python-网络安全编程第十天(web目录扫描&&fake_useragent模块&&optionParser模块)
前言


昨天的内容没有完成今天花了点时间继续完成了 感觉自己的学习效率太低了!想办法提高学习效率吧 嗯 ,再制定下今天的目标 开始健身。
python fake_useragent模块
1.UserAgent
userAgent 属性是一个只读的字符串,声明了浏览器用于 HTTP 请求的用户代理头的值。
2. fake_useragent
fake_useragent是一个集成了市面上大部分的user-agent,可以指定浏览器,也可随机生成任意一个
在工作中进行爬虫时,经常会需要提供User-Agent,如果不提供User-Agent,会导致爬虫在请求网页时,请求失败,所以需要大量User-Agent。如何生成合法的User-Agent?
使用fake-useragent库就可以解决该问题。
3.fake_useragent简单使用
示例代码1:
简单打印出几个user-agent
from fake_useragent import UserAgent
ua=UserAgent() #实例化 print(ua.ie) #随机打印一个ie浏览器的User-Agent
print(ua.random)#随机打印一个User-Agent
输出结果:

示例代码2:
将useragent带入到header请求头里面进行http请求
from fake_useragent import UserAgent
import requests
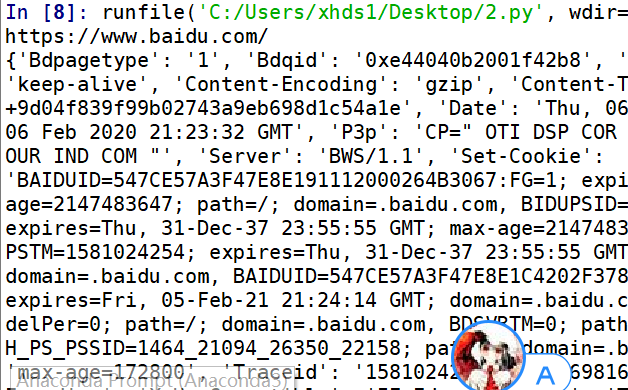
ua=UserAgent() #实例化 url="http://baidu.com"
ua=str(ua.random)
headers={'User-Agent':ua} r=requests.get(url=url,headers=headers)
print(r.url)
print(r.headers)
请求结果:
Python-optionParser模块
代码:
from optparse import OptionParser
parser=OptionParser() #dest是存储变量的 default是缺省值 help是帮助提示
#使用add_option()加入选项
parser.add_option("-u","--url",dest="url",help='target url for scan')
parser.add_option("-f","--file",dest="ext",help="target url ext")
parser.add_option("-t","--thread",dest="count",default=10,help="scan thread_count")
#最后通过parse_args()函数的解析
(options,args)=parser.parse_args() #当option.url 和option.ext里面的值都为真是则继续执行里面的函数
if options.url and options.ext:
print(options.url)
print(options.ext)
print(options.count)
else:
parser.print_help()
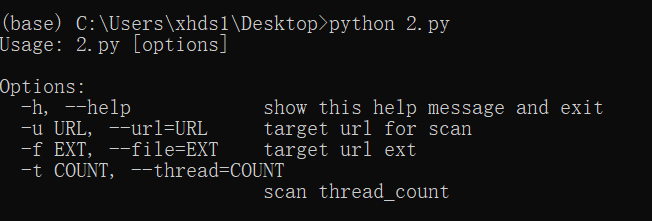
正常使用我们在cmd命令界面调用一一输入我们的值即可正常运行

如果没有输入值则会打印出我们定义的help里面的信息
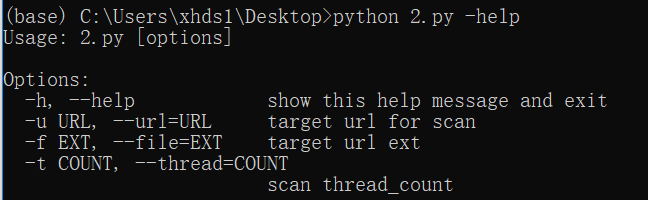
输入-help参数也会打印help信息
参考学习:https://blog.csdn.net/lwnylslwnyls/article/details/8199454
web目录扫描器
代码:
import requests
import queue
import sys
import threading
#from agent_proxy import USER_AGENT_LIST
from fake_useragent import UserAgent
queue=queue.Queue()
from optparse import OptionParser
import sys class DirScan(threading.Thread):
def __init__(self,queue):
threading.Thread.__init__(self)
self._queue=queue def run(self):
while not self._queue.empty():
url=self._queue.get() try: ua=UserAgent()
ua1=str(ua.random) headers={'User-Agent':ua1}
r=requests.get(url=url,headers=headers,timeout=8) if r.status_code==200:
print(r.url)
#sys.stdout.write('\r'+'[*]%s\t\t'%(url))
f=open('result.html','a+')
f.write('<a href="'+url+'" target="_blank">'+url+'</a>')
f.write('\r\n<br>')
f.close except Exception as e:
pass def start(url,ext,count): f=open('result.html','w')
f.close() f=open('./dics/%s.txt'%ext,'r') for i in f:
queue.put(url+i.rstrip('\n')) #
threads=[]
thread_count=int(count)
#
for i in range(thread_count):
threads.append(DirScan(queue))
for t in threads:
t.start()
for t in threads:
t.join()
##
#
#start("http://www.dokocom.com",'asp','10'); if __name__=='__main__':
print("=====================================\n榆林学院信息安全协会开发V1.0\n超级高速web目录敏感扫描器\n=====================================\n") parser=OptionParser()
# parser=OptionParser()
parser.add_option("-u","--url",dest="url",help='target url for scan')
parser.add_option("-f","--file",dest="ext",help="target url ext")
parser.add_option("-t","--thread",dest="count",default=10,help="scan thread_count")
(options,args)=parser.parse_args() if options.url and options.ext:
start(options.url,options.ext,options.count);
sys.exit(1)
else:
parser.print_help()
sys.exit(1)
#
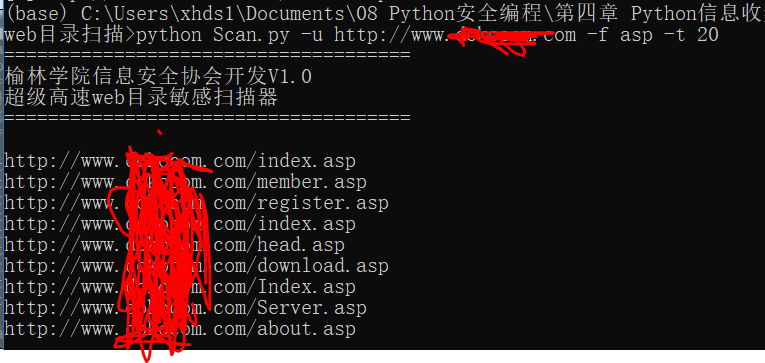
使用方法:
使用方法:python Scan.py http:xxx.com -f asp -t 20
-f: 脚本类型
-t :线程数
如果输入有误提示使用方式:

会在程序当前目录下生成result.html文件 打开就是扫描的结果
python-网络安全编程第十天(web目录扫描&&fake_useragent模块&&optionParser模块)的更多相关文章
- 十大web安全扫描工具
本文来源:绿盟整理 <十大web安全扫描工具> 十大web安全扫描工具 扫描程序可以在帮助造我们造就安全的Web 站点上助一臂之力,也就是说在黑客"黑"你之前, 先测 ...
- Python核心编程第二版(中文).pdf 目录整理
python核心编程目录 Chapter1:欢迎来到python世界!-页码:7 1.1什么是python 1.2起源 :罗萨姆1989底创建python 1.3特点 1.3.1高级 1.3.2面向 ...
- 拒绝从入门到放弃_《Python 核心编程 (第二版)》必读目录
目录 目录 关于这本书 必看知识点 最后 关于这本书 <Python 核心编程 (第二版)>是一本 Python 编程的入门书,分为 Python 核心(其实并不核心,应该叫基础) 和 高 ...
- python网络编程(六)---web客户端访问
1.获取web页面 urllib2 支持任何协议的工作---不仅仅是http,还包括FTP,Gopher. import urllib2 req=urllib2.Request('http://www ...
- python网络编程(十)
select版-TCP服务器 1. select 原理 在多路复用的模型中,比较常用的有select模型和epoll模型.这两个都是系统接口,由操作系统提供.当然,Python的select模块进行了 ...
- python系统编程(十二)
异步 同步调用就是你 喊 你朋友吃饭 ,你朋友在忙 ,你就一直在那等,等你朋友忙完了 ,你们一起去 异步调用就是你 喊 你朋友吃饭 ,你朋友说知道了 ,待会忙完去找你 ,你就去做别的了. from m ...
- python系统编程(十)
多线程-非共享数据 对于全局变量,在多线程中要格外小心,否则容易造成数据错乱的情况发生 1. 非全局变量是否要加锁呢? #coding=utf-8 import threading import ti ...
- python网络编程(十二)
协程 协程,又称微线程,纤程.英文名Coroutine. 协程是啥 首先我们得知道协程是啥?协程其实可以认为是比线程更小的执行单元. 为啥说他是一个执行单元,因为他自带CPU上下文.这样只要在合适的时 ...
- python核心编程学习记录之Web编程
cgi未完待续
随机推荐
- Web调优之IBM JDK+liberty(一): Jmeter pod里压力,50个线程并发测试,调整 -Xms -Xms, Log原来是大问题
1.运行环境 k8s Web服务器: Liberty(IBM J9 JDK),base image : FROM websphere-liberty:20.0.0.3-kernel-java8-ibm ...
- 【应用程序见解 Application Insights】使用Azure Monitor Application Insights Agent获取Azure VM中监控数据及IIS请求指标等信息
问题情形 为了使用Application Insights也可以监控Azure VM中的相关性能数据,如CPU, Memory,IIS Reuqest等信息,可以在VM中开始一个一个扩展插件: Azu ...
- linux 环境搭建Jenkins
这里提供一个本地搭建Jenkins的方法,基于wins 的 https://blog.csdn.net/u011541946/article/month/2017/09/2 下面讲的是在服务器上操 ...
- C# 向服务器发送信息
#region 向服务器发送信息 /// <summary> /// 向服务器发送信息 /// </summary> /// <param name="post ...
- 【git冲突解决】: Please commit your changes or stash them before you merge.
刚刚使用 git pull 命令拉取代码时候,遇到了这样的问题: error: Your local changes to the following files would be overwritt ...
- VirtualXposed结合justTrustMe 模块傻瓜式破解app没法抓包问题
一.首先就是按照这两个apk 声明仅供学习 justTrustMe 链接:https://pan.baidu.com/s/1av3oaez4y4n6a9C1I0VsAg 提取码:mjqg Virtua ...
- java面试题:多线程交替输出偶数和奇数
一个面试题:实现两个线程A,B交替输出偶数和奇数 问题:创建两个线程A和B,让他们交替打印0到100的所有整数,其中A线程打印偶数,B线程打印奇数 这个问题配合java的多线程,很多种实现方式 在具体 ...
- 第三章 MySQL的多实例
一.MySQL服务构成 1.MySQL程序结构 1.连接层 2.sql层 3.存储引擎层 2.MySQL逻辑结构 1.库 2.表:元数据+真实数据行 3.元数据:列+其它属性(行数+占用空间大小+权限 ...
- 微信小程序picker组件两列关联使用方式
在使用微信小程序picker组件时候,可以设置属性 mode = multiSelector 意为多列选择,关联选择,当第一列发生改变时侯,第二列甚至第三列发生相应的改变.但是官方文档上给的只 ...
- AWS Lambda 借助 Serverless Framework,迅速起飞
前言 微服务架构有别于传统的单体式应用方案,我们可将单体应用拆分成多个核心功能.每个功能都被称为一项服务,可以单独构建和部署,这意味着各项服务在工作时不会互相影响 这种设计理念被进一步应用,就变成了无 ...