浅析Kubernetes架构之workqueue
通用队列
在kubernetes中,使用go的channel无法满足kubernetes的应用场景,如延迟、限速等;在kubernetes中存在三种队列通用队列 common queue ,延迟队列 delaying queue,和限速队列 rate limiters queue
Inferface
Interface作为所有队列的一个抽象定义
type Interface interface {
Add(item interface{})
Len() int
Get() (item interface{}, shutdown bool)
Done(item interface{})
ShutDown()
ShuttingDown() bool
}
Implementation
type Type struct { // 一个work queue
queue []t // queue用slice做存储
dirty set // 脏位,定义了需要处理的元素,类似于操作系统,表示已修改但为写入
processing set // 当前正在处理的元素集合
cond *sync.Cond
shuttingDown bool
metrics queueMetrics
unfinishedWorkUpdatePeriod time.Duration
clock clock.Clock
}
type empty struct{}
type t interface{} // t queue中的元素
type set map[t]empty // dirty 和 processing中的元素
可以看到其中核心属性就是 queue , dirty , processing
延迟队列
在研究优先级队列前,需要对 Heap 有一定的了解,因为delay queue使用了 heap 做延迟队列
Heap
Heap 是基于树属性的特殊数据结构;heap是一种完全二叉树类型,具有两种类型:
- 如:B 是 A 的子节点,则 \(key(A) \geq key(B)\) 。这就意味着具有最大Key的元素始终位于根节点,这类Heap称为最大堆 MaxHeap。
- 父节点的值小于或等于其左右子节点的值叫做 MinHeap
二叉堆的存储规则:
- 每个节点包含的元素大于或等于该节点子节点的元素。
- 树是完全二叉树。
那么下列图片中,那个是堆
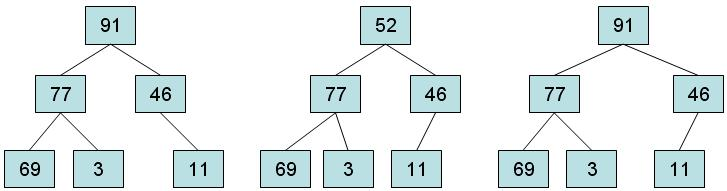
heap的实现
实例:向左边添加一个值为42的元素的过程
步骤一:将新元素放入堆中的第一个可用位置。这将使结构保持为完整的二叉树,但它可能不再是堆,因为新元素可能具有比其父元素更大的值。
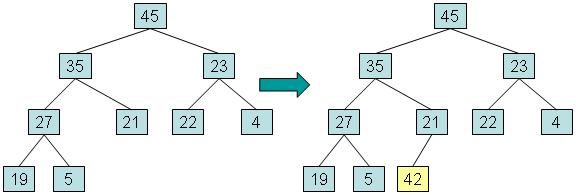
步骤二:如果新元素的值大于父元素,将新元素与父元素交换,直到达到新元素到根,或者新元素大于等于其父元素的值时将停止
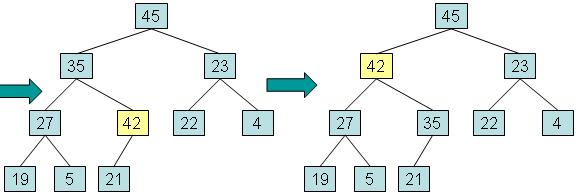
这种过程被称为 向上调整 (reheapification upward)
实例:移除根
步骤一:将根元素复制到用于返回值的变量中,将最深层的最后一个元素复制到根,然后将最后一个节点从树中取出。该元素称为 out-of-place 。
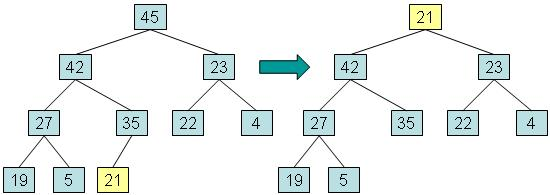
步骤二:而将异位元素与其最大值的子元素交换,并返回在步骤1中保存的值。
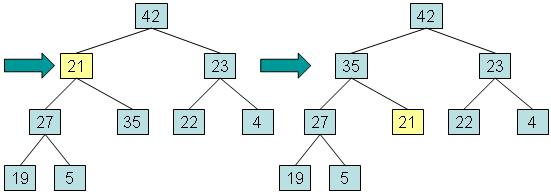
这个过程被称为向下调整 (reheapification downward)
优先级队列
优先级队列的行为:
- 元素被放置在队列中,然后被取出。
- 优先级队列中的每个元素都有一个关联的数字,称为优先级。
- 当元素离开优先级队列时,最高优先级的元素最先离开。
如何实现的:
在优先级队列中,heap的每个节点都包含一个元素以及元素的优先级,并且维护树以便它遵循使用元素的优先级来比较节点的堆存储规则:
- 每个节点包含的元素的优先级大于或等于该节点子元素的优先级。
- 树是完全二叉树。
实现的代码:golang priorityQueue
Reference
Client-go 的延迟队列
在Kubernetes中对 delaying queue 的设计非常精美,通过使用 heap 实现的延迟队列,加上kubernetes中的通过队列,完成了延迟队列的功能。
// 注释中给了一个hot-loop热循环,通过这个loop实现了delaying
type DelayingInterface interface {
Interface // 继承了workqueue的功能
AddAfter(item interface{}, duration time.Duration) // 在time后将内容添加到工作队列中
}
具体实现了 DelayingInterface 的实例
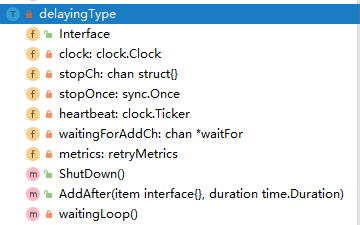
type delayingType struct {
Interface // 通用的queue
clock clock.Clock // 对比的时间 ,包含一些定时器的功能
type Clock interface {
PassiveClock
type PassiveClock interface {
Now() time.Time
Since(time.Time) time.Duration
}
After(time.Duration) <-chan time.Time
NewTimer(time.Duration) Timer
Sleep(time.Duration)
NewTicker(time.Duration) Ticker
}
stopCh chan struct{} // 停止loop
stopOnce sync.Once // 保证退出只会触发一次
heartbeat clock.Ticker // 一个定时器,保证了loop的最大空事件等待时间
waitingForAddCh chan *waitFor // 普通的chan,用来接收数据插入到延迟队列中
metrics retryMetrics // 重试的指数
}
那么延迟队列的整个数据结构如下图所示
而上面部分也说到了,这个延迟队列的核心就是一个优先级队列,而优先级队列又需要满足:
- 优先级队列中的每个元素都有一个关联的数字,称为优先级。
- 当元素离开优先级队列时,最高优先级的元素最先离开。
而 waitFor 就是这个优先级队列的数据结构
type waitFor struct {
data t // 数据
readyAt time.Time // 加入工作队列的时间
index int // 优先级队列中的索引
}
而 waitForPriorityQueue 是对 container/heap/heap.go.Inferface 的实现,其数据结构就是使最小 readyAt 位于Root 的一个 MinHeap
type Interface interface {
sort.Interface
Push(x interface{}) // add x as element Len()
Pop() interface{} // remove and return element Len() - 1.
}
而这个的实现是 waitForPriorityQueue
type waitForPriorityQueue []*waitFor
func (pq waitForPriorityQueue) Len() int {
return len(pq)
}
// 这个也是最重要的一个,就是哪个属性是排序的关键,也是heap.down和heap.up中使用的
func (pq waitForPriorityQueue) Less(i, j int) bool {
return pq[i].readyAt.Before(pq[j].readyAt)
}
func (pq waitForPriorityQueue) Swap(i, j int) {
pq[i], pq[j] = pq[j], pq[i]
pq[i].index = i
pq[j].index = j
}
// push 和pop 必须使用heap.push 和heap.pop
func (pq *waitForPriorityQueue) Push(x interface{}) {
n := len(*pq)
item := x.(*waitFor)
item.index = n
*pq = append(*pq, item)
}
func (pq *waitForPriorityQueue) Pop() interface{} {
n := len(*pq)
item := (*pq)[n-1]
item.index = -1
*pq = (*pq)[0:(n - 1)]
return item
}
// Peek returns the item at the beginning of the queue, without removing the
// item or otherwise mutating the queue. It is safe to call directly.
func (pq waitForPriorityQueue) Peek() interface{} {
return pq[0]
}
而整个延迟队列的核心就是 waitingLoop,作为了延迟队列的主要逻辑,检查 waitingForAddCh 有没有要延迟的内容,取出延迟的内容放置到 Heap 中;以及保证最大的阻塞周期
func (q *delayingType) waitingLoop() {
defer utilruntime.HandleCrash()
never := make(<-chan time.Time) // 作为占位符
var nextReadyAtTimer clock.Timer // 最近一个任务要执行的定时器
waitingForQueue := &waitForPriorityQueue{} // 优先级队列,heap
heap.Init(waitingForQueue)
waitingEntryByData := map[t]*waitFor{} // 检查是否反复添加
for {
if q.Interface.ShuttingDown() {
return
}
now := q.clock.Now()
for waitingForQueue.Len() > 0 {
entry := waitingForQueue.Peek().(*waitFor)
if entry.readyAt.After(now) {
break // 时间没到则不处理
}
entry = heap.Pop(waitingForQueue).(*waitFor) // 从优先级队列中取出一个
q.Add(entry.data) // 添加到延迟队列中
delete(waitingEntryByData, entry.data) // 删除map表中的数据
}
// 如果存在数据则设置最近一个内容要执行的定时器
nextReadyAt := never
if waitingForQueue.Len() > 0 {
if nextReadyAtTimer != nil {
nextReadyAtTimer.Stop()
}
entry := waitingForQueue.Peek().(*waitFor) // 窥视[0]和值
nextReadyAtTimer = q.clock.NewTimer(entry.readyAt.Sub(now)) // 创建一个定时器
nextReadyAt = nextReadyAtTimer.C()
}
select {
case <-q.stopCh: // 退出
return
case <-q.heartbeat.C(): // 多久没有任何动作时重新一次循环
case <-nextReadyAt: // 如果有元素时间到了,则继续执行循环,处理上面添加的操作
case waitEntry := <-q.waitingForAddCh:
if waitEntry.readyAt.After(q.clock.Now()) { // 时间没到,是用readyAt和now对比time.Now
// 添加到延迟队列中,有两个 waitingEntryByData waitingForQueue
insert(waitingForQueue, waitingEntryByData, waitEntry)
} else {
q.Add(waitEntry.data)
}
drained := false // 保证可以取完q.waitingForAddCh // addafter
for !drained {
select {
// 这里是一个有buffer的队列,需要保障这个队列读完
case waitEntry := <-q.waitingForAddCh:
if waitEntry.readyAt.After(q.clock.Now()) {
insert(waitingForQueue, waitingEntryByData, waitEntry)
} else {
q.Add(waitEntry.data)
}
default: // 保证可以退出,但限制于上一个分支的0~n的读取
// 如果上一个分支阻塞,则为没有数据就是取尽了,走到这个分支
// 如果上个分支不阻塞则读取到上个分支阻塞为止,代表阻塞,则走default退出
drained = true
}
}
}
}
}
限速队列
限速队列 RateLimiting 是在优先级队列是在延迟队列的基础上进行扩展的一个队列
type RateLimitingInterface interface {
DelayingInterface // 继承延迟队列
// 在限速器准备完成后(即合规后)添加条目到队列中
AddRateLimited(item interface{})
// drop掉条目,无论成功或失败
Forget(item interface{})
// 被重新放入队列中的次数
NumRequeues(item interface{}) int
}
可以看到一个限速队列的抽象对应只要满足了 AddRateLimited() , Forget() , NumRequeues() 的延迟队列都是限速队列。看了解规则之后,需要对具体的实现进行分析。
type rateLimitingType struct {
DelayingInterface
rateLimiter RateLimiter
}
func (q *rateLimitingType) AddRateLimited(item interface{}) {
q.DelayingInterface.AddAfter(item, q.rateLimiter.When(item))
}
func (q *rateLimitingType) NumRequeues(item interface{}) int {
return q.rateLimiter.NumRequeues(item)
}
func (q *rateLimitingType) Forget(item interface{}) {
q.rateLimiter.Forget(item)
}
rateLimitingType 则是对抽象规范 RateLimitingInterface 的实现,可以看出是在延迟队列的基础上增加了一个限速器 RateLimiter
type RateLimiter interface {
// when决定等待多长时间
When(item interface{}) time.Duration
// drop掉item
// or for success, we'll stop tracking it
Forget(item interface{})
// 重新加入队列中的次数
NumRequeues(item interface{}) int
}
抽象限速器的实现,有 BucketRateLimiter , ItemBucketRateLimiter , ItemExponentialFailureRateLimiter , ItemFastSlowRateLimiter , MaxOfRateLimiter ,下面对这些限速器进行分析
BucketRateLimiter
BucketRateLimiter 是实现 rate.Limiter 与 抽象 RateLimiter 的一个令牌桶,初始化时通过 workqueue.DefaultControllerRateLimiter() 进行初始化。
func DefaultControllerRateLimiter() RateLimiter {
return NewMaxOfRateLimiter(
NewItemExponentialFailureRateLimiter(5*time.Millisecond, 1000*time.Second),
// 10 qps, 100 bucket size. This is only for retry speed and its only the overall factor (not per item)
&BucketRateLimiter{Limiter: rate.NewLimiter(rate.Limit(10), 100)},
)
}
ItemBucketRateLimiter
ItemBucketRateLimiter 是作为列表存储每个令牌桶的实现,每个key都是单独的限速器
type ItemBucketRateLimiter struct {
r rate.Limit
burst int
limitersLock sync.Mutex
limiters map[interface{}]*rate.Limiter
}
func NewItemBucketRateLimiter(r rate.Limit, burst int) *ItemBucketRateLimiter {
return &ItemBucketRateLimiter{
r: r,
burst: burst,
limiters: make(map[interface{}]*rate.Limiter),
}
}
ItemExponentialFailureRateLimiter
如名所知 ItemExponentialFailureRateLimiter 限速器是一个错误指数限速器,根据错误的次数,将指数用于delay的时长,指数的计算公式为:\(baseDelay\times2^{<num-failures>}\)。 可以看出When绝定了流量整形的delay时间,根据错误次数为指数进行延长重试时间
type ItemExponentialFailureRateLimiter struct {
failuresLock sync.Mutex
failures map[interface{}]int // 失败的次数
baseDelay time.Duration // 延迟基数
maxDelay time.Duration // 最大延迟
}
func (r *ItemExponentialFailureRateLimiter) When(item interface{}) time.Duration {
r.failuresLock.Lock()
defer r.failuresLock.Unlock()
exp := r.failures[item]
r.failures[item] = r.failures[item] + 1
// The backoff is capped such that 'calculated' value never overflows.
backoff := float64(r.baseDelay.Nanoseconds()) * math.Pow(2, float64(exp))
if backoff > math.MaxInt64 {
return r.maxDelay
}
calculated := time.Duration(backoff)
if calculated > r.maxDelay {
return r.maxDelay
}
return calculated
}
func (r *ItemExponentialFailureRateLimiter) NumRequeues(item interface{}) int {
r.failuresLock.Lock()
defer r.failuresLock.Unlock()
return r.failures[item]
}
func (r *ItemExponentialFailureRateLimiter) Forget(item interface{}) {
r.failuresLock.Lock()
defer r.failuresLock.Unlock()
delete(r.failures, item)
}
ItemFastSlowRateLimiter
ItemFastSlowRateLimiter ,限速器先快速重试一定次数,然后慢速重试
type ItemFastSlowRateLimiter struct {
failuresLock sync.Mutex
failures map[interface{}]int
maxFastAttempts int // 最大尝试次数
fastDelay time.Duration // 快的速度
slowDelay time.Duration // 慢的速度
}
func NewItemFastSlowRateLimiter(fastDelay, slowDelay time.Duration, maxFastAttempts int) RateLimiter {
return &ItemFastSlowRateLimiter{
failures: map[interface{}]int{},
fastDelay: fastDelay,
slowDelay: slowDelay,
maxFastAttempts: maxFastAttempts,
}
}
func (r *ItemFastSlowRateLimiter) When(item interface{}) time.Duration {
r.failuresLock.Lock()
defer r.failuresLock.Unlock()
r.failures[item] = r.failures[item] + 1
// 当错误次数没超过快速的阈值使用快速,否则使用慢速
if r.failures[item] <= r.maxFastAttempts {
return r.fastDelay
}
return r.slowDelay
}
func (r *ItemFastSlowRateLimiter) NumRequeues(item interface{}) int {
r.failuresLock.Lock()
defer r.failuresLock.Unlock()
return r.failures[item]
}
func (r *ItemFastSlowRateLimiter) Forget(item interface{}) {
r.failuresLock.Lock()
defer r.failuresLock.Unlock()
delete(r.failures, item)
}
MaxOfRateLimiter
MaxOfRateLimiter 是返回限速器列表中,延迟最大的那个限速器
type MaxOfRateLimiter struct {
limiters []RateLimiter
}
func (r *MaxOfRateLimiter) When(item interface{}) time.Duration {
ret := time.Duration(0)
for _, limiter := range r.limiters {
curr := limiter.When(item)
if curr > ret {
ret = curr
}
}
return ret
}
func NewMaxOfRateLimiter(limiters ...RateLimiter) RateLimiter {
return &MaxOfRateLimiter{limiters: limiters}
}
func (r *MaxOfRateLimiter) NumRequeues(item interface{}) int {
ret := 0
// 找到列表內所有的NumRequeues(失败的次数),以最多次的为主。
for _, limiter := range r.limiters {
curr := limiter.NumRequeues(item)
if curr > ret {
ret = curr
}
}
return ret
}
func (r *MaxOfRateLimiter) Forget(item interface{}) {
for _, limiter := range r.limiters {
limiter.Forget(item)
}
}
如何使用Kubernetes的限速器
基于流量管制的限速队列实例,可以大量突发,但是需要进行整形,添加操作会根据 When() 中设计的需要等待的时间进行添加。根据不同的队列实现不同方式的延迟
package main
import (
"fmt"
"log"
"strconv"
"time"
"k8s.io/client-go/util/workqueue"
)
func main() {
stopCh := make(chan string)
timeLayout := "2006-01-02:15:04:05.0000"
limiter := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
length := 20 // 一共请求20次
chs := make([]chan string, length)
for i := 0; i < length; i++ {
chs[i] = make(chan string, 1)
go func(taskId string, ch chan string) {
item := "Task-" + taskId + time.Now().Format(timeLayout)
log.Println(item + " Added.")
limiter.AddRateLimited(item) // 添加会根据When() 延迟添加到工作队列中
}(strconv.FormatInt(int64(i), 10), chs[i])
go func() {
for {
key, quit := limiter.Get()
if quit {
return
}
log.Println(fmt.Sprintf("%s process done", key))
defer limiter.Done(key)
}
}()
}
<-stopCh
}
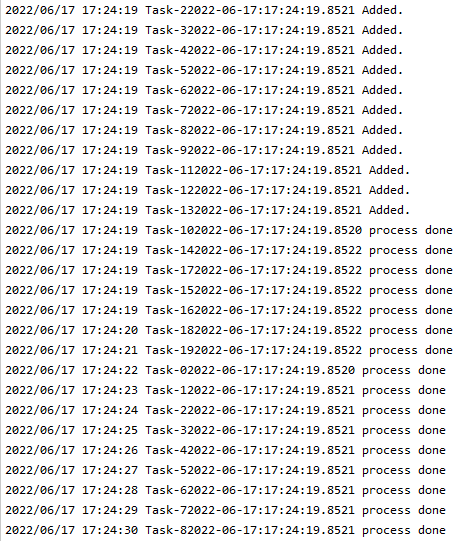
因为默认的限速器不支持初始化 QPS,修改源码内的为 \(BT(1, 5)\) ,执行结果可以看出,大突发流量时,超过桶内token数时,会根据token生成的速度进行放行。
图中,任务的添加是突发性的,日志打印的是同时添加,但是在添加前输出的日志,消费端可以看到实际是被延迟了。配置的是每秒一个token,实际上放行流量也是每秒一个token。
浅析Kubernetes架构之workqueue的更多相关文章
- Kubernetes 架构(下)- 每天5分钟玩转 Docker 容器技术(121)
上一节我们讨论了 Kubernetes 架构 Master 上运行的服务,本节讨论 Node 节点. Node 是 Pod 运行的地方,Kubernetes 支持 Docker.rkt 等容器 Run ...
- Kubernetes 架构(下)【转】
上一节我们讨论了 Kubernetes 架构 Master 上运行的服务,本节讨论 Node 节点. Node 是 Pod 运行的地方,Kubernetes 支持 Docker.rkt 等容器 Run ...
- 【Kubernetes 系列二】从虚拟机讲到 Kubernetes 架构
目录 什么是虚拟机? 什么是容器? Docker Kubernetes 架构 Kubernetes 对象 基础设施抽象 在认识 Kubernetes 之前,我们需了解下容器,在了解容器之前,我们得先知 ...
- K8S Kubernetes 架构
Kubernetes最初源于谷歌内部的Borg,提供了面向应用的容器集群部署和管理系统. Kubernetes架构 Kubernetes借鉴了Borg的设计理念,比如Pod.Service.Label ...
- kubernetes架构(2)
一.Kubernetes 架构: Kubernetes Cluster 由 Master 和 Node 组成,节点上运行着若干 Kubernetes 服务. Master 节点 Master 是 Ku ...
- Kubernetes架构
一.Kubernetes 架构: Kubernetes Cluster 由 Master 和 Node 组成,节点上运行着若干 Kubernetes 服务. 1. Master 节点 Master 是 ...
- 第2篇Kubernetes架构
一.Kubernetes 架构: Kubernetes Cluster 由 Master 和 Node 组成,节点上运行着若干 Kubernetes 服务. Master 节点 Master 是 ...
- Kubernetes架构介绍
目录 Kubernetes架构 k8s架构图 一.K8S Master节点 API Server Scheduler Controller Manager ETCD 二.K8S Node节点 Kube ...
- 代码 or 指令,浅析ARM架构下的函数的调用过程
摘要:linux程序运行的状态以及如何推导调用栈. 1.背景知识 1.ARM64寄存器介绍: 2.STP指令详解(ARMV8手册): 我们先看一下指令格式(64bit),以及指令对于寄存机执行结果的影 ...
随机推荐
- 爬虫---scrapy分布式和增量式
分布式 概念: 需要搭建一个分布式的机群, 然后在每一台电脑中执行同一组程序, 让其对某一网站的数据进行联合分布爬取. 原生的scrapy框架不能实现分布式的原因 调度器不能被共享, 管道也不能被共享 ...
- SpringMVC的数据响应方式
1.页面跳转 *直接返回字符串 *通过ModelAndView对象返回 2.回写数据 *直接返回字符串 *返回对象或集合
- Django中数据传输编码格式、ajax发送json数据、ajax发送文件、django序列化组件、ajax结合sweetalert做二次弹窗、批量增加数据
前后端传输数据的编码格式(contentType) 提交post请求的两种方式: form表单 ajax请求 前后端传输数据的编码格式 urlencoded formdata(form表单里的) ja ...
- java的collection类
collection来源于java.util包. Collection 接口常用的方法 size():返回集合中元素的个数 add(Object obj):向集合中添加一个元素 addAll(Coll ...
- JavaCV的摄像头实战之七:推流(带声音)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<JavaCV的摄像头实战> ...
- 前后端分离后台管理系统 Gfast v3.0 全新发布
GFast V3.0 平台简介 基于全新Go Frame 2.0+Vue3+Element Plus开发的全栈前后端分离的管理系统 前端采用vue-next-admin .Vue.Element UI ...
- docker容器的持久化存储:Volume
独立于docker容器的持久化存储: 法(1):自动将服务器文件夹挂载到容器内部文件夹/usr/share/nginx/html,这样只修改服务器文件夹下的内容即可对应修改容器内部文件夹的内容 将服务 ...
- 一文彻底搞懂MySQL分区
一个执着于技术的公众号 一.InnoDB逻辑存储结构 首先要先介绍一下InnoDB逻辑存储结构和区的概念,它的所有数据都被逻辑地存放在表空间,表空间又由段,区,页组成. 段 段就是上图的segment ...
- go convert slice to struct
Question: in golang how to convert slice to struct scene 1:use reflect convert slice to struct func ...
- 『现学现忘』Git基础 — 22、Git中文件重命名
目录 1.用学过的命令进行文件重命名 2.使用git mv命令进行文件重命名 我们这篇文章来说说在Git中如何进行文件重命名. 提示一下,下面所说明的是对已经被Git管理的文件进行重命名,未被Git追 ...