ElasticSearch必知必会-进阶篇
京东物流:康睿 姚再毅 李振 刘斌 王北永
说明:以下全部均基于elasticsearch8.1 版本
一.跨集群检索 - ccr
官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-cross-cluster-search.html
跨集群检索的背景和意义
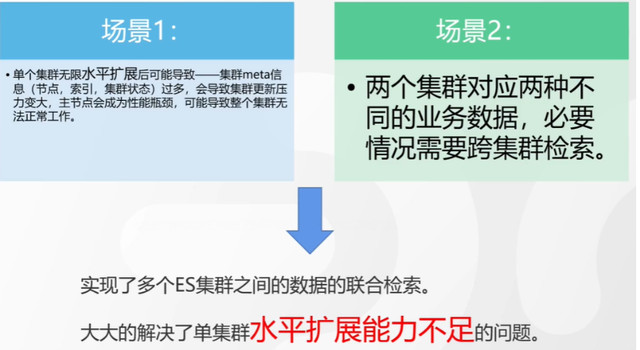
跨集群检索定义
跨集群检索环境搭建
官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-cross-cluster-search.html
步骤1:搭建两个本地单节点集群,本地练习可取消安全配置
步骤2:每个集群都执行以下命令
PUT _cluster/settings { "persistent": { "cluster": { "remote": { "cluster_one": { "seeds": [ "172.21.0.14:9301" ] },"cluster_two": { "seeds": [ "172.21.0.14:9302" ] } } } } }
步骤3:验证集群之间是否互通
方案1:Kibana 可视化查看:stack Management -> Remote Clusters -> status 应该是 connected! 且必须打上绿色的对号。
方案2:GET _remote/info
跨集群查询演练
# 步骤1 在集群 1 中添加数据如下
PUT test01/_bulk
{"index":{"_id":1}}
{"title":"this is from cluster01..."}
# 步骤2 在集群 2 中添加数据如下:
PUT test01/_bulk
{"index":{"_id":1}}
{"title":"this is from cluster02..."}
# 步骤 3:执行跨集群检索如下: 语法:POST 集群名称1:索引名称,集群名称2:索引名称/_search
POST cluster_one:test01,cluster_two:test01/_search
{
"took" : 7,
"timed_out" : false,
"num_reduce_phases" : 3,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"_clusters" : {
"total" : 2,
"successful" : 2,
"skipped" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "cluster_two:test01",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "this is from cluster02..."
}
},
{
"_index" : "cluster_one:test01",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "this is from cluster01..."
}
}
]
}
}
二.跨集群复制 - ccs - 该功能需付费
官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/current/xpack-ccr.html
如何保障集群的高可用
- 副本机制
- 快照和恢复
- 跨集群复制(类似mysql 主从同步)
跨集群复制概述

跨集群复制配置
- 准备两个集群,网络互通
- 开启 license 使用,可试用30天
- 开启位置:Stack Management -> License mangement.
3.定义好谁是Leads集群,谁是follower集群
4.在follower集群配置Leader集群
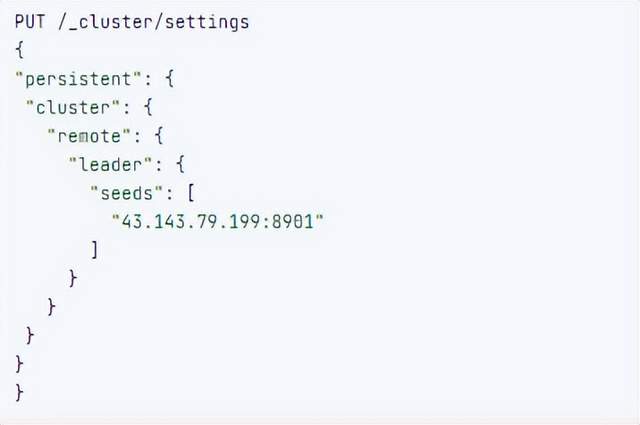
5.在follower集群配置Leader集群的索引同步规则(kibana页面配置)
a.stack Management -> Cross Cluster Replication -> create a follower index.
6.启用步骤5的配置
三索引模板
官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-templates.html
8.X之组件模板
1.创建组件模板-索引setting相关
# 组件模板 - 索引setting相关
PUT _component_template/template_sttting_part
{
"template": {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
}
}
}
2.创建组件模板-索引mapping相关
# 组件模板 - 索引mapping相关
PUT _component_template/template_mapping_part
{
"template": {
"mappings": {
"properties": {
"hosr_name":{
"type": "keyword"
},
"cratet_at":{
"type": "date",
"format": "EEE MMM dd HH:mm:ss Z yyyy"
}
}
}
}
}
3.创建组件模板-配置模板和索引之间的关联
// **注意:composed_of 如果多个组件模板中的配置项有重复,后面的会覆盖前面的,和配置的顺序有关**
# 基于组件模板,配置模板和索引之间的关联
# 也就是所有 tem_* 该表达式相关的索引创建时,都会使用到以下规则
PUT _index_template/template_1
{
"index_patterns": [
"tem_*"
],
"composed_of": [
"template_sttting_part",
"template_mapping_part"
]
}
4.测试
# 创建测试
PUT tem_001
索引模板基本操作

实战演练
需求1:默认如果不显式指定Mapping,数值类型会被动态映射为long类型,但实际上业务数值都比较小,会存在存储浪费。需要将默认值指定为Integer
索引模板,官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-templates.html
mapping-动态模板,官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/dynamic-templates.html
# 结合mapping 动态模板 和 索引模板
# 1.创建组件模板之 - mapping模板
PUT _component_template/template_mapping_part_01
{
"template": {
"mappings": {
"dynamic_templates": [
{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
}
]
}
}
}
# 2. 创建组件模板与索引关联配置
PUT _index_template/template_2
{
"index_patterns": ["tem1_*"],
"composed_of": ["template_mapping_part_01"]
}
# 3.创建测试数据
POST tem1_001/_doc/1
{
"age":18
}
# 4.查看mapping结构验证
get tem1_001/_mapping
需求2:date_*开头的字段,统一匹配为date日期类型。
索引模板,官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-templates.html
mapping-动态模板,官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/dynamic-templates.html
# 结合mapping 动态模板 和 索引模板
# 1.创建组件模板之 - mapping模板
PUT _component_template/template_mapping_part_01
{
"template": {
"mappings": {
"dynamic_templates": [
{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
},
{
"date_type_process": {
"match": "date_*",
"mapping": {
"type": "date",
"format":"yyyy-MM-dd HH:mm:ss"
}
}
}
]
}
}
}
# 2. 创建组件模板与索引关联配置
PUT _index_template/template_2
{
"index_patterns": ["tem1_*"],
"composed_of": ["template_mapping_part_01"]
}
# 3.创建测试数据
POST tem1_001/_doc/2
{
"age":19,
"date_aoe":"2022-01-01 18:18:00"
}
# 4.查看mapping结构验证
get tem1_001/_mapping
四.LIM 索引生命周期管理
官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-lifecycle-management.html
什么是索引生命周期
索引的 生-> 老 -> 病 -> 死
是否有过考虑,如果一个索引,创建之后,就不再去管理了?会发生什么?
什么是索引生命周期管理
索引太大了会如何?
大索引的恢复时间,要远比小索引恢复慢的多的多索引大了以后,检索会很慢,写入和更新也会受到不同程度的影响索引大到一定程度,当索引出现健康问题,会导致整个集群核心业务不可用
最佳实践
集群的单个分片最大文档数上限:2的32次幂减1,即20亿左右官方建议:分片大小控制在30GB-50GB,若索引数据量无限增大,肯定会超过这个值
用户不关注全量
某些业务场景,业务更关注近期的数据,如近3天、近7天大索引会将全部历史数据汇集在一起,不利于这种场景的查询
索引生命周期管理的历史演变

LIM前奏 - rollover 滚动索引
官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-rollover.html
# 0.自测前提,lim生命周期rollover频率。默认10分钟
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "1s"
}
}
# 1. 创建索引,并指定别名
PUT test_index-0001
{
"aliases": {
"my-test-index-alias": {
"is_write_index": true
}
}
}
# 2.批量导入数据
PUT my-test-index-alias/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
{"index":{"_id":5}}
{"title":"testing 05"}
# 3.rollover 滚动规则配置
POST my-test-index-alias/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 5,
"max_primary_shard_size": "50gb"
}
}
# 4.在满足条件的前提下创建滚动索引
PUT my-test-index-alias/_bulk
{"index":{"_id":7}}
{"title":"testing 07"}
# 5.查询验证滚动是否成功
POST my-test-index-alias/_search
LIM前奏 - shrink 索引压缩
官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/ilm-shrink.html核心步骤:
1. 将数据全部迁移至一个独立的节点
2. 索引禁止写入
3. 方可进行压缩
# 1.准备测试数据
DELETE kibana_sample_data_logs_ext
PUT kibana_sample_data_logs_ext
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 0
}
}
POST _reindex
{
"source": {
"index": "kibana_sample_data_logs"
},
"dest": {
"index": "kibana_sample_data_logs_ext"
}
}
# 2.压缩前必要的条件设置
# number_of_replicas :压缩后副本为0
# index.routing.allocation.include._tier_preference 数据分片全部路由到hot节点
# "index.blocks.write 压缩后索引不再允许数据写入
PUT kibana_sample_data_logs_ext/_settings
{
"settings": {
"index.number_of_replicas": 0,
"index.routing.allocation.include._tier_preference": "data_hot",
"index.blocks.write": true
}
}
# 3.实施压缩
POST kibana_sample_data_logs_ext/_shrink/kibana_sample_data_logs_ext_shrink
{
"settings":{
"index.number_of_replicas": 0,
"index.number_of_shards": 1,
"index.codec":"best_compression"
},
"aliases":{
"kibana_sample_data_logs_alias":{}
}
}
LIM实战
全局认知建立 - 四大阶段
官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/overview-index-lifecycle-management.html
生命周期管理阶段(Policy):
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/ilm-index-lifecycle.html
Hot阶段(生)
Set priority
Unfollow
Rollover
Read-only
Shrink
Force Merge
Search snapshot
Warm阶段(老)
Set priority
Unfollow
Read-only
Allocate
migrate
Shirink
Force Merge
Cold阶段(病)
Search snapshot
Delete阶段(死)
delete
演练
1.创建policy
Hot阶段设置,rollover: max_age:3d,max_docs:5, max_size:50gb, 优先级:100
Warm阶段设置:min_age:15s , forcemerage段合并,热节点迁移到warm节点,副本数设置0,优先级:50
Cold阶段设置: min_age 30s, warm迁移到cold阶段
Delete阶段设置:min_age 45s,执行删除操作
PUT _ilm/policy/kr_20221114_policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 100
},
"rollover": {
"max_size": "50gb",
"max_primary_shard_size": "50gb",
"max_age": "3d",
"max_docs": 5
}
}
},
"warm": {
"min_age": "15s",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"set_priority": {
"priority": 50
},
"allocate": {
"number_of_replicas": 0
}
}
},
"cold": {
"min_age": "30s",
"actions": {
"set_priority": {
"priority": 0
}
}
},
"delete": {
"min_age": "45s",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}

2.创建index template
PUT _index_template/kr_20221114_template
{
"index_patterns": ["kr_index-**"],
"template": {
"settings": {
"index": {
"lifecycle": {
"name": "kr_20221114_policy",
"rollover_alias": "kr-index-alias"
},
"routing": {
"allocation": {
"include": {
"_tier_preference": "data-hot"
}
}
},
"number_of_shards": "3",
"number_of_replicas": "1"
}
},
"aliases": {},
"mappings": {}
}
}
3.测试需要修改lim rollover刷新频率
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "1s"
}
}
4.进行测试
# 创建索引,并制定可写别名
PUT kr_index-0001
{
"aliases": {
"kr-index-alias": {
"is_write_index": true
}
}
}
# 通过别名新增数据
PUT kr-index-alias/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
{"index":{"_id":5}}
{"title":"testing 05"}
# 通过别名新增数据,触发rollover
PUT kr-index-alias/_bulk
{"index":{"_id":6}}
{"title":"testing 06"}
# 查看索引情况
GET kr_index-0001
get _cat/indices?v
过程总结
第一步:配置 lim pollicy
横向:Phrase 阶段(Hot、Warm、Cold、Delete) 生老病死
纵向:Action 操作(rollover、forcemerge、readlyonly、delete)
第二步:创建模板 绑定policy,指定别名
第三步:创建起始索引
第四步:索引基于第一步指定的policy进行滚动
五.Data Stream
官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/ilm-actions.html
特性解析
Data Stream让我们跨多个索引存储时序数据,同时给了唯一的对外接口(data stream名称)
写入和检索请求发给data stream
data stream将这些请求路由至 backing index(后台索引)

Backing indices
每个data stream由多个隐藏的后台索引构成
自动创建
要求模板索引
rollover 滚动索引机制用于自动生成后台索引
- 将成为data stream 新的写入索引
应用场景
- 日志、事件、指标等其他持续创建(少更新)的业务数据
- 两大核心特点
- 时序性数据
- 数据极少更新或没有更新
创建Data Stream 核心步骤

官网文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/set-up-a-data-stream.html
Set up a data stream
To set up a data stream, follow these steps:
- Create an index lifecycle policy
- Create component templates
- Create an index template
- Create the data stream
- Secure the data stream
演练
1. 创建一个data stream,名称为my-data-stream
2. index_template 名称为 my-index-template
3. 满足index格式【"my-data-stream*"】的索引都要被应用到
4. 数据插入的时候,在data_hot节点
5. 过3分钟之后要rollover到data_warm节点
6. 再过5分钟要到data_cold节点
# 步骤1 。创建 lim policy
PUT _ilm/policy/my-lifecycle-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50gb",
"max_age": "3m",
"max_docs": 5
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "5m",
"actions": {
"allocate": {
"number_of_replicas": 0
},
"forcemerge": {
"max_num_segments": 1
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "6m",
"actions": {
"freeze":{}
}
},
"delete": {
"min_age": "45s",
"actions": {
"delete": {}
}
}
}
}
}
# 步骤2 创建组件模板 - mapping
PUT _component_template/my-mappings
{
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date",
"format": "date_optional_time||epoch_millis"
},
"message": {
"type": "wildcard"
}
}
}
},
"_meta": {
"description": "Mappings for @timestamp and message fields",
"my-custom-meta-field": "More arbitrary metadata"
}
}
# 步骤3 创建组件模板 - setting
PUT _component_template/my-settings
{
"template": {
"settings": {
"index.lifecycle.name": "my-lifecycle-policy",
"index.routing.allocation.include._tier_preference":"data_hot"
}
},
"_meta": {
"description": "Settings for ILM",
"my-custom-meta-field": "More arbitrary metadata"
}
}
# 步骤4 创建索引模板
PUT _index_template/my-index-template
{
"index_patterns": ["my-data-stream*"],
"data_stream": { },
"composed_of": [ "my-mappings", "my-settings" ],
"priority": 500,
"_meta": {
"description": "Template for my time series data",
"my-custom-meta-field": "More arbitrary metadata"
}
}
# 步骤5 创建 data stream 并 写入数据测试
PUT my-data-stream/_bulk
{ "create":{ } }
{ "@timestamp": "2099-05-06T16:21:15.000Z", "message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736" }
{ "create":{ } }
{ "@timestamp": "2099-05-06T16:25:42.000Z", "message": "192.0.2.255 - - [06/May/2099:16:25:42 +0000] \"GET /favicon.ico HTTP/1.0\" 200 3638" }
POST my-data-stream/_doc
{
"@timestamp": "2099-05-06T16:21:15.000Z",
"message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"
}
# 步骤6 查看data stream 后台索引信息
GET /_resolve/index/my-data-stream*
ElasticSearch必知必会-进阶篇的更多相关文章
- Elasticsearch必知必会的干货知识二:ES索引操作技巧
该系列上一篇文章<Elasticsearch必知必会的干货知识一:ES索引文档的CRUD> 讲了如何进行index的增删改查,本篇则侧重讲解说明如何对index进行创建.更改.迁移.查询配 ...
- Elasticsearch必知必会的干货知识一:ES索引文档的CRUD
若在传统DBMS 关系型数据库中查询海量数据,特别是模糊查询,一般我们都是使用like %查询的值%,但这样会导致无法应用索引,从而形成全表扫描效率低下,即使是在有索引的字段精确值查找,面对海量数 ...
- Django框架之第六篇(模型层)--单表查询和必知必会13条、单表查询之双下划线、Django ORM常用字段和参数、关系字段
单表查询 补充一个知识点:在models.py建表是 create_time = models.DateField() 关键字参数: 1.auto_now:每次操作数据,都会自动刷新当前操作的时间 2 ...
- .NET程序员项目开发必知必会—Dev环境中的集成测试用例执行时上下文环境检查(实战)
Microsoft.NET 解决方案,项目开发必知必会. 从这篇文章开始我将分享一系列我认为在实际工作中很有必要的一些.NET项目开发的核心技术点,所以我称为必知必会.尽管这一系列是使用.NET/C# ...
- 2015 前端[JS]工程师必知必会
2015 前端[JS]工程师必知必会 本文摘自:http://zhuanlan.zhihu.com/FrontendMagazine/20002850 ,因为好东东西暂时没看懂,所以暂时保留下来,供以 ...
- [ 学习路线 ] 2015 前端(JS)工程师必知必会 (2)
http://segmentfault.com/a/1190000002678515?utm_source=Weibo&utm_medium=shareLink&utm_campaig ...
- 《MySQL必知必会》[01] 基本查询
<MySQL必知必会>(点击查看详情) 1.写在前面的话 这本书是一本MySQL的经典入门书籍,小小的一本,也受到众多网友推荐.之前自己学习的时候是啃的清华大学出版社的计算机系列教材< ...
- 《SQL必知必会》学习笔记二)
<SQL必知必会>学习笔记(二) 咱们接着上一篇的内容继续.这一篇主要回顾子查询,联合查询,复制表这三类内容. 上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语 ...
- 关于TCP/IP,必知必会的十个经典问题[转]
关于TCP/IP,必知必会的十个问题 原创 2018-01-25 Ruheng 技术特工队 本文整理了一些TCP/IP协议簇中需要必知必会的十大问题,既是面试高频问题,又是程序员必备基础素养. 一 ...
- Android程序员必知必会的网络通信传输层协议——UDP和TCP
1.点评 互联网发展至今已经高度发达,而对于互联网应用(尤其即时通讯技术这一块)的开发者来说,网络编程是基础中的基础,只有更好地理解相关基础知识,对于应用层的开发才能做到游刃有余. 对于Android ...
随机推荐
- 齐博x1第三季《模板风格的制作》系列009-自定义区块代码
本节来说明如何自定义区块代码,不再继承上层模板,实现个性模板 上一节因为我们继承了layout布局模版,所以我们自定义的代码就无效了 如果我们继承了上层模板,那么相当于我们复制了一份上层模板的结构,也 ...
- 《Java并发编程的艺术》读书笔记:一、并发编程的目的与挑战
发现自己有很多读书笔记了,但是一直都是自己闷头背,没有输出,突然想起还有博客圆这么个好平台给我留着位置,可不能荒废了. 此文读的书是<Jvava并发编程的艺术>,方腾飞等著,非常经典的一本 ...
- 使用 nvm 对 node 进行版本管理
前端项目工程化,基本都依赖于 nodejs, 不同的项目对于 nodejs 的版本会有要求,nvm 就是可以让我们在各个版本之间进行快速切换的工具. Linux 系统 下载解压 查看所有版本 , 选择 ...
- 四、Django中使用celery
项目跟目录创建celery包,目录结构如下: mycelery/ ├── config.py ├── __init__.py ├── main.py └── sms/ ├── __init__.py ...
- nginx 客户端返回499的错误码
我们服务器客户端一直有返回错误码499的日志,以前觉得比例不高,就没有仔细查过,最近有领导问这个问题,为什么耗时只有0.0几秒,为啥还499了?最近几天就把这个问题跟踪定位了一下,这里做个记录 网络架 ...
- 从ObjectPool到CAS指令
相信最近看过我的文章的朋友对于Microsoft.Extensions.ObjectPool不陌生:复用.池化是在很多高性能场景的优化技巧,它能减少内存占用率.降低GC频率.提升系统TPS和降低请求时 ...
- R数据分析:孟德尔随机化实操
好多同学询问孟德尔随机化的问题,我再来尝试着梳理一遍,希望对大家有所帮助,首先看下图1分钟,盯着看将下图印在脑海中: 上图是工具变量(不知道工具变量请翻之前的文章)的模式图,明确一个点:我们做孟德尔的 ...
- 第2-3-3章 文件处理策略-文件存储服务系统-nginx/fastDFS/minio/阿里云oss/七牛云oss
目录 5.2 文件处理策略 5.2.1 FileStrategy 5.2.2 AbstractFileStrategy 5.2.3 LocalServiceImpl 5.2.4 FastDfsServ ...
- PHP使用PHPmailer类和smtp发送邮件
开启邮件smtp服务 设置授权码 引入phpmailer类,smtp类本地下载https://github.com/PHPMailer/PHPMailer //下载PHPMailer并开启php_op ...
- 顺序表代码总结——SqList
在C++编译器下可直接运行 #include <stdio.h> #include <stdlib.h> #include <malloc.h> //顺序表存储结构 ...