python--生成器、三元表达式、列表解析、生成器表达式
补充:
在文件开头声明一个空字典,然后在每个函数前加上装饰器,完成自动添加到字典的操作
func_dic={}
def make_dic(key):
def deco(func):
func_dic[key] = func
def wrapper(*args, **kwargs):
res = func(*args, **kwargs)
return res
return wrapper
return deco
@make_dic('index') # @deco #f1=deco(f1)
def f1():
print('from f1')
@make_dic('home')
def f2():
print('from f2')
@make_dic('auth')
def f3():
print('from f3')
print(func_dic)
while True:
cmd = input('>>: ').strip()
if cmd in func_dic:
func_dic[cmd]()
结果:
>>: index
from f1
>>: home
from f2
>>: auth
from f3
列表解析
先来两个栗子:
s = 'hello' l = []
for i in s:
res = i.upper()
l.append(res) print(l)
结果:
['H', 'E', 'L', 'L', 'O']
l = [, , , ]
l_new = []
for i in l:
res = i**
l_new.append(res)
print(l_new)
结果:
[, , , ]
接下来就是我们的列表解析:
s = 'hello'
res = [i.upper() for i in s]
print(res)
结果:
['H', 'E', 'L', 'L', 'O']
l = [, , , , , ]
res = [i for i in l if i > ]
print(res)
结果:
[, , ]
列表解析的形式:
for i in obj1:
if 条件1:
for i in obj2:
if 条件2:
for i in obj3:
if 条件3:
...
生成器表达式
g = (i for i in range()) print(g)
print(next(g)) #next(g) == g.__next__()
print(next(g)) #next(g) == g.__next__()
print(next(g)) #next(g) == g.__next__()
print(next(g)) #next(g) == g.__next__()
print(next(g)) #next(g) == g.__next__()
结果:
<generator object <genexpr> at 0x0000000002734990>
注意:和[i for i in range(1000000000000000000000000000000000000000000)]的区别,有兴趣可以尝试运行此命令。。
len('hello') #'hello'.__len__()
print(len('hello'))
print('hello'.__len__())
结果:
注意:
相似的原理:iter(g) #g.__iter__()
三元表达式
x =
y = if x > y:
print(x)
else:
print(y) res = 'aaaaa' if x > y else 'bbbbbbb' print(res)
结果: bbbbbbb
def max2(x, y):
# if x > y:
# return x
# else:
# return y return x if x > y else y print(max2(, ))
结果:
生成器函数
函数体内包含有yield关键字,该函数执行的结果是生成器
def foo():
print('first------>')
yield
print('second----->')
yield
print('third----->')
yield
print('fourth----->') g = foo()
print(g) from collections import Iterator
print(isinstance(g, Iterator))
结果:
<generator object foo at 0x0000000001E14990>
True
所以我们得到的结果:生成器就是迭代器
def foo():
print('first------>')
yield
print('second----->')
yield
print('third----->')
yield
print('fourth----->') g = foo() print(g.__next__())
print(g.__next__())
print(g.__next__())
# print(g.__next__()) #StopInteration
结果:
first------> second-----> third----->
def foo():
print('first------>')
yield
print('second----->')
yield
print('third----->')
yield
print('fourth----->') g = foo() for i in g: #obj=g.__iter__() #obj.__next__()
print(i)
结果:
first------> second-----> third-----> fourth----->
上两例对比,我们可以看到for 自动捕捉到了StopInteration
总结:
'''
yield的功能:
1.与return类似,都可以返回值,但不一样的地方在于yield返回多次值,而return只能返回一次值
2.为函数封装好了__iter__和__next__方法,把函数的执行结果做成了迭代器
3.遵循迭代器的取值方式obj.__next__(),触发的函数的执行,函数暂停与再继续的状态都是由yield保存的
'''
def countdown(n):
print('starting countdown') while n > :
yield n
n -=
print('stop countdown')
g = countdown()
print(g)
print(g.__next__())
print(g.__next__())
print(g.__next__())
print(g.__next__())
print(g.__next__())
# print(g.__next__()) #StopInteration
结果:
<generator object countdown at 0x0000000001DF4990>
starting countdown
同样地,用for可以捕捉StopInteration。
def countdown(n):
print('starting countdown') while n > :
yield n
n -=
print('stop countdown')
g = countdown()
print(g) for i in g:
print(i)
结果:
<generator object countdown at 0x0000000002144990>
starting countdown stop countdown
应用:tail -f a.txt
import time
def tail(filepath, encoding='utf-8'):
with open(filepath, encoding=encoding) as f:
f.seek(, )
while True:
# f.seek(, ) #不行
line = f.readline()
if line:
# print(line,end='')
yield line
else:
time.sleep(0.5) g = tail('a.txt')
print(g)
print(g.__next__())
结果:
<generator object tail at 0x0000000001E04AF0>
或者可以应用for:
for i in g:
print(i)
应用:tail -f a.txt | grep 'error'
import time
def tail(filepath, encoding='utf-8'):
with open(filepath, encoding=encoding) as f:
f.seek(, )
while True:
# f.seek(, ) #不行
line = f.readline()
if line:
# print(line,end='')
yield line
else:
time.sleep(0.5) def grep(lines, pattern):
for line in lines:
if pattern in line:
# print(line)
yield line
tail_g = tail('a.txt')
print(tail_g) grep_g = grep(tail_g, 'error') print(grep_g) print(grep_g.__next__())
结果:
<generator object tail at 0x0000000001E24A98>
<generator object grep at 0x0000000001E24AF0>
qweerror
或者可以应用for:
for i in grep_g:
print(i)
作业:
编写 tail -f a.txt |grep 'error' |grep ''命令,周一默写
文件a.txt内容
apple
tesla
mac
lenovo
chicken 要求使用列表解析,从文件a.txt中取出每一行,做成下述格式
[{‘name’:'apple','price':,'count':},{...},{...},...] 格式与2一样,但只保留价格大于1000的商品信息 周末大作业(见图):
只实现作业要求的查询功能
增加,删除,修改功能为选做题
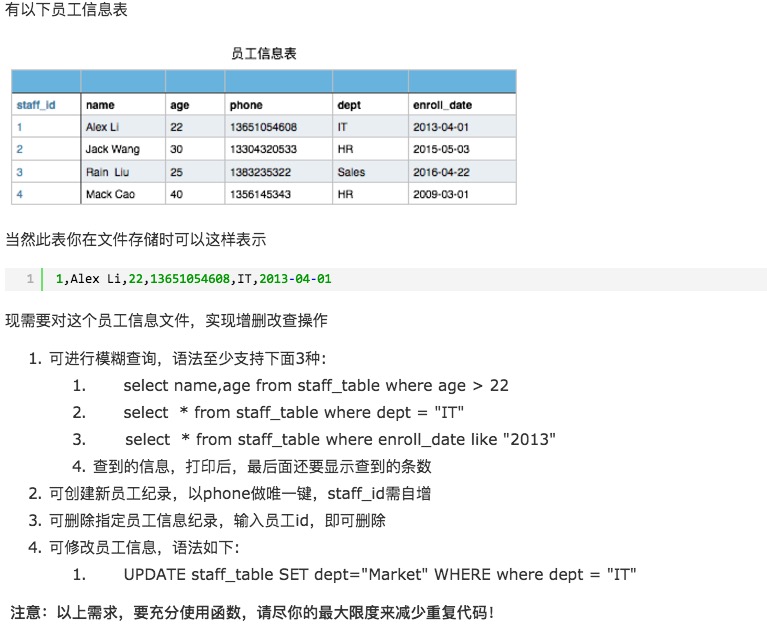
答案:
# 编写 tail -f a.txt |grep 'error' |grep ''命令,周一默写 import time
file_path = r'C:\Users\Administrator\PycharmProjects\untitled\a.txt'
def tail(file_path):
with open(file_path, encoding='utf-8') as f:
f.seek(, )
while True:
line = f.readline()
if line:
yield line
else:
time.sleep(0.5) def grep(lines, pattern):
for line in lines:
if pattern in line:
yield line g1 = tail('a.txt')
g2 = grep(g1, 'error')
g3 = grep(g2, '')
for i in g3:
print(i) # 文件a.txt内容
# apple
# tesla
# mac
# lenovo
# chicken
#
# 要求使用列表解析,从文件a.txt中取出每一行,做成下述格式
# [{‘name’:'apple','price':,'count':},{...},{...},...]
#
# print([{'name': i.split()[], 'price': i.split()[], 'count': i.split()[]} for i in
# open('a.txt')])
print([{'name': i.strip().split()[], 'price': i.strip().split()[], 'count': i.strip().split()[]} for i in
open('a.txt')]) # 格式与2一样,但只保留价格大于1000的商品信息
#
print([{'name': i.strip().split()[], 'price': i.strip().split()[], 'count': i.strip().split()[]}for i in
open('a.txt') if i.strip().split()[] > '']) # 周末大作业(见图):
# 只实现作业要求的查询功能
# # 增加,删除,修改功能为选做题
python--生成器、三元表达式、列表解析、生成器表达式的更多相关文章
- python迭代器 生成器 三元运算 列表解析
1.迭代器 迭代器是访问集合元素的一种方式.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退.另外,迭代器的一大优 ...
- day13 生成器 三元运算 列表解析
本质上来说生成器迭代器都是一种数据类型,如果你直接打印生成器是无法得出值的,会得到一串内存地址,即一个对象想要得到生成器的值必须要用for或者next,list等来获取 生成器生成器就是一个可迭代对象 ...
- Python基础:08列表解析与生成器表达式
一:列表解析 列表解析(List comprehensions)来自函数式编程语言Haskell .它可以用来动态地创建列表.它在 Python 2.0 中被加入. 列表解析的语法: [exp ...
- python利用or在列表解析中调用多个函数.py
python利用or在列表解析中调用多个函数.py """ python利用or在列表解析中调用多个函数.py 2016年3月15日 05:08:42 codegay & ...
- Python之旅Day5 列表生成式 生成器 迭代器 装饰器
装饰器 器即函数,装饰即修饰,意指为其他函数添加新功能 装饰器定义:本质就是函数,功能是为其他函数添加新功能 装饰器涉及的知识点= 高阶函数+函数嵌套+闭包 在遵循下面两个原则的前提下为被装饰者新功能 ...
- Python入门笔记(13):列表解析
一.列表解析 列表解析来自函数式编程语言(haskell),语法如下: [expr for iter_var in iterable] [expr for iter_var in iterable i ...
- python学习-迭代器,列表解析和列表生成式
迭代器为类序列对象提供了一个类序列的接口.Python 的迭代无缝的支持序列对象,而且还允许程序猿迭代非序列类型,包括用户定义的对象. 迭代器是一个next()方法的对象,而不是通过索引计数.当需要下 ...
- Python 进阶_迭代器 & 列表解析
目录 目录 迭代器 iter 内建的迭代器生成函数 迭代器在 for 循环中 迭代器与字典 迭代器与文件 创建迭代器对象 创建迭代对象并实现委托迭代 迭代器的多次迭代 列表解析 列表解析的样例 列表解 ...
- Day 21 三元表达式、生成器函数、列表解析
知识点程序: #! /usr/bin/env python # -*- coding: utf-8 -*- # __author__ = "DaChao" # Date: 2017 ...
- Python解包参数列表及 Lambda 表达式
解包参数列表 当参数已经在python列表或元组中但需要为需要单独位置参数的函数调用解包时,会发生相反的情况.例如,内置的 range() 函数需要单独的 start 和 stop 参数.如果它们不能 ...
随机推荐
- Delphi 安装Cnpack cnvcl后界面不断弹出 Memory Manager's list capablity overflow ,please enlarge it!
Delphi 安装Cnpack cnvcl后界面不断弹出 Memory Manager's list capablity overflow ,please enlarge it! 解决方法:删除指定 ...
- PHP curl_escape函数
curl_escape — 对给定的字符串进行URL编码. 说明 string curl_escape ( resource $ch , string $str ) 该函数对给定的字符串进行URL编码 ...
- 【原】webpack--文件监听的原理
轮询判断文件的最后编辑时间是否发生变化,一开始有个文件的修改时间,先存储起来这个修改时间,下次再有修改就会和上次修改时间比对,发现不一致的时候不会立即告诉监听者,而是把文件修改缓存起来,等待一段时间, ...
- Skyline(6.x)-Web二次开发-1多窗口对比
一个页面加载多个 TerraExplorer3DWindow 和 SGWorld 等只有第一个能用(即使用 iframe 也是一样) 所以我决定打开两个新页面实现多窗口对比,然后我在<主页面&g ...
- Vue&webpack入门实践
目录 1. 下载安装Vue 2. Vue 2.1 Vue要素 2.2 指令 2.3 组件化 2.4 vue-router 3. webpack 3.1 webpack简介 3.2 四个核心概念 3.3 ...
- 测开之路四十五:Django之最小程序
安装Django库 Django最小程序 import sysfrom django.conf.urls import urlfrom django.conf import settingsfrom ...
- Weblgic安装应用报错:Caused by: com.bea.xml.XmlException: failed to load java type corresponding to e=web-a
文章目录 报错如下 解决: 报错如下 Exception in AppMerge flows' progression 后台日志报错: Caused by: com.bea.xml.XmlExcept ...
- dubbo远程服务调用和maven依赖的区别
dubbo:跨系统通信.比如:两个系统,一个系统A作客户端,一个系统B作服务器, 服务器B把自己的接口定义提供给客户端A,客户端A将接口定义在spring中的bean.客户端A可直接使用这个bean, ...
- 正则search与match的区别
import re # #1.search和match的区别 # pattern = re.compile(r'\d+') # #match从头开始匹配 # m = pattern.match('on ...
- HTML段落,换行,字符实体
HTML段落,换行,字符实体 html段落 <p>标签定义一个文本段落,一个段落含有默认的上下间距,段落之间会用这种默认间距隔开,代码如下: <!DOCTYPE html> & ...