【离线数仓】Day01-用户行为数据采集:数仓概念、需求及架构、数据生成及采集、linux命令及其他组件常见知识
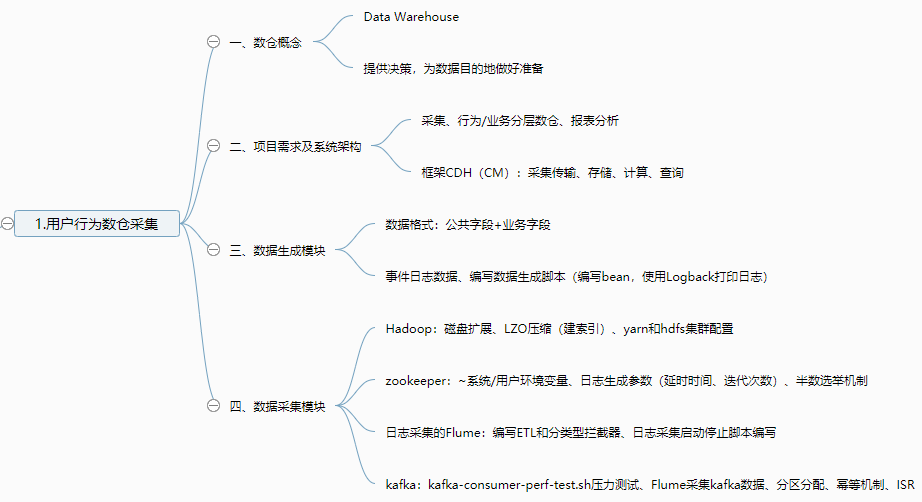
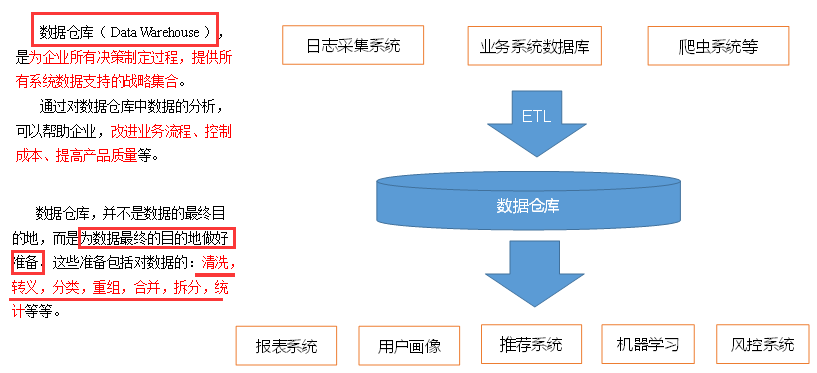
一、数据仓库概念
二、项目需求及架构设计
1、需求分析



2、项目框架

3、框架版本选型
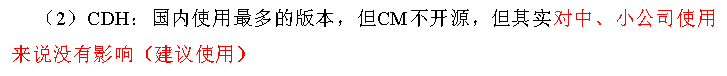
服务器选型:云主机
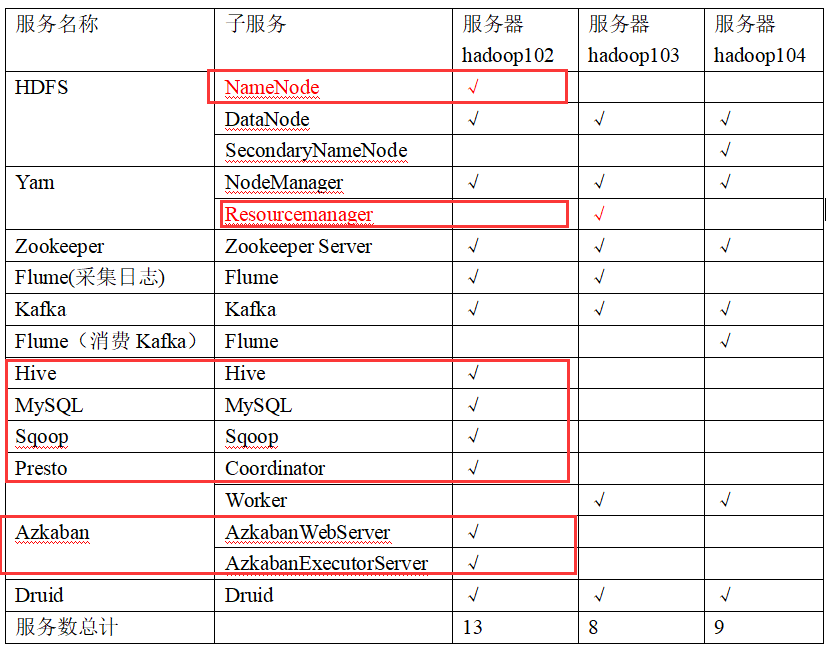
服务器规划
三、数据生成模块
1、数据基本格式
公共字段:所有手机都包含
业务字段:埋点上报的字段,有具体的业务类型
"et": [ //事件
{
"ett": "1506047605364", //客户端事件产生时间
"en": "display", //事件名称
"kv": { //事件结果,以key-value形式自行定义
"goodsid": "236",
"action": "1",
"extend1": "1",
"place": "2",
"category": "75"
}
}
]
}
2、事件日志数据

3、启动日志数据
|
标签 |
含义 |
|
entry |
入口: push=1,widget=2,icon=3,notification=4, lockscreen_widget =5 |
|
open_ad_type |
开屏广告类型: 开屏原生广告=1, 开屏插屏广告=2 |
|
action |
状态:成功=1 失败=2 |
|
loading_time |
加载时长:计算下拉开始到接口返回数据的时间,(开始加载报0,加载成功或加载失败才上报时间) |
|
detail |
失败码(没有则上报空) |
|
extend1 |
失败的message(没有则上报空) |
|
en |
日志类型start |
{
"action":"1",
"ar":"MX",
"ba":"HTC",
"detail":"",
"en":"start",
"entry":"2",
"extend1":"",
"g":"43R2SEQX@gmail.com",
"hw":"640*960",
"l":"en",
"la":"20.4",
"ln":"-99.3",
"loading_time":"2",
"md":"HTC-2",
"mid":"995",
"nw":"4G",
"open_ad_type":"2",
"os":"8.1.2",
"sr":"B",
"sv":"V2.0.6",
"t":"1561472502444",
"uid":"995",
"vc":"10",
"vn":"1.3.4"
}
4、数据生成脚本

创建公共字段bean、启动日志bean和一系列操作的bean

Logback主要用于在磁盘和控制台打印日志。
resources文件夹下创建logback.xml文件
将编写好的项目打成jar包
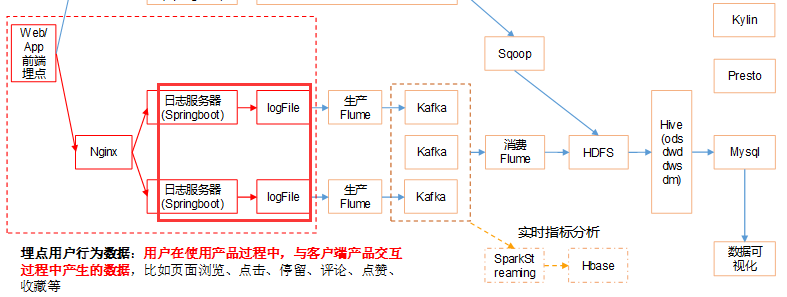
四、数据采集模块

1、Hadoop安装
hdfs和yarn的集群规划
|
服务器hadoop102 |
服务器hadoop103 |
服务器hadoop104 |
|
|
HDFS |
NameNode DataNode |
DataNode |
DataNode SecondaryNameNode |
|
Yarn |
NodeManager |
Resourcemanager NodeManager |
NodeManager |
DataNode进行磁盘扩展,hdfs-site.xml文件中配置多目录
支持LZO压缩配置,使用twitter提供的hadoop-lzo开源组件
core-site.xml中配置并xsync
启动、测试、建立索引
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output hadoop jar ./share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /output
基准测试与参数调优
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
hdfs和yarn调优
2、Zookeeper安装
编写群起脚本
配置系统环境变量source /etc/profile与特定用户环境变量~/.bashrc文件
3、日志生成
日志启动参数:
// 参数一:控制发送每条的延时时间,默认是0
Long delay = args.length > 0 ? Long.parseLong(args[0]) : 0L; // 参数二:循环遍历次数
int loop_len = args.length > 1 ? Integer.parseInt(args[1]) : 1000;
上传执行生成
[atguigu@hadoop102 module]$ java -classpath log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar com.atguigu.appclient.AppMain >/opt/module/test.log
生成启动脚本
#! /bin/bash
for i in hadoop102 hadoop103
do
ssh $i "java -classpath /opt/module/gmall/logcollector-1.0-SNAPSHOT-jar-with-dependencies.jar com.atguigu.appclient.AppMain $1 $2 > /opt/module/test.log &"
done
时间同步修改脚本:sudo date -s $1
进程查看脚本:ssh $i "$*"
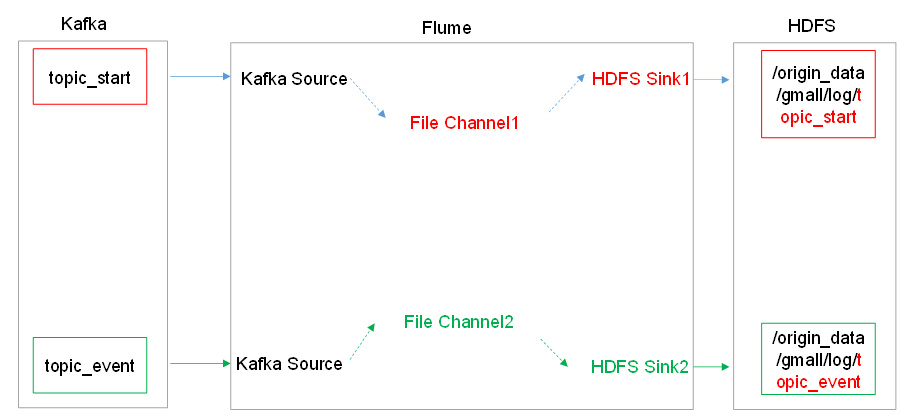
4、采集日志flume
|
服务器hadoop102 |
服务器hadoop103 |
服务器hadoop104 |
|
|
Flume(采集日志) |
Flume |
Flume |
组件:source、channel
ETL和分类型拦截器
ETL拦截器主要用于,过滤时间戳不合法和Json数据不完整的日志
日志类型区分拦截器主要用于,将启动日志和事件日志区分开来,方便发往Kafka的不同Topic。
public class LogTypeInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event)
分发至lib目录
编写日志采集flume启动停止脚本
#! /bin/bash case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE > /dev/null 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs kill"
done };;
esac
5、kafka安装
压力测试:
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
[atguigu@hadoop102 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput 1000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
Kafka机器数量(经验公式)=2*(峰值生产速度*副本数/100)+1
6、消费Kafka数据Flume
|
服务器hadoop102 |
服务器hadoop103 |
服务器hadoop104 |
|
|
Flume(消费Kafka) |
Flume |
五、总结
1、数据采集模块
Linux&Shell相关总结
|
序号 |
命令 |
命令解释 |
|
1 |
top |
查看内存 |
|
2 |
df -h |
查看磁盘存储情况 |
|
3 |
iotop |
查看磁盘IO读写(yum install iotop安装) |
|
4 |
iotop -o |
直接查看比较高的磁盘读写程序 |
|
5 |
netstat -tunlp | grep 端口号 |
查看端口占用情况 |
|
6 |
uptime |
查看报告系统运行时长及平均负载 |
|
7 |
ps aux |
查看进程 |
shell工具:awk、sed、cut、sort
2、zookeeper总结
1)选举机制
半数机制
2)常用命令
ls、get、create
3、Hadoop总结
1)Hadoop默认不支持LZO压缩,如果需要支持LZO压缩,需要添加jar包,并在hadoop的cores-site.xml文件中添加相关压缩配置。(建表时候安装)
2)Hadoop常用端口号
3)Hadoop配置文件以及简单的Hadoop集群搭建
4)HDFS读流程和写流程
5)MapReduce的Shuffle过程及Hadoop优化(包括:压缩、小文件、集群优化)
6)Yarn的Job提交流程
7)Yarn的默认调度器、调度器分类、以及他们之间的区别
8)HDFS存储多目录
9)Hadoop参数调优
4、kafka
Kafka幂等性
Kafka0.11版本引入了幂等性,幂等性配合at least once语义可以实现exactly once语义。但只能保证单次会话的幂等。
Kafka分区分配
Range和RoundRobin
Kafka的ISR副本同步队列
ISR(In-Sync Replicas),副本同步队列。ISR中包括Leader和Follower。如果Leader进程挂掉,会在ISR队列中选择一个服务作为新的Leader。有replica.lag.max.messages(延迟条数)和replica.lag.time.max.ms(延迟时间)两个参数决定一台服务是否可以加入ISR副本队列,在0.10版本移除了replica.lag.max.messages参数,防止服务频繁的进去队列。
任意一个维度超过阈值都会把Follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的Follower也会先存放在OSR中。
【离线数仓】Day01-用户行为数据采集:数仓概念、需求及架构、数据生成及采集、linux命令及其他组件常见知识的更多相关文章
- linux命令(53):用户和用户组
Linux 用户和用户组详细解说 本文主要讲述在Linux 系统中用户(user)和用户组(group)管理相应的概念: 用户(user)和用户组(group)相关命令的列举: 其中也对单用户多任务, ...
- 【每日一linux命令7】用户及用户组
一.查询用户及用户组相关命令 1.whoami 查询当前登录的用户名 2.groups 查询当前登录用户名所在的用户组 3.groups root 查询root用户名所在的用户组 二.怎么批量查看用户 ...
- MyBatis 用户表记录数查询
搭建MyBatis开发环境,实现用户表记录数查询 1.在MyEclipse中创建工程,导入MyBatis的jar包
- Linux 下监控用户最大进程数参数(nproc)是否到达上限
Linux 下监控用户最大进程数参数(nproc)是否到达上限的步骤: 1.查看各系统用户的进程(LWP)数: 注意:默认情况下采用 ps 命令并不能显示出所有的进程.因为 Linux 环境下执行多线 ...
- Linux 用户打开进程数的调整
Linux 用户打开进程数的调整 参考文章: 关于RHEL6中ulimit的nproc限制(http://www.cnblogs.com/kumulinux/archive/2012/12/16/28 ...
- Linux 下监控用户最大进程数参数(nproc)是否到达上限的步骤:
https://www.cnblogs.com/autopenguin/p/6184886.html 1.查看各系统用户的进程(LWP)数: 注意:默认情况下采用 ps 命令并不能显示出所有的进程.因 ...
- 修改linux系统用户最大线程数限制
linux系统对线程数量有个最大限制,当达到系统限制的最大线程数时使用账号密码ssh到系统时是无法登陆的,会报Write failed: Broken pipe,或者是shell request fa ...
- 修改 Linux VM 中单个用户最大进程数的限制
在部署有并发任务执行的虚机上, 会遇到 SSH 无法访问的问题. 本文将帮助你找出其中一种比较特殊的原因, 并提供解决方案. Note 以下案例分析基于 CentOS 7, 对于其他版本的 Linux ...
- (转)AIX下修改用户最大进程数
AIX下修改用户最大进程数 原文:http://blog.csdn.net/feichideche/article/details/39498555 使用AIX时候,切换用户,发现进程一直挂起,查看用 ...
- [转载]CentOS修改用户最大进程数
FROM: http://www.2cto.com/os/201303/192380.html CentOS修改用户最大进程数 一般在/etc/security/limits.conf 中修改最大 ...
随机推荐
- Python微服务实战
文档地址:https://www.qikqiak.com/tdd-book/ GitHub地址:https://github.com/cnych/flask-microservices-users 源 ...
- Beats:使用Elastic Stack对Redis监控
- Service中spec.type 字段的值:ClusterIP和NodePort理解
ClusterIP(默认) 在群集中的内部IP上公布服务,这种方式的 Service(服务)只在集群内部可以访问到 [root@master ~]# kubectl get service -n te ...
- Alertmanager结合Slack使用
Slack作为一款即时通讯工具,协作沟通主要通过Channel(平台)来完成,用户可以在企业中根据用途添加多个Channel,并且通过Channel来集成各种第三方工具. 例如,我们可以为监控建立一个 ...
- 【Wine使用经验分享】Wine字体显示问题处理
字体不显示/字体为□ 首先尝试下载simsun字体到/usr/share/fonts (simsun.ttf simsun.ttc) 在新版本wine上,差不多就能解决问题. 如果还不行,就从网上下载 ...
- Activate MFA报错:MFADevice entity at the same path and name already exists
MFA即:Multi-factor authentication (MFA) 今天在为自己账号Activate MFA时报错,如下图所示: Entity already exists This ent ...
- POJ2486 Apple Tree(树形背包)
从每个节点u出发后有两种情况:回到u和不回到u. dp数组设为三维,第一维是节点编号,第二维是从该节点开始走的步数,第三维1/0 表示是否回到该节点. 可以回到时:dp[u][j][1]=max(dp ...
- 【机器学习】利用 Python 进行数据分析的环境配置 Windows(Jupyter,Matplotlib,Pandas)
环境配置 安装 python 博主使用的版本是 3.10.6 在 Windows 系统上使用 Virtualenv 搭建虚拟环境 安装 Virtualenv 打开 cmd 输入并执行 pip inst ...
- python今日分享(内置方法)
目录 一.习题详解 二.数据类型的内置方法理论 三.整型相关操作 四.浮点型相关操作 五.字符串相关操作 六.列表相关操作 今日详解 一.习题详解 1.计算1-100所有数据之和 all_num = ...
- 手写自定义springboot-starter,感受框架的魅力和原理
一.前言 Springboot的自动配置原理,面试中经常问到,一直看也记不住,不如手写一个starter,加深一下记忆. 看了之后发现大部分的starter都是这个原理,实践才会记忆深刻. 核心思想: ...