想让DBA瞬间崩溃,那就让他去做SQL性能优化
摘要:很多大数据计算都是用 SQL 实现的,跑得慢时就要去优化 SQL,但常常碰到让人干瞪眼的情况。
本文分享自华为云社区《做 SQL 性能优化真是让人干瞪眼》,作者: 石臻臻的杂货铺 。
很多大数据计算都是用 SQL 实现的,跑得慢时就要去优化 SQL,但常常碰到让人干瞪眼的情况。比如,存储过程中有三条大概形如这样的语句执行得很慢:
select a,b,sum(x) from T group by a,b where …;
select c,d,max(y) from T group by c,d where …;
select a,c,avg(y),min(z) from T group by a,c where …;
这里的 T 是个有数亿行的巨大表,要分别按三种方式分组,分组的结果集都不大。
分组运算要遍历数据表,这三句 SQL 就要把这个大表遍历三次,对数亿行数据遍历一次的时间就不短,何况三遍。
这种分组运算中,相对于遍历硬盘的时间,CPU 计算时间几乎可以忽略。如果可以在一次遍历中把多种分组汇总都计算出来,虽然 CPU 计算量并没有变少,但能大幅减少硬盘读取数据量,就能成倍提速了。
如果 SQL 支持类似这样的语法:
from T -- 数据来自 T 表
select a,b,sum(x) group by a,b where … -- 遍历中的第一种分组
select c,d,max(y) group by c,d where … -- 遍历中的第二种分组
select a,c,avg(y),min(z) group by a,c where …; -- 遍历中的第三种分组
能一次返回多个结果集,那就可以大幅提高性能了。
可惜, SQL 没有这种语法,写不出这样的语句,只能用个变通的办法,就是用 group a,b,c,d 的写法先算出更细致的分组结果集,但要先存成一个临时表,才能进一步用 SQL 计算出目标结果。SQL 大致如下:
create table T_temp as select a,b,c,d,
sum(case when … then x else 0 end) sumx,
max(case when … then y else null end) maxy,
sum(case when … then y else 0 end) sumy,
count(case when … then 1 else null end) county,
min(case when … then z else null end) minz
group by a,b,c,d;
select a,b,sum(sumx) from T_temp group by a,b where …;
select c,d,max(maxy) from T_temp group by c,d where …;
select a,c,sum(sumy)/sum(county),min(minz) from T_temp group by a,c where …;
这样只要遍历一次了,但要把不同的 WHERE 条件转到前面的 case when 里,代码复杂很多,也会加大计算量。而且,计算临时表时分组字段的个数变得很多,结果集就有可能很大,最后还对这个临时表做多次遍历,计算性能也快不了。大结果集分组计算还要硬盘缓存,本身性能也很差。
还可以用存储过程的数据库游标把数据一条一条 fetch 出来计算,但这要全自己实现一遍 WHERE 和 GROUP 的动作了,写起来太繁琐不说,数据库游标遍历数据的性能只会更差!
只能干瞪眼!
TopN 运算同样会遇到这种无奈。举个例子,用 Oracle 的 SQL 写 top5 大致是这样的:
select * from (select x from T order by x desc) where rownum<=5
表 T 有 10 亿条数据,从 SQL 语句来看,是将全部数据大排序后取出前 5 名,剩下的排序结果就没用了!大排序成本很高,数据量很大内存装不下,会出现多次硬盘数据倒换,计算性能会非常差!
避免大排序并不难,在内存中保持一个 5 条记录的小集合,遍历数据时,将已经计算过的数据前 5 名保存在这个小集合中,取到的新数据如果比当前的第 5 名大,则插入进去并丢掉现在的第 5 名,如果比当前的第 5 名要小,则不做动作。这样做,只要对 10 亿条数据遍历一次即可,而且内存占用很小,运算性能会大幅提升。
这种算法本质上是把 TopN 也看作与求和、计数一样的聚合运算了,只不过返回的是集合而不是单值。SQL 要是能写成这样:select top(x,5) from T 就能避免大排序了。
然而非常遗憾,SQL 没有显式的集合数据类型,聚合函数只能返回单值,写不出这种语句!
不过好在全集的 TopN 比较简单,虽然 SQL 写成那样,数据库却通常会在工程上做优化,采用上述方法而避免大排序。所以 Oracle 算那条 SQL 并不慢。
但是,如果 TopN 的情况复杂了,用到子查询中或者和 JOIN 混到一起的时候,优化引擎通常就不管用了。比如要在分组后计算每组的 TopN,用 SQL 写出来都有点困难。Oracle 的 SQL 写出来是这样
select * from
(select y,x,row_number() over (partition by y order by x desc) rn from T)
where rn<=5
这时候,数据库的优化引擎就晕了,不会再采用上面说的把 TopN 理解成聚合运算的办法。只能去做排序了,结果运算速度陡降!
假如 SQL 的分组 TopN 能这样写:
select y,top(x,5) from T group by y
把 top 看成和 sum 一样的聚合函数,这不仅更易读,而且也很容易高速运算。
可惜,不行。还是干瞪眼!
关联计算也是很常见的情况。以订单和多个表关联后做过滤计算为例,SQL 大体是这个样子:
select o.oid,o.orderdate,o.amount
from orders o
left join city ci on o.cityid = ci.cityid
left join shipper sh on o.shid=sh.shid
left join employee e on o.eid=e.eid
left join supplier su on o.suid=su.suid
where ci.state='New York'
and e.title = 'manager'
and ...
订单表有几千万数据,城市、运货商、雇员、供应商等表数据量都不大。过滤条件字段可能会来自于这些表,而且是前端传参数到后台的,会动态变化。
SQL 一般采用 HASH JOIN 算法实现这些关联,要计算 HASH 值并做比较。每次只能解析一个 JOIN,有 N 个 JOIN 要执行 N 遍动作,每次关联后都需要保持中间结果供下一轮使用,计算过程复杂,数据也会被遍历多次,计算性能不好。
通常,这些关联的代码表都很小,可以先读入内存。如果将订单表中的各个关联字段预先做序号化处理,比如将雇员编号字段值转换为对应雇员表记录的序号。那么计算时,就可以用雇员编号字段值(也就是雇员表序号),直接取内存中雇员表对应位置的记录,性能比 HASH JOIN 快很多,而且只需将订单表遍历一次即可,速度提升会非常明显!
也就是能把 SQL 写成下面的样子:
select o.oid,o.orderdate,o.amount
from orders o
left join city c on o.cid = c.# -- 订单表的城市编号通过序号 #关联城市表
left join shipper sh on o.shid=sh.# -- 订单表运货商号通过序号 #关联运货商表
left join employee e on o.eid=e.# -- 订单表的雇员编号通过序号 #关联雇员表
left join supplier su on o.suid=su.# -- 订单表供应商号通过序号 #关联供应商表
where ci.state='New York'
and e.title = 'manager'
and ...
可惜的是,SQL 使用了无序集合概念,即使这些编号已经序号化了,数据库也无法利用这个特点,不能在对应的关联表这些无序集合上使用序号快速定位的机制,只能使用索引查找,而且数据库并不知道编号被序号化了,仍然会去计算 HASH 值和比对,性能还是很差!
有好办法也实施不了,只能再次干瞪眼!
还有高并发帐户查询,这个运算倒是很简单:
select id,amt,tdate,… from T
where id='10100'
and tdate>= to_date('2021-01-10', 'yyyy-MM-dd')
and tdate<to_date('2021-01-25', 'yyyy-MM-dd')
and …
在 T 表的几亿条历史数据中,快速找到某个帐户的几条到几千条明细,SQL 写出来并不复杂,难点是大并发时响应速度要达到秒级甚至更快。为了提高查询响应速度,一般都会对 T 表的 id 字段建索引:
create index index_T_1 on T(id)
在数据库中,用索引查找单个帐户的速度很快,但并发很多时就会明显变慢。原因还是上面提到的 SQL 无序理论基础,总数据量很大,无法全读入内存,而数据库不能保证同一帐户的数据在物理上是连续存放的。硬盘有最小读取单位,在读不连续数据时,会取出很多无关内容,查询就会变慢。高并发访问的每个查询都慢一点,总体性能就会很差了。在非常重视体验的当下,谁敢让用户等待十秒以上?!
容易想到的办法是,把几亿数据预先按照帐户排序,保证同一帐户的数据连续存储,查询时从硬盘上读出的数据块几乎都是目标值,性能就会得到大幅提升。
但是,采用 SQL 体系的关系数据库并没有这个意识,不会强制保证数据存储的物理次序!这个问题不是 SQL 语法造成的,但也和 SQL 的理论基础相关,在关系数据库中还是没法实现这些算法。
那咋办?只能干瞪眼吗?
不能再用 SQL 和关系数据库了,要使用别的计算引擎。
开源的集算器 SPL 基于创新的理论基础,支持更多的数据类型和运算,能够描述上述场景中的新算法。用简单便捷的 SPL 写代码,在短时间内能大幅提高计算性能!
上面这些问题用 SPL 写出来的代码样例如下:
一次遍历计算多种分组
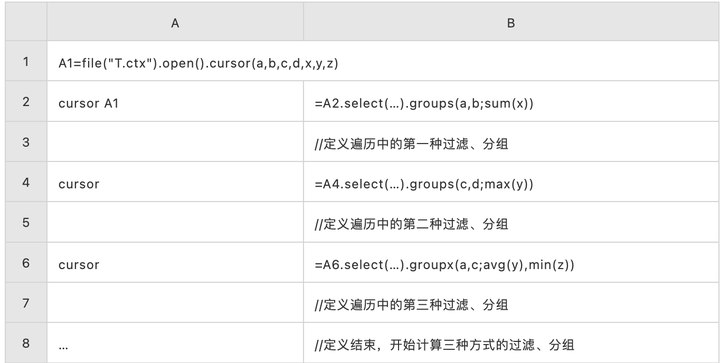
用聚合的方式计算 Top5
全集 Top5(多线程并行计算)
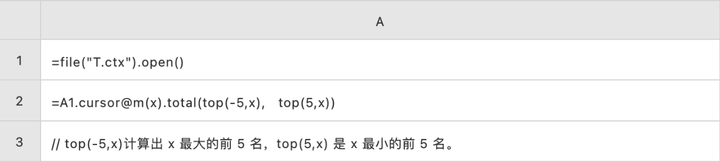
分组 Top5(多线程并行计算)

用序号做关联的 SPL 代码:
系统初始化

查询

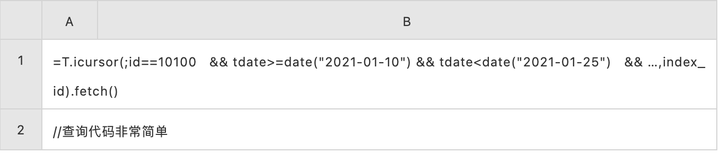
高并发帐户查询的 SPL 代码:
数据预处理,有序存储

帐户查询
除了这些简单例子,SPL 还能实现更多高性能算法,比如有序归并实现订单和明细之间的关联、预关联技术实现多维分析中的多层维表关联、位存储技术实现上千个标签统计、布尔集合技术实现多个枚举值过滤条件的查询提速、时序分组技术实现复杂的漏斗分析等等。
正在为 SQL 性能优化头疼的小伙伴们,来和我们一起探讨吧:
SPL下载地址:http://c.raqsoft.com.cn/article/1595816810031
SPL开源地址:https://github.com/SPLWare/esProc
想让DBA瞬间崩溃,那就让他去做SQL性能优化的更多相关文章
- Salt Stack 官方文档翻译 - 一个想做dba的sa - 博客频道 - CSDN.NET
OSNIT_百度百科 Salt Stack 官方文档翻译 - 一个想做dba的sa - 博客频道 - CSDN.NET Salt Stack 官方文档翻译 分类: 自动运维 2013-04-02 11 ...
- MySQL DBA教程:Mysql性能优化之缓存参数优化
在平时被问及最多的问题就是关于 MySQL 数据库性能优化方面的问题,所以最近打算写一个MySQL数据库性能优化方面的系列文章,希望对初中级 MySQL DBA 以及其他对 MySQL 性能优化感 ...
- EF性能优化-有人说EF性能低,我想说:EF确实不如ADO.NET
十年河东,十年河西,莫欺少年穷. EF就如同那个少年,ADO.NET则是一位壮年.毕竟ADO.NET出生在EF之前,而EF所走的路属于应用ADO.NET. 也就是说:你所写的LINQ查询,最后还是要转 ...
- 想做iPhoneX抢购活动?压测大师先教你优化网站后台
北京时间9月13日凌晨1点,iPhone 10周年,在Apple Park乔布斯剧院,苹果发布了三款新iPhone.全面屏iPhone X来袭,这款被定义为未来的智能手机黑科技满满:全面屏,无线充电. ...
- Delphi XE8中开发DataSnap程序常见问题和解决方法 (二)想对DBExpress的TSQLDataSet写对数据库操作的SQL语句出错了!
当我们搞定DataSnap后,我们进入客户端程序开发阶段了,我们建立了客户端模块后,打算按照刚才开发服务器的步骤开发客户端程序,随后加入了DBExpress的TSQLDataSet,设定数据库连接后, ...
- SQL Server DBA性能优化
虽然查询速度慢的原因很多,但是如果通过一定的优化,也可以使查询问题得到一定程度的解决. 查询速度慢的原因很多,常见如下几种:1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)2. ...
- 魅族资深DBA:利用MHA构建MySQL高可用平台
龙启东 魅族资深DBA 负责MySQL.Redis.MongoDB以及自动化平台建设 .擅长MySQL高可用方案.SQL性能优化.故障诊断等. 本次分享主要包括以下几方面: 如何利用MHA 改造MHA ...
- 关于数据库SQL优化
1.数据库访问优化 要正确的优化SQL,我们需要快速定位能性的瓶颈点,也就是说快速找到我们SQL主要的开销在哪里?而大多数情况性能最慢的设备会是瓶颈点,如下载时网络速度可能会是瓶颈点,本地复制文件 ...
- sql优化(原理,方法,特点,实例)
整理的有点多,做好心理准备...... 1.资源优化理解: 不同设备,io不同.每种设备都有两个指标:延时(响应时间):表示硬件的突发处理能力:带宽(吞吐量):代表硬件持续处理能力. 每种硬件主要的工 ...
随机推荐
- 配置多个ssh公钥,解决Key is already in use
背景:我已经有一个ssh公钥和私钥了,绑定的是公司的码云 但是绑定github是不允许的 所以我需要在生成一个公钥和私钥 第一步执行下面的命令, 至于如果生成ssh公钥点击这里 ssh-keygen ...
- Solution -「CTS2019」珍珠
题目 luogu. 题解 先 % 兔.同为兔子为什么小粉兔辣么强qwq. 本文大体跟随小粉兔的题解的思路,并为像我一样多项式超 poor 的读者作了很详细的解释.如果题解界面公式出现问题,可以 ...
- [LeetCode]7. 整数反转(Java)
原题地址: reverse-integer 题目描述: 给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果. 如果反转后整数超过 32 位的有符号整数的范围 [−2^31, ...
- suse 12 二进制部署 Kubernetets 1.19.7 - 第03章 - 部署flannel插件
文章目录 1.3.部署flannel网络 1.3.0.下载flannel二进制文件 1.3.1.创建flannel证书和私钥 1.3.2.生成flannel证书和私钥 1.3.3.将pod网段写入et ...
- tomcat 配置https证书 ssl
修改tomcat-conf-server.xml,原配置文件是 <Connector connectionTimeout="20000" port="8080&qu ...
- 中国著名hacker---陈三堰
在学习<网络攻防>这门课程中,我了解到了黑客之间的斗智斗勇,同样也对中国本土黑客产生了兴趣,之后,我将用一段时间扒一扒这其中比较有分量的传奇人物--陈三堰. 真名:陈三堰 网名:陈三少 所 ...
- R数据分析:样本量计算的底层逻辑与实操,pwr包
样本量问题真的是好多人的老大难,是很多同学科研入门第一个拦路虎,今天给本科同学改大创标书又遇到这个问题,我想想不止是本科生对这个问题不会,很多同学从上研究生到最后脱离科研估计也没能把这个问题弄得很明白 ...
- 【C# TAP 异步编程】一 、async 修饰符(标记)
async的作用: 1.async是一个标记,告诉编译器这是一个异步方法. 2.编译器会根据这个标志生成一个异步状态机. 3.编译器将原异步方法中的代码清空,写入状态机的配置,原先异步方法中的代码被封 ...
- CDH5.16.2离线安装(详细)
目录 01 Coudera Manager 02 环境准备 03 CM安装 01 Coudera Manager 概念:拥有集群自动化安装.中心化管理.集群监控.报警功能的一个工具,使集群安装从几天时 ...
- 【用户状态】详细解读Oracle用户ACCOUNT_STATUS的九种状态
转至:http://blog.itpub.net/519536/viewspace-672276/ DBA_USERS视图中ACCOUNT_STATUS记录的用户的当前状态,一般情况下在使用的正常用户 ...