这两天在刷题,看到链表的反转,在翻解体思路时看到有位同学写出循环中一句搞定三个变量的交换时觉得挺6的,一般用的时候都是两个变量交换(a,b=b,a),这种三个变量的交换还真不敢随便用,而且这三个变量都 ...
- 使用WxPusher给自己的个人微信发送提醒消息(WxPusher微信推送服务)
1.背景 我们很多时候,我们在服务器上运行软件,发生一些业务异常,需要给我们发送一个及时的提醒,或者是使用一些耗时软件,比如抢车票,抢课,刷优惠券当任务运行成功以后,也需要及时的发送消息给自己 ,告诉 ...
- 通过代码实现 `OutOfMemory
通过代码实现 OutOfMemory Intro 来尝试写一个发生 OutOfMemoryException 的代码吧,开启煞笔代码第三篇 -- OutofMemory OutOfMemory Out ...