转:为什么数据库选B-tree或B+tree而不是二叉树作为索引结构
转载至:https://blog.csdn.net/sinat_27602945/article/details/80118362
B-Tree就是我们常说的B树,一定不要读成B减树,否则就很丢人了。B树这种数据结构常常用于实现数据库索引,因为它的查找效率比较高。
磁盘IO与预读
磁盘读取依靠的是机械运动,分为寻道时间、旋转延迟、传输时间三个部分,这三个部分耗时相加就是一次磁盘IO的时间,大概9ms左右。这个成本是访问内存的十万倍左右;正是由于磁盘IO是非常昂贵的操作,所以计算机操作系统对此做了优化:预读;每一次IO时,不仅仅把当前磁盘地址的数据加载到内存,同时也把相邻数据也加载到内存缓冲区中。因为局部预读原理说明:当访问一个地址数据的时候,与其相邻的数据很快也会被访问到。每次磁盘IO读取的数据我们称之为一页(page)。一页的大小与操作系统有关,一般为4k或者8k。这也就意味着读取一页内数据的时候,实际上发生了一次磁盘IO。
B-Tree与二叉查找树的对比
我们知道二叉查找树查询的时间复杂度是O(logN),查找速度最快和比较次数最少,既然性能已经如此优秀,但为什么实现索引是使用B-Tree而不是二叉查找树,关键因素是磁盘IO的次数。
数据库索引是存储在磁盘上,当表中的数据量比较大时,索引的大小也跟着增长,达到几个G甚至更多。当我们利用索引进行查询的时候,不可能把索引全部加载到内存中,只能逐一加载每个磁盘页,这里的磁盘页就对应索引树的节点。
一、 二叉树
我们先来看二叉树查找时磁盘IO的次:定义一个树高为4的二叉树,查找值为10:
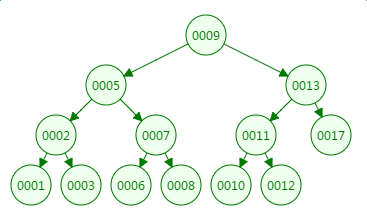
第一次磁盘IO:
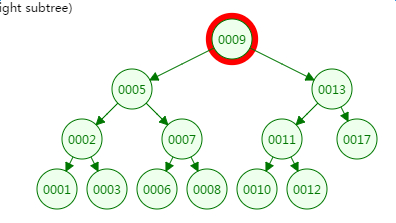
第二次磁盘IO

第三次磁盘IO
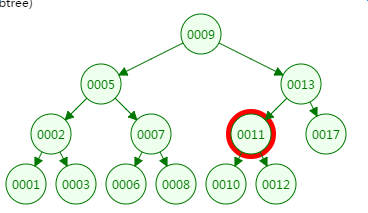
第四次磁盘IO:
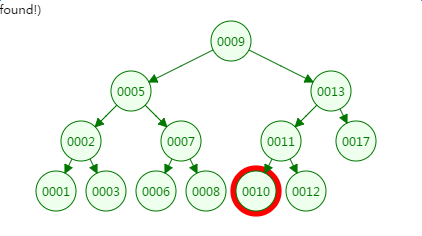
从二叉树的查找过程了来看,树的高度和磁盘IO的次数都是4,所以最坏的情况下磁盘IO的次数由树的高度来决定。
从前面分析情况来看,减少磁盘IO的次数就必须要压缩树的高度,让瘦高的树尽量变成矮胖的树,所以B-Tree就在这样伟大的时代背景下诞生了。
二、B-Tree
m阶B-Tree满足以下条件:
1、每个节点最多拥有m个子树
2、根节点至少有2个子树
3、分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)
4、所有叶子节点都在同一层、每个节点最多可以有m-1个key,并且以升序排列
如下有一个3阶的B树,观察查找元素21的过程:
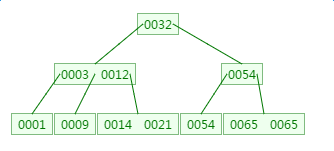
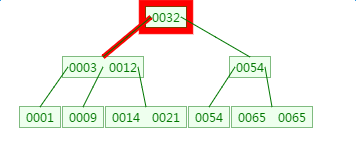
第一次磁盘IO:
第二次磁盘IO:
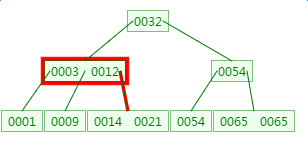
这里有一次内存对比:分别跟3与12对比
第三次磁盘IO:
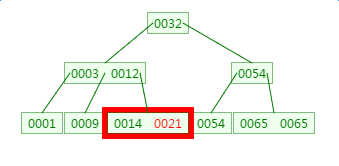
这里有一次内存比对,分别跟14与21比对
从查找过程中发现,B树的比对次数和磁盘IO的次数与二叉树相差不了多少,所以这样看来并没有什么优势。
但是仔细一看会发现,比对是在内存中完成中,不涉及到磁盘IO,耗时可以忽略不计。另外B树种一个节点中可以存放很多的key(个数由树阶决定)。
相同数量的key在B树中生成的节点要远远少于二叉树中的节点,相差的节点数量就等同于磁盘IO的次数。这样到达一定数量后,性能的差异就显现出来了。
转:为什么数据库选B-tree或B+tree而不是二叉树作为索引结构的更多相关文章
- Mysql Index、B Tree、B+ Tree、SQL Optimization
catalog . 引言 . Mysql索引 . Mysql B/B+ Tree . Mysql SQL Optimization . MySQL Query Execution Process 1. ...
- 数据库索引<一> 索引结构表结构
有很长时间没有更新博客了,再过几天都2月分了,如果再不更新一篇,我1月分都没有更新,保持连续,今天更新一篇. 最近没有什么看技术方面的东西,游戏,画画搞这些去了.我发现我每年一到年底就是搞这些东西,其 ...
- 数据库为什么要用B+树结构--MySQL索引结构的实现(转)
B+树在数据库中的应用 { 为什么使用B+树?言简意赅,就是因为: 1.文件很大,不可能全部存储在内存中,故要存储到磁盘上 2.索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数(为什么使用B-/ ...
- 关系型数据库为什么喜欢使用B+树作为索引结构? (转)
问题1. 数据库为什么要设计索引? 图书馆存了1000W本图书,要从中找到<架构师之路>,一本本查,要查到什么时候去? 于是,图书管理员设计了一套规则: (1)一楼放历史类,二楼放文学类, ...
- 【Java面试】Mysql为什么使用B+Tree作为索引结构
一个工作8年的粉丝私信了我一个问题. 他说这个问题是去阿里面试的时候被问到的,自己查了很多资料也没搞明白,希望我帮他解答. 问题是: "Mysql为什么使用B+Tree作为索引结构" ...
- B-Tree、B+Tree和B*Tree
B-Tree(这儿可不是减号,就是常规意义的BTree) 是一种多路搜索树: 1.定义任意非叶子结点最多只有M个儿子:且M>2: 2.根结点的儿子数为[2, M]: 3.除根结点以外的非叶子结点 ...
- 【Luogu1501】Tree(Link-Cut Tree)
[Luogu1501]Tree(Link-Cut Tree) 题面 洛谷 题解 \(LCT\)版子题 看到了顺手敲一下而已 注意一下,别乘爆了 #include<iostream> #in ...
- 【BZOJ3282】Tree (Link-Cut Tree)
[BZOJ3282]Tree (Link-Cut Tree) 题面 BZOJ权限题呀,良心luogu上有 题解 Link-Cut Tree班子提 最近因为NOIP考炸了 学科也炸了 时间显然没有 以后 ...
- [LeetCode] Encode N-ary Tree to Binary Tree 将N叉树编码为二叉树
Design an algorithm to encode an N-ary tree into a binary tree and decode the binary tree to get the ...
随机推荐
- 什么是NFT?
我有一个年轻朋友,最近买了一个数字艺术品,9百多入手,几周后卖掉,赚了7万多,他告诉我这个东西叫NFT. 2021年twitter创始人杰克.多西将自己发布的第一条twitter通过NFT以250万美 ...
- IDEA 快捷键和字体设置
IDEA的使用 一.IDEA 目录 IDEA的使用 一.IDEA 设置字体 文本字体设置 窗口字体设置 二.IDEA建立项目 三.IDEA快捷键 设置字体 点击File->Settings 文本 ...
- gitee的使用
git clone git add . # 跟踪所有改动过的文件 git commit -m "commit message" # 提交所有更新过的文件 git checkout ...
- PHP底层运行原理简括
PHP是一种适用于web开发的动态语言.具体点说,就是一个用C语言实现包含大量组件模块的软件框架.是一个强大的UI框架. 简言之:PHP动态语言执行过程:拿到一段代码后,经过词法解析.语法解析等阶段后 ...
- Laravel 自定命令以及生成文件
以创建service层为例子 1.执行命令 php artisan make:command ServiceMakeCommand 2.在app\Console\Commands 下就会多出一个 Se ...
- cookie与session(全面了解)
目录 一:cookie与session 1.什么是Cookie? 2.Cookie主要用于以下三个方面 3.什么是Session? 4.Cookie与Session有什么不同? 5.为什么需要Cook ...
- 0x02 TeamViewer日志溯源
1.环境部署 1.安装ubuntu_x64的deb安装包 2.打开TeamViewer 2.日志目录 1.通过图形应用找到日志文件 2.通过命令定位日志文件 find / -name "Te ...
- ESXI 虚拟化误删除管理端口Management Network (vmk0),导致无法访问后台解决方案
按F2开启控制台shell,启用后返回.按Alt+F1打开终端. 输入 esxcfg-vmknic -a -i 192.168.1.10 -n 255.255.255.0 "Manageme ...
- Netty异步Future源码解读
本文地址: https://juejin.im/post/5df771ee6fb9a0161d743069 说在前面 本文的 Netty源码使用的是 4.1.31.Final 版本,不同版本会有一些差 ...
- Django基础三之路由、视图、模板
Django基础三之路由.视图.模板 目录 Django基础三之路由.视图.模板 1. Django 请求和返回周期 1.1 路由层之路由匹配 1.2 有名分组 1.3 无名分组 2. 反射解析 3. ...