MySQL中concat()、concat_ws()、group_concat()函数的使用技巧与心得总结
Author:极客小俊 一个专注于web技术的80后
我不用拼过聪明人,我只需要拼过那些懒人 我就一定会超越大部分人!
CSDN@极客小俊,原创文章, B站技术分享
B站视频 : Bilibili.com
个人博客: cnblogs.com
前言
GROUP_CONCAT()函数在MySQL到底起什么作用呢 ?
有些小伙伴还觉得它很神秘其实不然,今天就来讲讲这个函数的实际操作以及相关案例、
我将从concat()函数 --- concat_ws()函数----到最后的group_concat()函数逐一讲解! 让小伙伴摸清楚其使用方法 !
首先我们来建立一个测试的表和数据,代码如下
CREATE TABLE `per` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`pname` varchar(50) DEFAULT NULL,
`page` int(11) DEFAULT NULL,
`psex` varchar(50) DEFAULT NULL,
`paddr` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4;
INSERT INTO `per` VALUES ('1', '王小华', '30', '男', '北京');
INSERT INTO `per` VALUES ('2', '张文军', '24', '男', '上海');
INSERT INTO `per` VALUES ('3', '罗敏', '19', '女', '重庆');
INSERT INTO `per` VALUES ('4', '张建新', '32', '男', '重庆');
INSERT INTO `per` VALUES ('5', '刘婷', '26', '女', '成都');
INSERT INTO `per` VALUES ('6', '刘小亚', '22', '女', '重庆');
INSERT INTO `per` VALUES ('7', '王建军', '22', '男', '贵州');
INSERT INTO `per` VALUES ('8', '谢涛', '28', '男', '海南');
INSERT INTO `per` VALUES ('9', '张良', '26', '男', '上海');
INSERT INTO `per` VALUES ('10', '黎记', '17', '男', '贵阳');
INSERT INTO `per` VALUES ('11', '赵小丽', '26', '女', '上海');
INSERT INTO `per` VALUES ('12', '张三', null, '女', '北京');
concat()函数
首先我们先学一个函数叫concat()函数, 这个函数非常简单
功能:就是将多个字符串连接成一个字符串
语法:concat(字符串1, 字符串2,...) 字符串参数用逗号隔开!
返回值: 结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
案例1
select concat('重庆','北京','上海');
效果如下图: 是不是觉得很简单 很直观呢!

案例2
这有一张表
+----+-----------+------+------+--------+
| id | pname | page | psex | paddr |
+----+-----------+------+------+--------+
| 1 | 王小华 | 30 | 男 | 北京 |
| 2 | 张文军 | 24 | 男 | 上海 |
| 3 | 罗敏 | 19 | 女 | 重庆 |
| 4 | 张建新 | 32 | 男 | 重庆 |
| 5 | 刘婷 | 26 | 女 | 成都 |
| 6 | 刘小亚 | 22 | 女 | 重庆 |
| 7 | 王建军 | 22 | 男 | 贵州 |
| 8 | 谢涛 | 28 | 男 | 海南 |
| 9 | 张良 | 26 | 男 | 上海 |
| 10 | 黎记 | 17 | 男 | 贵阳 |
| 11 | 赵小丽 | 26 | 女 | 上海 |
| 12 | 张三 | NULL | 女 | 北京 |
+----+-----------+------+------+--------+
#-- 执行如下语句
select concat(pname,page,psex) from per;
#--结果
+-------------------------+
| concat(pname,page,psex) |
+-------------------------+
| 王小华30男 |
| 张文军24男 |
| 罗敏19女 |
| 张建新32男 |
| 刘婷26女 |
| 刘小亚22女 |
| 王建军22男 |
| 谢涛28男 |
| 张良26男 |
| 黎记17男 |
| 赵小丽26女 |
| NULL |
+-------------------------+
#--为什么会有一条是NULL呢?
#--那是因为第12条数据中的page字段为空,根据有一个字段为空结果就为NULL的理论推导出 查询出的最后一条记录为NULL!
但是大家一定会发现虽然连在一起显示了 但是彼此没有分隔符啊 看起来好难受 对不对? 所以接下来我们就来讲讲衍生出来的 concat_ws()函数
concat_ws()函数
功能:concat_ws()函数 和 concat()函数一样,也是将多个字符串连接成一个字符串,但是可以指定分隔符!
语法:concat_ws(separator, str1, str2, ...) 第一个参数指定分隔符, 后面依旧是字符串
separator就是分隔符字符!
需要注意的是分隔符不能为null,如果为null,则返回结果为null。
案例代码:
select concat_ws(',',pname,page,psex) from per;
#--以逗号分割 结果如下
+--------------------------------+
| concat_ws(',',pname,page,psex) |
+--------------------------------+
| 王小华,30,男 |
| 张文军,24,男 |
| 罗敏,19,女 |
| 张建新,32,男 |
| 刘婷,26,女 |
| 刘小亚,22,女 |
| 王建军,22,男 |
| 谢涛,28,男 |
| 张良,26,男 |
| 黎记,17,男 |
| 赵小丽,26,女 |
| 张三,女 |
+--------------------------------+
#--把分隔符指定为null,结果全部变成了null
select concat_ws(null,pname,page,psex) from per; #--错误的
+---------------------------------+
| concat_ws(null,pname,page,psex) |
+---------------------------------+
| NULL |
| NULL |
| NULL |
| NULL |
| NULL |
| NULL |
| NULL |
| NULL |
| NULL |
| NULL |
| NULL |
| NULL |
+---------------------------------+
group_concat()函数
接下来就要进入我们本文的主题了,group_concat()函数, 理解了上面两个函数的作用和用法 就对理解group_concat()函数有很大帮助了!
功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
注意: 中括号是可选的
分析: 通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
以下我准备了几个案例 小伙伴们可以选择性的去阅读 并且把代码复制到MySQL中执行以下就可以知道用法了!
重点注意
- group_concat只有与group by语句同时使用才能产生效果 所以使用 GROUP_CONCAT()函数必须对源数据进行分组,否则所有数据会被合并成一行
- 需要将拼接的结果去重的话,可与DISTINCT结合使用即可
案例1
需求: 比如我们要查在重庆的有哪些人? 并且把这些人的名字用 '-' 字符分隔开 然后显示出来, SQL语句如下
#--这里就用到了 : 取出重复、显示排序、 定义分隔字符
select
paddr,
group_concat(distinct pname order by pname desc separator '-') as '人'
from per
group by paddr;
#--结果为:
+--------+----------------------------+
| paddr | 人 |
+--------+----------------------------+
| 上海 | 赵小丽-张良-张文军 |
| 北京 | 王小华-张三 |
| 成都 | 刘婷 |
| 海南 | 谢涛 |
| 贵州 | 王建军 |
| 贵阳 | 黎记 |
| 重庆 | 罗敏-张建新-刘小亚 |
+--------+----------------------------+
#--有多个的自然会被用字符分隔连接起来,只有一个人的就没有什么变化!直接显示
案例2
需求: 比如我们要查在重庆的有哪些人? 并且把这些人的名字用逗号隔开,
以上需求跟上面的案例1 差不多 我们就加一个效果, 也就是显示出来的名字前面把id号 也加上
#--显示出来每一个名字所对应的id号 这里我们结合了group_concat()函数 和 concat_ws()函数,
select
paddr,
group_concat(concat_ws('-',id,pname) order by id asc) as '人'
from per
group by paddr;
#--显示结果
+--------+-----------------------------------+
| paddr | 人 |
+--------+-----------------------------------+
| 上海 | 2-张文军,9-张良,11-赵小丽 |
| 北京 | 1-王小华,12-张三 |
| 成都 | 5-刘婷 |
| 海南 | 8-谢涛 |
| 贵州 | 7-王建军 |
| 贵阳 | 10-黎记 |
| 重庆 | 3-罗敏,4-张建新,6-刘小亚 |
+--------+-----------------------------------+
注意:
- MySQL中函数是可以嵌套使用的
- 一般使用group_concat()函数,必须是存在group by 分组的情况下 才能使用这个函数
案例3
我们再来看一个案例, 首先我们准备以下测试数据
准备一个student学生表、MySQL代码如下
#-- student
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT, #--id
`stuName` varchar(22) DEFAULT NULL, #--学生姓名
`course` varchar(22) DEFAULT NULL, #--学习科目
`score` int(11) DEFAULT NULL, #--学分
PRIMARY KEY (`id`) #--设置主键
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8; #--设置表引擎 自动递增起始值 默认编码格式
-- ----------------------------
-- 插入以下数据
-- ----------------------------
INSERT INTO `student`(stuName,course,score) VALUES ('张三', '语文', '91');
INSERT INTO `student`(stuName,course,score) VALUES ('张三', '数学', '90');
INSERT INTO `student`(stuName,course,score) VALUES ('张三', '英语', '87');
INSERT INTO `student`(stuName,course,score) VALUES ('李四', '语文', '79');
INSERT INTO `student`(stuName,course,score) VALUES ('李四', '数学', '95');
INSERT INTO `student`(stuName,course,score) VALUES ('李四', '英语', '80');
INSERT INTO `student`(stuName,course,score) VALUES ('王五', '语文', '77');
INSERT INTO `student`(stuName,course,score) VALUES ('王五', '数学', '81');
INSERT INTO `student`(stuName,course,score) VALUES ('王五', '英语', '89');
#--建立好之后 数据如下显示:
mysql> select * from student;
+----+---------+--------+-------+
| id | stuName | course | score |
+----+---------+--------+-------+
| 10 | 张三 | 语文 | 91 |
| 11 | 张三 | 数学 | 90 |
| 12 | 张三 | 英语 | 87 |
| 13 | 李四 | 语文 | 79 |
| 14 | 李四 | 数学 | 95 |
| 15 | 李四 | 英语 | 80 |
| 16 | 王五 | 语文 | 77 |
| 17 | 王五 | 数学 | 81 |
| 18 | 王五 | 英语 | 89 |
+----+---------+--------+-------+
建立好表和数据之后 我们就来继续使用group_concat()函数 加深以下印象!
需求1: 以stuName学生名称分组,把得分数score字段的值打印在一行,逗号分隔(默认) SQL如下
select stuName, GROUP_CONCAT(score) as '当前这个学生的得分数' from student GROUP BY stuName;
#--运行结果如下
mysql> select stuName, GROUP_CONCAT(score) as '当前这个学生的得分数' from student GROUP BY stuName;
+---------+--------------------------------+
| stuName | 当前这个学生的得分数 |
+---------+--------------------------------+
| 张三 | 91,90,87 |
| 李四 | 79,95,80 |
| 王五 | 77,81,89 |
+---------+--------------------------------+
需求2: 那么根据上面的结果 我们看到分数是出来了 但是不知道是什么科目分数 那么我们还要把科目也连起来显示,并且分数还是从小到大,我们应该怎么做呢 ? 其实很简单的啦 SQL如下
select stuName, GROUP_CONCAT(concat_ws('=',course,score) order by score asc) as '当前这个学生的得分数' from student GROUP BY stuName;
#--执行结果如下
+---------+--------------------------------+
| stuName | 当前这个学生的得分数 |
+---------+--------------------------------+
| 张三 | 英语=87,数学=90,语文=91 |
| 李四 | 语文=79,英语=80,数学=95 |
| 王五 | 语文=77,数学=81,英语=89 |
+---------+--------------------------------+
#-- 这样显示是不是觉得更加清楚了呢!
需求3: 这里再给小伙伴深入一个问题 那么我们现在要查询出 语文、数学、外语 三门课的最低分,还有哪个学生考的? 现在应该怎么写呢?
[方法1]
#--首先我们可以把这个问题拆分成两个部分
#--1.就是找出语文、数学、外语 三门课的最低分 这一步还是比较简单的我们可以使用分组查询就可以解决
#--分析问题后得出SQL方案 按照科目进行分组查询 然后使用聚合函数筛选出最小的得分数, 显示对应科目字段 这样就得出了三门课的最低分
SELECT min(score),course FROM student GROUP BY course;
#--那么查询出的结果如下
+------------+--------+
| min(score) | course |
+------------+--------+
| 81 | 数学 |
| 80 | 英语 |
| 77 | 语文 |
+------------+--------+
#--那么接下来我们要考虑的是如何找到是哪个学生考的!?
#--这里我们可以使用in() 的包含+ 子查询的方式来 根据上面SQL的结果 来进行匹配包含查询 学生名
SELECT stuName,score,course from student where (score,course) in(SELECT min(score),course FROM student GROUP BY course);
#--结果如下
+---------+-------+--------+
| stuName | score | course |
+---------+-------+--------+
| 李四 | 80 | 英语 |
| 王五 | 77 | 语文 |
| 王五 | 81 | 数学 |
+---------+-------+--------+
问题分析
- 这里的重点就在于子查询的使用 上面已经用一句SQL查询出了 三门课的最低分和科目 那么我们就可以列用这个结果集来 当做另外一句SQL所要查询条件 !
- where 后面跟的是一个圆括号 里面写的是 分数和科目两个字段,用来匹配in() 里面的子查询结果 可能这里有些新手小伙伴并没有见过这样写 现在应该清楚了
[方法2]
#--我们也可以用以下SQL语句来实现 ,性能上比上面好一点点!
SELECT g.`id`,g.`course`,g.`score`,g.`stuName`FROM (SELECT course, SUBSTRING_INDEX(GROUP_CONCAT(score ORDER BY score ASC), ',',1) AS score FROM student GROUP BY course) AS t LEFT JOIN student AS g ON (t.course = g.`course` AND t.score = g.`score`)
#--小提示:SUBSTRING_INDEX() 函数是提取的连接字符中的第一个
#--简单的说 先连接好分数字段中的得分默认用逗号 再从分数连接字符中提取第一个出来,
#--首先我们要得到每一个科目中最小的分数 我们可以分析出如下SQL,
#--这里的分组条件还是以科目进行分组, 分组之后还是GROUP_CONCAT()函数用逗号连接起相对应的所有分数,然后用SUBSTRING_INDEX()函数提取连接字符中的第一个字符作为结果
SELECT course,SUBSTRING_INDEX(GROUP_CONCAT(score ORDER BY score ASC),',',1) AS score FROM student GROUP BY course;
#--结果如下
+--------+-------+
| course | score |
+--------+-------+
| 数学 | 81 |
| 英语 | 80 |
| 语文 | 77 |
+--------+-------+
#--我们可以把这个结果 想象成一张虚拟表取一个别名 t, 现在t这个是一个临时的表,我们要查询id,科目,分数,姓名, 就在前面加上需要的字段,注意别名
#--然后再使用左连接筛选出 对应的结果
SELECT g.`id`,g.`course`,g.`score`,g.`stuName`FROM
(SELECT course,SUBSTRING_INDEX(GROUP_CONCAT(score ORDER BY score ASC),',',1) AS score FROM student GROUP BY course) as t
LEFT JOIN student AS g ON (t.course = g.`course` AND t.score = g.`score`) #--left join 来显示出符合条件的结果 也就是用上面查询出来的结果来对应条件
#--结果如下
+------+--------+-------+---------+
| id | course | score | stuName |
+------+--------+-------+---------+
| 15 | 英语 | 80 | 李四 |
| 16 | 语文 | 77 | 王五 |
| 17 | 数学 | 81 | 王五 |
+------+--------+-------+---------+
案例4
我们来简单的准备一个商品表吧 , 代码如下
#-- goods
CREATE TABLE `goods` (
`id` int(11) NOT NULL AUTO_INCREMENT, #--id
`price` varchar(22) DEFAULT NULL, #--商品价格
`goods_name` varchar(22) DEFAULT NULL, #--商品名称
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; #--设置表引擎 自动递增起始值 默认编码格式
-- ----------------------------
-- 插入以下数据
-- ----------------------------
INSERT INTO `goods`(price,goods_name) VALUES (10.00, '皮包');
INSERT INTO `goods`(price,goods_name) VALUES (20.00, '围巾');
INSERT INTO `goods`(price,goods_name) VALUES (30.00, '围巾');
INSERT INTO `goods`(price,goods_name) VALUES (40.00, '游戏机');
INSERT INTO `goods`(price,goods_name) VALUES (60.00, '皮包');
INSERT INTO `goods`(price,goods_name) VALUES (80.00, '游戏机');
INSERT INTO `goods`(price,goods_name) VALUES (220.00, '游戏机');
INSERT INTO `goods`(price,goods_name) VALUES (780.00, '围巾');
INSERT INTO `goods`(price,goods_name) VALUES (560.00, '游戏机');
INSERT INTO `goods`(price,goods_name) VALUES (30.00, '皮包');
需求1: 以 商品名称分组,把price字段的值在一行打印出来,分号分隔
select goods_name,group_concat(price) from goods group by goods_name;
需求2: 以 商品名称分组,把price字段的值在一行打印出来,分号分隔 并且去除重复冗余的价格字段的值
select goods_name,group_concat(distinct price) from goods group by goods_name;
需求3: 以 商品名称分组,把price字段的值在一行打印出来,分号分隔 去除重复冗余的价格字段的值 并且排序 从小到大
select goods_name,group_concat(distinct price order by price desc) from goods group by goods_name; #--错误的
select goods_name,group_concat(distinct price order by price+1 desc) from goods group by goods_name; #--正确的
#--注意以上存在隐式数据类型转换 如果不这样转换排序出来的结果是错误的 , 因为我保存price价格的字段是varchar类型的
案例5
我们再结合group_concat()函数来做一个多表查询的案例
准备 三张 测试数据表: 用户表[user]、水果表[fruit]、用户喜欢哪些水果的表[user_like]
首先 建立用户表[user] SQL语句代码如下
#-- user
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT, #--id
`username` varchar(22) DEFAULT NULL, #--用户名
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; #--设置表引擎 自动递增起始值 默认编码格式
#--插入测试数据
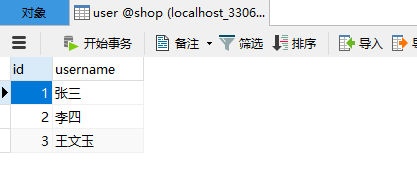
INSERT INTO `user`(username) VALUES ('张三');
INSERT INTO `user`(username) VALUES ('李四');
INSERT INTO `user`(username) VALUES ('王文玉');
建立水果表[fruit] SQL语句代码如下
#-- fruit
CREATE TABLE `fruit` (
`id` int(11) NOT NULL AUTO_INCREMENT, #--id
`fruitname` varchar(22) DEFAULT NULL, #--水果名称
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; #--设置表引擎 自动递增起始值 默认编码格式
#--插入测试数据
INSERT INTO `fruit`(fruitname) VALUES ('西瓜');
INSERT INTO `fruit`(fruitname) VALUES ('苹果');
INSERT INTO `fruit`(fruitname) VALUES ('芒果');
INSERT INTO `fruit`(fruitname) VALUES ('梨');
INSERT INTO `fruit`(fruitname) VALUES ('葡萄');

建立 用户喜爱表 [user_like]
但是建立这个表的时候 跟前面两个表有所不同,小伙们们首先要搞清楚 这个表是一个什么用来干啥的表
分析清楚这个表的关系, 因为是用户喜欢哪些水果的表 那么 一个水果可以被多个用户所喜欢对吧? 反过来说一个用户也可以喜欢多个水果吧 对吧 那么这里是一个什么关系呢 ?? 很明显是一个 多对多的关系!
所以建立这个表 我们就可以使用 用户的id 来对应 水果的id 就可以实现一个中间连接多对多的表了
SQL语句代码如下:
#-- fruit
CREATE TABLE `user_like` (
`id` int(11) NOT NULL AUTO_INCREMENT, #--id
`user_id` int, #--用户的id号
`fruit_id` int, #--水果的id号
CONSTRAINT user_like PRIMARY KEY (id,user_id,fruit_id) #--定义联合主键 让每一条记录唯一
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; #--设置表引擎 自动递增起始值 默认编码格式
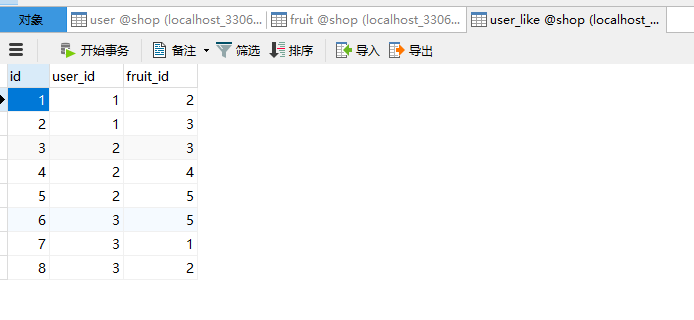
#--测试数据
INSERT INTO `user_like`(user_id,fruit_id) VALUES (1,1); #--这就代表用户表中id号为1的用户 喜欢fruit表中id号为1的水果
INSERT INTO `user_like`(user_id,fruit_id) VALUES (1,2); #--这就代表用户表中id号为1的用户 喜欢fruit表中id号为2的水果
INSERT INTO `user_like`(user_id,fruit_id) VALUES (1,3); #--这就代表用户表中id号为1的用户 喜欢fruit表中id号为3的水果
INSERT INTO `user_like`(user_id,fruit_id) VALUES (2,3); #--这就代表用户表中id号为2的用户 喜欢fruit表中id号为3的水果
INSERT INTO `user_like`(user_id,fruit_id) VALUES (2,4); #--这就代表用户表中id号为2的用户 喜欢fruit表中id号为4的水果
INSERT INTO `user_like`(user_id,fruit_id) VALUES (2,5); #--这就代表用户表中id号为2的用户 喜欢fruit表中id号为5的水果
INSERT INTO `user_like`(user_id,fruit_id) VALUES (3,5); #--这就代表用户表中id号为3的用户 喜欢fruit表中id号为5的水果
INSERT INTO `user_like`(user_id,fruit_id) VALUES (3,1); #--这就代表用户表中id号为3的用户 喜欢fruit表中id号为1的水果
INSERT INTO `user_like`(user_id,fruit_id) VALUES (3,2); #--这就代表用户表中id号为3的用户 喜欢fruit表中id号为2的水果
#-- 以此类推...
好了 现在数据 和 表我们都已经准备好了 , 那么 接下来 我们就要开始进行 GROUP_CONCAT()函数的使用了
需求: 查出每个用户喜欢的水果都有哪些!
#--查询SQL如下
select u.username,group_concat(f.fruitname) from user_like as c inner join user as u on c.user_id=u.id inner join fruit as f on c.fruit_id=f.id group by c.user_id;
#--结果如下
+-----------+---------------------------+
| username | group_concat(f.fruitname) |
+-----------+---------------------------+
| 张三 | 芒果,苹果 |
| 李四 | 梨,芒果,葡萄 |
| 王文玉 | 西瓜,葡萄,苹果 |
+-----------+---------------------------+


"点赞" "评论" "收藏"
大家的支持就是我坚持下去的动力!
如果以上内容有任何错误或者不准确的地方,欢迎在下面 留个言指出、或者你有更好的想法,欢迎一起交流学习
MySQL中concat()、concat_ws()、group_concat()函数的使用技巧与心得总结的更多相关文章
- MySQL中的字段拼接 concat() concat_ws() group_concat()函数
1.concat()函数 2.concat_ws()函数 3.group_concat()函数 操作的table select * from test_concat order by id limit ...
- 浅析MySQL中concat以及group_concat的使用
说明: 本文中使用的例子均在下面的数据库表tt2下执行: 一.concat()函数 1.功能:将多个字符串连接成一个字符串. 2.语法:concat(str1, str2,...) 返回结果为连接 ...
- mysql中concat 和 group_concat()的用法
一.CONCAT()函数CONCAT()函数用于将多个字符串连接成一个字符串.使用数据表Info作为示例,其中SELECT id,name FROM info LIMIT 1;的返回结果为+----+ ...
- MySQL中concat以及group_concat的使用
摘自:https://www.jianshu.com/p/43cb4c5d33c1 说明: 本文中使用的例子均在下面的数据库表tt2下执行: 一.concat()函数 1.功能:将多个字符串连接成一个 ...
- mysql之concat concat_ws group_concat
concat.concat_ws.group_concat都可以用来连接字符串. concat和concat_ws用来连接同一行中不同列的数据,group_ws用来连接同一列的数据. 格式如下: co ...
- mysql中的concat,concat_ws(),group_concat()
mysql中的concat,concat_ws(),group_concat() 说明: 本文中使用的例子均在下面的数据库表tt2下执行: 一.concat()函数 1.功能:将多个字符串连接 ...
- MySQL中concat函数(连接字符串)
MySQL中concat函数使用方法:CONCAT(str1,str2,…) 返回结果为连接参数产生的字符串.如有任何一个参数为NULL ,则返回值为 NULL. 注意:如果所有参数均为非二进制字符串 ...
- MySQL中concat函数
MySQL中concat函数使用方法:CONCAT(str1,str2,…) 返回结果为连接参数产生的字符串.如有任何一个参数为NULL ,则返回值为 NULL. 注意:如果所有参数均为非二进制字符串 ...
- 详解MySQL中concat函数的用法(连接字符串)
MySQL中concat函数 使用方法: CONCAT(str1,str2,…) 返回结果为连接参数产生的字符串.如有任何一个参数为NULL ,则返回值为 NULL. 注意: 如果所有参数均为非二进制 ...
随机推荐
- 如何使用python移除/删除非空文件夹?
移除/删除非空文件夹/目录的最有效方法是什么? 1.标准库参考:shutil.rmtree. 根据设计,rmtree在包含只读文件的文件夹树上失败.如果要删除文件夹,不管它是否包含只读文件,请使用 i ...
- python自动化测试中的数据驱动unittest+ddt
ddt是一个unittest的插件,用来实现uniitest的数据驱动 本文以python自动化测试中的数据驱动为原则,记录学习ddt的过程 一.数据的传递规则
- 使用grub2引导进入Linux或Window系统
很多人在一通烂搞之后把自己的grub搞崩了(比如我当时手贱删除了boot分区)虽然后来又装了grub,但是进入grub后还是没有引导,只有一个孤零零的命令行界面 这时候应该怎么办呢?首先当然是想进入系 ...
- yield 的使用
yield 在很多高级语言都有,比如:python.scala.JavaScript.Ruby等. 我们实际工作时,很少会用到yield,但是也架不住求职面试的时候,面试官可能会问呀. yield 在 ...
- ClickHouse和他的朋友们(9)MySQL实时复制与实现
本文转自我司大神 BohuTANG的博客 . 很多人看到标题还以为自己走错了夜场,其实没有. ClickHouse 可以挂载为 MySQL 的一个从库 ,先全量再增量的实时同步 MySQL 数据,这个 ...
- Linux两台服务器mysql数据库同步
我们在做web系统部署的时候往往涉及到两台甚至多台数据库的备份,为了数据安全考虑(虽然说到底不过是一堆0 1,但是价值千金啊),所以我们还是乖乖做同步把! 1.准备两台Linux服务器(主.从) 2. ...
- js中使用const声明变量时需要注意
const实际上保证的,并不是变量的值不得改动,而是变量指向的那个内存地址(初始化的内容)不得改动.对于简单类型的数据(数值.字符串.布尔值),值就保存在变量指向的那个内存地址,因此等同于常量. 简单 ...
- ABP VNext实践之搭建可用于生产的IdentityServer4
一.前言 用了半年多的abp vnext,在开发的效果还是非常的好,可以说节省了很多时间,像事件总线.模块化开发.动态API进行远程调用.自动API控制器等等,一整套的规范,让开发人员更方便的集成,提 ...
- 挂载磁盘不成功显示mount: /mnt: wrong fs type, bad option, bad superblock..............
[23:25:32 root@8 ~]#mount /dev/sdb2 /mntmount: /mnt: wrong fs type, bad option, bad superblock on /d ...
- 游戏UI系统设计
1.需要实现的功能 UI界面的管理(窗体加载.窗体显示.窗体隐藏.窗体销毁等) UI分层次(比如弹窗.广播信息需要在上层) UI界面的出场.入场动画 UI界面的显示效果(比如带透明背景.带高斯模糊背景 ...