Hadoop详解(01)-概论
Hadoop详解(01)概论
概念
大数据(Big Data):指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。主要解决,海量数据的存储和海量数据的分析计算问题。截至目前,人类生产的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB。当前,典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级。
数据存储单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB。
特点
- Volume(大量
截至目前,人类生产的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB。当前,典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级。
- Velocity(高速)
这是大数据区分于传统数据挖掘的最显著特征。根据IDC的"数字宇宙"的报告,预计到2025年,全球数据使用量将达到163ZB。在如此海量的数据面前,处理数据的效率就是企业的生命。
例如:
天猫双十一2017年3分01秒,天猫交易额超过100亿,2019年1分36秒,天猫交易额超过100亿
- Variety(多样)
这种类型的多样性也让数据被分为结构化数据和非结构化数据。相对于以往便于存储的以数据库/文本为主的结构化数据,非结构化数据越来越多,包括网络日志、音频、视频、图片、地理位置信息等,这些多类型的数据对数据的处理能力提出了更高要求。
- Value(低价值密度)
价值密度的高低与数据总量的大小成反比。比如,在一天监控视频中,往往只关心宋宋老师晚上在床上健身那一分钟,如何快速对有价值数据"提纯"成为目前大数据背景下待解决的难题。
应用场景
1、物流仓储:大数据分析系统助力商家精细化运营、提升销量、节约成本。例如京东物流:上午下单下午送达、下午下单次日上午送达
2、零售:分析用户消费习惯,为用户购买商品提供方便,从而提升商品销量。经典案例,纸尿布+啤酒。
3、旅游:深度结合大数据能力与旅游行业需求,共建旅游产业智慧管理、智慧服务和智慧营销的未来。
4、商品广告推荐:给用户推荐可能喜欢的商品
5、保险:海量数据挖掘及风险预测,助力保险行业精准营销,提升精细化定价能力。
6、金融:多维度体现用户特征,帮助金融机构推荐优质客户,防范欺诈风险。
7、房产:大数据全面助力房地产行业,打造精准投策与营销,选出更合适的地,建造更合适的楼,卖给更合适的人。
8、人工智能等
发展前景
1、党的十八大提出"实施国家大数据战略",国务院印发《促进大数据发展行动纲要》,大数据技术和应用处于创新突破期,国内市场需求处于爆发期,我国大数据产业面临重要的发展机遇。
2、党的十九大提出"推动互联网、大数据、人工智能和实体经济深度融合"。
3、国际数据公司IDC预测,到2020年,企业基于大数据计算分析平台的支出将突破5000亿美元。目前,我国大数据人才只有46万,未来3到5年人才缺口达150万之多。
4、2017年北京大学、中国人民大学、北京邮电大学等25所高校成功申请开设大数据课程。
5、大数据属于高新技术,大牛少,升职竞争小;
6、在北京大数据开发工程师的平均薪水已经到24060元(数据统计来职友集),而且目前还保持强劲的发展势头。
7、某招聘网站上的大数据工程师薪水如下
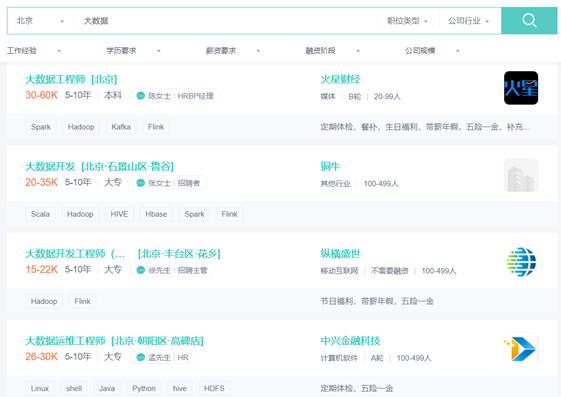
大数据部门组织结构
Hadoop生态
Hadoop是什么
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
Hadoop生态圈
Hadoop发展历史
1)Lucene框架是Doug Cutting开创的开源软件,用Java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎。
2)2001年年底Lucene成为Apache基金会的一个子项目。
3)对于海量数据的场景,Lucene面对与Google同样的困难,存储数据困难,检索速度慢。
4)学习和模仿Google解决这些问题的办法 :微型版Nutch。
5)可以说Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
- GFS --->HDFS
- Map-Reduce --->MR
- BigTable --->HBase
6)2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。
7)2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。
8)2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS) 分别被纳入到 Hadoop 项目中,Hadoop就此正式诞生,标志着大数据时代来临。
9)名字来源于Doug Cutting儿子的玩具大象,如图2-20。

Hadoop三大发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera内部集成了很多大数据框架。对应产品CDH。
Hortonworks文档较好。对应产品HDP。
1)Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/
2)Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。Cloudera的标价为每年每个节点10000美元。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。
3)Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(4)Hortonworks目前已经被Cloudera公司收购。
Hadoop的优势
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:能够自动将失败的任务重新分配。
Hadoop组成
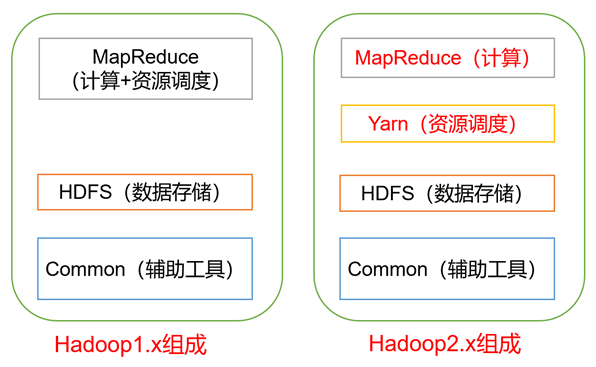
在Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大,在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度,MapReduce只负责运算。
HDFS架构
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验。
3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
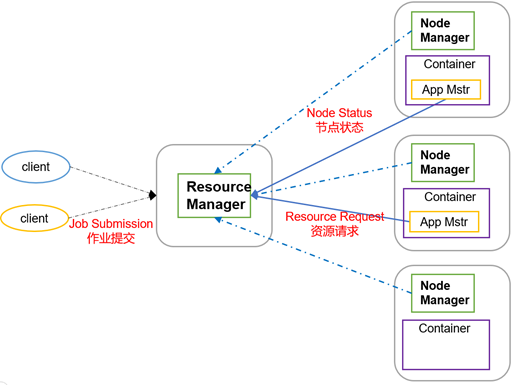
YARN架构
1)ResourceManager(RM)主要作用如下
- 处理客户端请求
- 监控NodeManager
- 启动或监控ApplicationMaster
- 资源的分配与调度
2)NodeManager(NM)主要作用如下
- 管理单个节点上的资源
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
3)ApplicationMaster(AM)作用如下
- 负责数据的切分
- 为应用程序申请资源并分配给内部的任务
- 任务的监控与容错
4)Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。
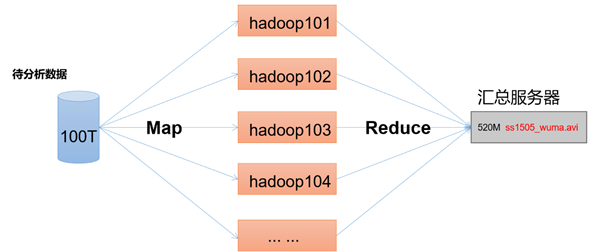
MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
大数据技术生态体系
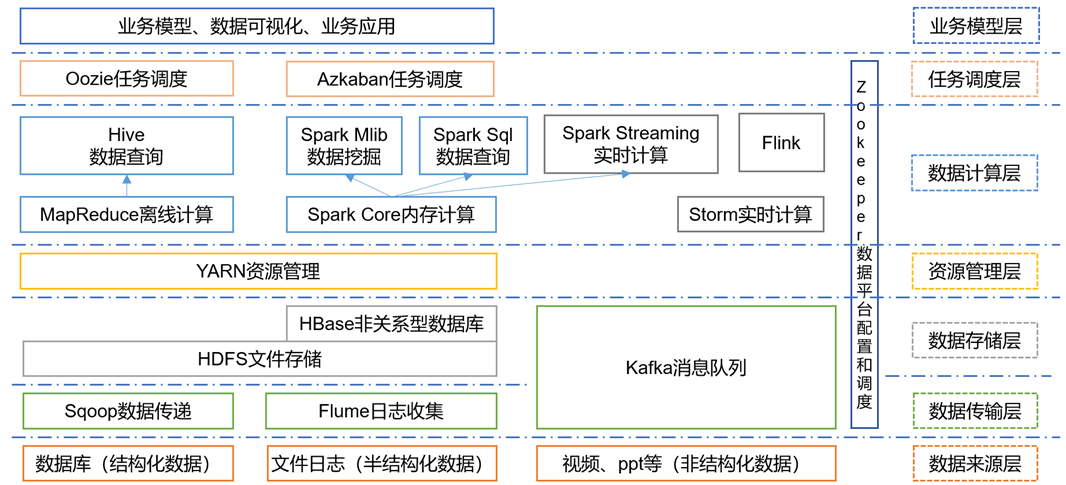
图中涉及的技术名词解释如下:
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统;
4)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
5)Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
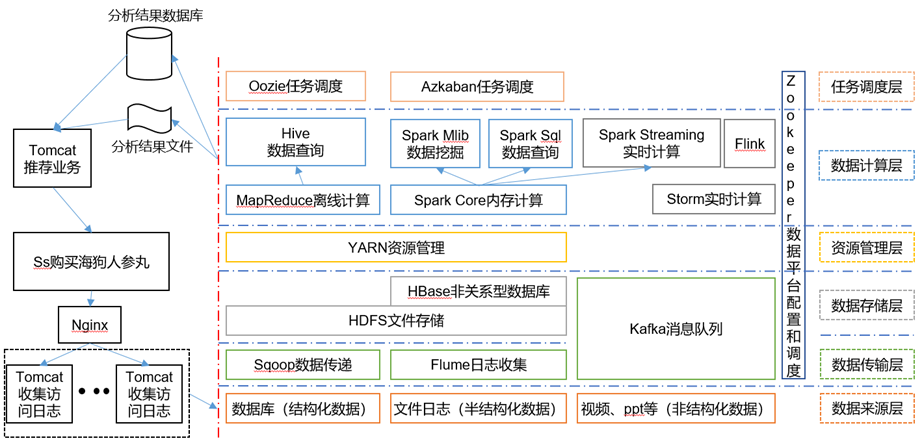
推荐系统框架图
Hadoop详解(01)-概论的更多相关文章
- [Big Data]Hadoop详解一
从数据爆炸开始... 一. 第三次工业革命 第一次:18世纪60年代,手工工厂向机器大生产过渡,以蒸汽机的发明和使用为标志. 第二次:19世纪70年代,各种新技术新发明不断被应 ...
- Hadoop详解一:Hadoop简介
从数据爆炸开始... 一. 第三次工业革命 第一次:18世纪60年代,手工工厂向机器大生产过渡,以蒸汽机的发明和使用为标志. 第二次:19世纪70年代,各种新技术新发明不断被应 ...
- 21个项目玩转深度学习:基于TensorFlow的实践详解01—MNIST机器学习入门
数据集 由Yann Le Cun建立,训练集55000,验证集5000,测试集10000,图片大小均为28*28 下载 # coding:utf-8 # 从tensorflow.examples.tu ...
- 小甲鱼PE详解之IMAGE_DOS_HEADER结构定义即各个属性的作用(PE详解01)
(注:最左边是文件头的偏移量.) IMAGE_DOS_HEADER STRUCT { +0h WORD e_magic // Magic DOS signature MZ(4Dh 5Ah) ...
- (Go)07.Go语言中strings和strconv包示例代码详解01
1.strings使用 前缀和后缀 HasPrefix判断字符串s是否以prefix开头: 示例: package main import ( "fmt" "string ...
- IO模型(epoll)--详解-01
写在前面 从事服务端开发,少不了要接触网络编程.epoll作为linux下高性能网络服务器的必备技术至关重要,nginx.redis.skynet和大部分游戏服务器都使用到这一多路复用技术. 本文会从 ...
- Spark框架详解
一.引言 作者:Albert陈凯链接:https://www.jianshu.com/p/f3181afec605來源:简书 Introduction 本文主要讨论 Apache Spark 的设计与 ...
- winxp计算机管理中服务详解
winxp计算机管理中服务详解01 http://blog.sina.com.cn/s/blog_60f923b50100efy9.html http://blog.sina.com.cn/s/blo ...
- yum的配置文件yum.conf详解
说明:经过网上抄袭和自己的总结加实验,非常详细,可留作参考. yum的配置一般有两种方式: 一种是直接配置/etc目录下的yum.conf文件, 另外一种是在/etc/yum.repos.d目录下 ...
- sso单点登录原理详解
sso单点登录原理详解 01 单系统登录机制 1.http无状态协议 web应用采用browser/server架构,http作为通信协议.http是无状态协议,浏览器的每一次请求,服务 ...
随机推荐
- GitHub 供应链安全已支持 Dart 开发者生态
通过 Dart 和 GitHub 团队的共同努力,自 10 月 7 日起,GitHub 的 Advisory Database (安全咨询数据库).Dependency Graph (依赖项关系图) ...
- Oracle索引和事务
1. 什么是索引?有什么用? 1)索引是数据库对象之一,用于加快数据的检索,类似于书籍的目录.在数据库中索引可以减少数据库程序查询结果时需要读取的数据量,类似于在书籍中我们利用索引可以不用翻阅整本书即 ...
- 驱动开发:内核测试模式过DSE签名
微软在x64系统中推出了DSE保护机制,DSE全称(Driver Signature Enforcement),该保护机制的核心就是任何驱动程序或者是第三方驱动如果想要在正常模式下被加载则必须要经过微 ...
- go-zero docker-compose搭建课件服务(四):生成Dockerfile
0.转载 go-zero docker-compose 搭建课件服务(四):生成Dockerfile并在docker-compose中启动 0.1源码地址 https://github.com/liu ...
- vue中push()和splice()的使用方法
vue中push()和splice()的使用方法 push()使用 push() 方法可向数组的末尾添加一个或多个元素,并返回新的长度.注意:1. 新元素将添加在数组的末尾. 2.此方法改变数组的长度 ...
- 一键部署haproxy脚本
HAPROXY_VERSION=2.6.6 HAPROXY_FILE=haproxy-${HAPROXY_VERSION}.tar.gz #HAPROXY_FILE=haproxy-2.2.12.ta ...
- C/C++ 知海拾遗
C语言知识拾遗 2022/11/11 memset()函数用法 包含头文件:<string.h> 作用:给任意类型变量数组初始化,即万能初始化函数. 使用形式:memset( void* ...
- 【翻译】Spring Security抛弃了WebSecurityConfigurerAdapter
原文链接:Spring Security without the WebSecurityConfigurerAdapter 作者:ELEFTHERIA STEIN-KOUSATHANA 发表日期:20 ...
- python——os模块学习
import os #1.获取当前使用的操作系统 #返回操作系统类型,nt是windows,posix是linux print(os.name) #print是一个函数,函数里面进行条件判断'posi ...
- 【RPC和Protobuf】之RPC入门
一,概念 RPC:Remote procedure call(远程过程调用),分布式系统中不同节点之间流行的通信方式 服务端: 注: 1.执行下面的代码之后,会相应的启动一个tcp进程 C:\User ...