数据库之【常用sql语句归纳】
一、数据库操作:
1.创建数据库
create database dbname;
2.创建库是否存在,不存在就创建
create database if not exists dbname;
3.查看所有数据库
show databases;
4.删除数据库:
drop database dbname;
5.备份数据库:
BACKUP DATABASE TestDB TO DISK='d:\mcgrady\db\bak\TaskDB.bak' WITH COMPRESSION; 注意要带上WITH COMPRESSION
二、表操作:
1.创建新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],……)
eg:
create table student(
id int,
name varchar(32),
age int,
score double(4,1),
birthday date,
insert_time timestamp
);
2.根据已有的表建立新表
A:create table tab_new like tab_old
B:create table tab_new as select col1,col2… from tab_old definition only
3.删除新表
drop table 表名;
drop table if exists 表名;
4.添加/删除列
①添加一列
alter table 表名 add 列名 数据类型
注:列增长后将不能删除。DB2中列加上后数据类型也不能改变,惟一能改变的是增长varchar类型的长度。
②删除列
alter table 表名 drop 列名;
5.添加主键
Alter table tabname add primary key(col)
6.删除主键
Alter table tabname drop primary key(col)
7.建立索引
create [unique] index idxname on tabname(col….)
8.删除索引
drop index idxname
注:索引是不可更改的,想更改必须删除从新建。
9.查看表结构
desc 表名;
三、CRUD:
1)select语句:
语法:SELECT 列名称 FROM 表名称
查找:select * from table1 where field1 like ’%value1%’ 排序:select * from table1 order by field1,field2 [desc] 总数:select count * as totalcount from table1 求和:select sum(field1) as sumvalue from table1 平均:select avg(field1) as avgvalue from table1 最大:select max(field1) as maxvalue from table1 最小:select min(field1) as minvalue fromtable1
2)insert语句:
insert into 表名(列名1,列名2,……列名n) values(值1,值2,……值n) ; //写全所有列名
insert into 表名 values(值1,值2,……值n); //不写列名(所以列全部添加)
3)删除语句:
delete from 表名 where 列名 = 值; //删除表中数据
delete from 表名; //删除表中所有数据
truncate table 表名; //删除表中所有数据(高效 先删除表,然后再创建一张一样的表。)
4)更新语句:
update 表名 set 列名 = 值; //不带条件的修改(会修改所有行)
update 表名 set 列名=值 where 列名=值; //带条件的修改
5)where语句:
SELECT 列名称 FROM 表名称 WHERE 列 运算符 值
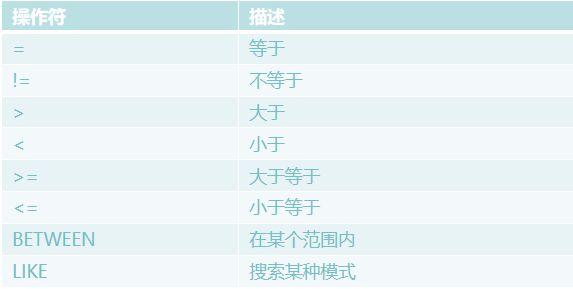
SQL 使用单引号来环绕文本值。若果是数值,不能使用引号。
6)distinct语句(去掉重复数据)
SELECT DISTINCT 列名称 FROM 表名称
四、外连接示例
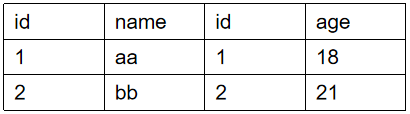
eg:以下两张表分别是姓名表和年龄表
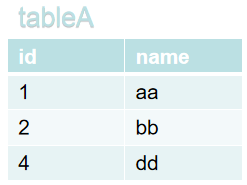
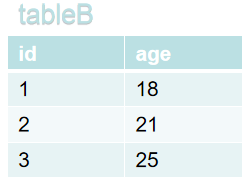
①内连接(Inner Join)
只返回条件匹配的行
select * from tableA JOIN tableB on tableA.id=tableB.id
执行结果:
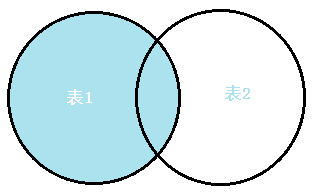
②左外连接(Left join)
左表全部出现在结果集中,若右表无对应记录,则相应字段为NULL
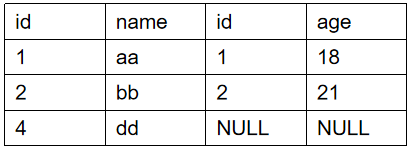
select * from tableA left join tableB on tableA.id=tableB.id
执行结果:
③右外连接(Right join)
右表全部出现在结果集中,若左表无对应记录,则相应字段为NULL
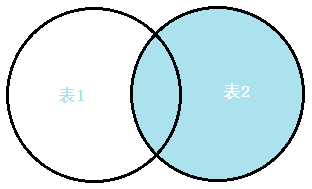
select * from tableA right join tableB on tableA.id=tableB.id
执行结果:

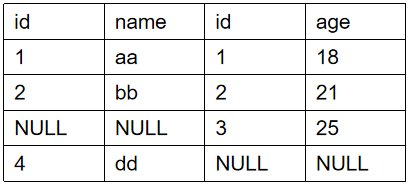
④全连接(Full join)
全连接=左外连接+右外连接
返回左右表中所有的记录和左右表中连接字段相等的记录,条件不匹配的行的值为NULL
select * from tableA full join tableB on tableA.id=tableB.id
执行结果:
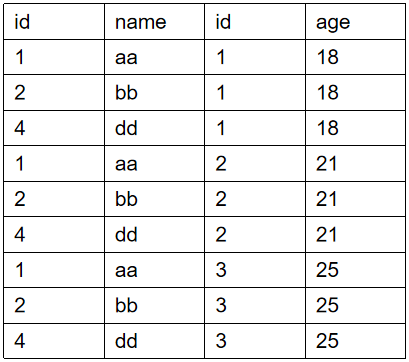
⑤交叉连接
没有where条件的交叉连接将产生连接表所涉及的笛卡尔积。即tableA的行数*tableB的行数的结果集。(tableA 3行*tableB 3行=9行)
select * from tableA cross join tableB
执行结果:
五、group by用法
“Group By” 从字面意义上理解就是根据 “By” 指定的规则对数据进行分组,所谓的分组就是将一个 “数据集” 划分成若干个 “小区域”,然后针对若干个 “小区域” 进行数据处理。
GROUP BY子句是SELECT语句的可选子句,它根据指定列中的匹配值将行组合成组,每组返回一行。
select 字段名 from 表名 where 条件 group by 字段名;
使用group by可以对查询结果进行分组,但是group by需要和sql的聚合函数联合使用。sql的聚合函数包括以下这些:
- count()求符合条件的记录数
- max()和 min()求某一列的最大值和最小值
- avg()求某一列的平均值
- sum()求某一列的总和
具体使用示例:
以下内容原文链接:https://blog.csdn.net/Elainalu/article/details/89489041

上图是表bookinfo,包含了一系列的字段 ,现在我们按照"出版社"来对表进行分组统计:
select publish as 出版社,count(publish) as 图书数量 from BookInfo group by publish;
以上语句分析如下:
select publish as 出版社,count(publish) as 图书数量 //这行代码首先将publish设置一个别名 "出版社",然后 count(publish)as "图书数量",是将publish进行计数
from bookinfo //表示数据来源于表bookinfo
group by publish //表示对数据表按照publish字段进行分类,相同的publish为一类,count(publish)即为统计一共多少类。
执行结果如下图: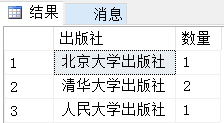
==============================================================================================
再举个例子,同样是上面的bookinfo,我们对出版社分组,然后对每个出版社出版书籍的价格求平均值:
select publish '出版社',AVG(price) '平均价格' from bookinfo group by publish;
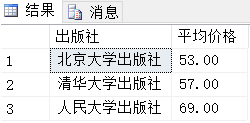
需要注意的是,select后面跟的列名,必须包含在聚合函数中,或者包含在group by子句中,比如上式中,字段名publish就包含在group by子句中,而price包含在avg聚合函数里。
=========================================================================================
select publish '出版社',AVG(price) '平均价格' from bookinfo group by publish having avg(price) > 55
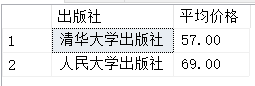
需要注意的是having必须和group by配合使用不可单独使用,where是从表中筛选,having是从组中筛选
数据库之【常用sql语句归纳】的更多相关文章
- 【知识库】-数据库_MySQL常用SQL语句语法大全示例
简书作者:seay 文章出处: 关系数据库常用SQL语句语法大全 Learn [已经过测试校验] 一.创建数据库 二.创建表 三.删除表 四.清空表 五.修改表 六.SQL查询语句 七.SQL插入语句 ...
- 1.4 数据库和常用SQL语句(正文)——MySQL数据库命令和SQL语句
前面我们已经讲述了,登录时,我们使用mysql –u root –p命令进行,此时如果设置了密码,则需要输入密码. 输入密码后即进入MySQL的操作界面,此时,命令行窗体左侧显示"mysql ...
- GP数据库 常用SQL语句
GP数据库 常用SQL语句 --1,查看列名以及类型 select upper(column_name) ,data_type from information_schema.columns wher ...
- Oracle数据库常用Sql语句大全
一,数据控制语句 (DML) 部分 1.INSERT (往数据表里插入记录的语句) INSERT INTO 表名(字段名1, 字段名2, ……) VALUES ( 值1, 值2, ……); INSE ...
- MySQL用户管理、常用sql语句、MySQL数据库备份恢复
1.MySQL用户管理 给远程登陆用户授权:grant all on *.* to 'user1'@'127.0.0.1' identified by '123456' (这里的127.0.0.1是指 ...
- Linux centosVMware mysql用户管理、常用sql语句、mysql数据库备份恢复
一.mysql用户管理 grant all on *.* to 'user1'@‘127.0.0.1’ identified by 'mimA123'; 创建user1用户 使用user1登录 /us ...
- Mysql常用sql语句(一)- 操作数据库
21篇测试必备的Mysql常用sql语句,每天敲一篇,每次敲三遍,每月一循环,全都可记住!! https://www.cnblogs.com/poloyy/category/1683347.html ...
- 50个常用SQL语句
50个常用SQL语句 Student(S#,Sname,Sage,Ssex) 学生表 S#学号,主键 Course(C#,Cname,T#) 课程表 C#课程号,主键 SC(S#, ...
- oracle sqlplus及常用sql语句
常用sql语句 有需求才有动力 http://blog.csdn.net/yitian20000/article/details/6256716 常用sql语句 创建表空间:create tables ...
- oracle常用SQL语句(汇总版)
Oracle数据库常用sql语句 ORACLE 常用的SQL语法和数据对象一.数据控制语句 (DML) 部分 1.INSERT (往数据表里插入记录的语句) INSERT INTO 表名(字段名1, ...
随机推荐
- 《计算机是怎么跑起来的》第十章 XML(可扩展标记语言)
资料来源 (1) <计算机是怎么跑起来的> 注1:XML是Extensible Markup Language(可扩展标记语言)的缩写; 1.XML是标记语言 (1) 通常把通过添加标签为 ...
- IIS部署HTTPS站点
常用的IIS大体有二个版本: IIS8和IIS7,分别有不同的配置方法如下: IIS8.5以上版本 1).新建一个站点,切记尽量不要与旧http协议站点共用一个站点,容易冲突 2).先将https证书 ...
- 解题报告:Codeforces 279C Ladder
Codeforces 279C Ladder 本题与tbw这篇博客上的题有相似思路.tbw的本来我还不会,抄了题解才过,这道题好歹自己磕半天磕出来了.到tbw做那道题我突然想明白了,再一想诶跟这里不是 ...
- Windows 10更新报错 0x8000ffff
Windows 10更新报错 0x8000ffff - Microsoft Community 那么您可用 "Windows 10 覆盖安装" 来修复,可参考以下步伐,连接里有视频 ...
- C++future promise
A future is an object that can retrieve a value from some provider object or function, properly sync ...
- JQuery电梯导航
// .zjong .dag_id 内容区// .zuoyou .dao_hang a 电梯按钮 $(function() { $(".zjong .dag_id").each(( ...
- 2022.11.13 NOIP2022 模拟赛八
「ROI 2017 Day 2」存储器 无聊的题. 首先 \(s\) 中每一个片段,其在 \(t\) 中对应的字符必然是相同的. 对于 \(t\) 中的每一个片段,考虑检查能否操作出这个片段,实际上只 ...
- requests断点续传功能
requests取消ssl验证会出现告警InsecureRequestWarning,取消告警如下: import urllib3urllib3.disable_warnings(urllib3.ex ...
- mysql8.0修改密码
把密码设置为空:UPDATE mysql.user SET authentication_string='' WHERE user='root' and host='localhost'; 查看USE ...
- Cascader 级联选择器 数据不回显
这次的问题原因主要是因为 数据存在于两张表 并且索引的字段不同 一个为id(int)一个为字符(string) 在做修改操作数据回显的时候会导致 后端返回的数组中一个为字符一个为bumber ...