Python每日一题 008
题目
基于多线程的网络爬虫项目,爬取该站点http://www.tvtv.hk 的电视剧收视率排行榜
分析
robots.txt
User-agent: Yisouspider
Disallow: /wp-admin
User-agent: ChinasoSpider
Disallow: /
User-agent: MJ12bot
Disallow: /
User-agent: AhrefsBot
Disallow: /
User-agent: YandexBot
Disallow: /
一级URL:http://www.tvtv.hk/archives/category/dianshiju/page/1
二级URL格式:http://www.tvtv.hk/archives/8078.html
从一级URL页面中获取二级URL
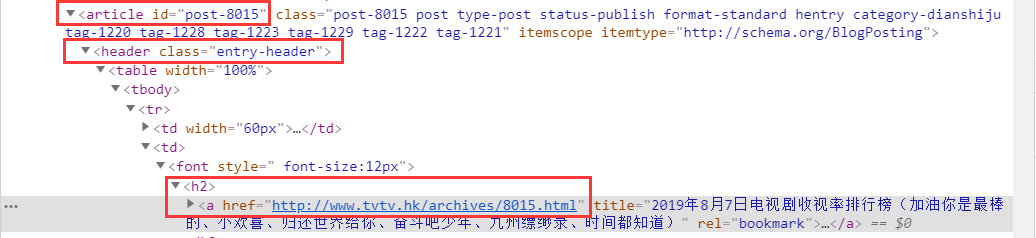
分析二级URL页面下的内容获取数据:

代码
# coding:"utf-8"
import urllib.request
from bs4 import BeautifulSoup
import re
# 爬取网页内容
def download(url):
print("正在爬取:", url)
try:
html = urllib.request.urlopen(url).read()
html = BeautifulSoup(html, 'lxml')
except urllib.request.URLError as e:
print("爬取错误:", e.reason)
html = None
return html
# 获取下一级网页中的URL
def find_url(page, tag):
page = str(page.find_all(tag))
url_list = re.findall('<a href="(.*?)" rel="bookmark"', page)
return url_list
# 爬取收视数据
def get_content(url_list):
word_data = []
for i in url_list:
html = download(i)
contents = html.find_all('p')
word_data.extend(re.findall('<p>(.*?)</p>, <p>', str(contents)))
return word_data
# 爬取图片
def img_data(url_list):
img_src = []
for j in url_list:
html = download(j)
contents = html.find_all('p')
img_src.extend(re.findall('src="(.*?)"/></p>', str(contents)))
return img_src
def write_content_tofile(filename1, filename2):
# 保存文本内容
with open(filename1, 'w+', encoding='utf-8') as f1:
data = get_content(url_list)
for i in data:
f1.write(i + "\n")
# 保存图片
img = img_data(url_list)
for j in range(len(img)):
print('正在下载第'+str(j+1)+'张图片')
path = str(j+1)
with open(filename2 + path + '.jpg', 'wb') as f2:
image_data = urllib.request.urlopen(img[j]).read()
f2.write(image_data)
if __name__ == "__main__":
url = "http://www.tvtv.hk/archives/category/dianshiju/page/1"
filename1 = "E:\\1.txt"
filename2 = "E:\\img\\"
page = download(url)
url_list = find_url(page, 'h2')
write_content_tofile(filename1, filename2)
暂时只是爬取单个页面的内容,后续更新多线程以及批量爬取!
Python每日一题 008的更多相关文章
- Python:每日一题008
题目: 判断101-200之间有多少个素数,并输出所有素数. 程序分析: 判断素数的方法:用一个数分别去除2到sqrt(这个数),如果能被整除,则表明此数不是素数,反之是素数. 个人思路及代码: li ...
- Python每日一题 004
将 0001 题生成的 200 个激活码(或者优惠券)保存到 Redis 非关系型数据库中. 代码 import redis import uuid # 创建实例 r=redis.Redis(&quo ...
- Python每日一题 003
将 002 题生成的 200 个激活码(或者优惠券)保存到 MySQL 关系型数据库中. 代码 import pymysql import uuid def get_id(): for i in ra ...
- Python每日一题 002
做为 Apple Store App 独立开发者,你要搞限时促销,为你的应用生成激活码(或者优惠券),使用 Python 如何生成 200 个激活码(或者优惠券)? 在此生成由数字,字母组成的20位字 ...
- Python每日一题 009
题目 有个目录,里面是你自己写过的程序,统计一下你写过多少行代码.包括空行和注释,但是要分别列出来. 代码 参照网络上代码 # coding: utf-8 import os import re # ...
- Python每日一题 007
题目 你有一个目录,放了你一个月的日记,都是 txt,为了避免分词的问题,假设内容都是英文,请统计出你认为每篇日记最重要的词. 很难客观的说每篇日记中最重要的词是什么,所以在这里就仅仅是将每篇日记中出 ...
- Python每日一题 006
题目 你有一个目录,装了很多照片,把它们的尺寸变成都不大于 iPhone5 分辨率的大小. 如果只是单纯的通过将图片缩放到iPhone5分辨率大小,显然最后呈现出来的效果会很糟糕.所以等比例缩放到长( ...
- Python每日一题 005
任一个英文的纯文本文件,统计其中的单词出现的个数. 代码 # coding:utf-8 import re def get_word(filename): fp=open(filename," ...
- Python每日一题 001
Github地址:https://github.com/Yixiaohan/show-me-the-code Talk is Cheap, show me the code. --Linus Torv ...
随机推荐
- vue 中使用scss
1.下载 npm install --save-dev sass-loader npm install --save-dev node-sass npm install sass-loader --s ...
- AcWing 244. 谜一样的牛 (树状数组+二分)打卡
题目:https://www.acwing.com/problem/content/245/ 题意:有n只牛,现在他们按一种顺序排好,现在知道每只牛前面有几只牛比自己低,牛的身高是1-n,现在求每只牛 ...
- [NOIP2015]子串 题解
题目描述 有两个仅包含小写英文字母的字符串A和B. 现在要从字符串A中取出k个互不重叠的非空子串,然后把这 k 个子串按照其在字符串 A 中出现的顺序依次连接起来得到一个新的字符串,请问有多少种方案可 ...
- flex布局滚动问题,子元素无法全部显示的解决办法
flex布局使用起来非常方便,对于水平垂直居中的需求,很容易就能实现.但是前不久,在做全屏弹窗遮罩登录的时候,遇到了flex布局滚动的一个问题,在此记录一下. 问题重现 理想情况下,当然是下面的状态, ...
- Java学习之线程通信(多线程(Lock))--生产者消费者
SDK1.5版本以后对synchronized的升级,其思想是:将同步和锁封装成对象,其对象中包含操作锁的动作. 代码: //1.导入包 import java.util.concurrent.loc ...
- c++primer,自定义一个复数类
#include<iostream> #include<string> #include<vector> #include<algorithm> #in ...
- 组件化框架设计之阿里巴巴开源路由框架——ARouter原理分析(一)
阿里P7移动互联网架构师进阶视频(每日更新中)免费学习请点击:https://space.bilibili.com/474380680 背景 当项目的业务越来越复杂,业务线越来越多的时候,就需要按照业 ...
- 从零开始做一个Jmeter性能测试
安装Jmeter 1.下载地址http://jmeter.apache.org/download_jmeter.cgi 2.解压下载文件,然后将bin目录添加到系统环境变量PATH里. 3.确保已安装 ...
- 消息 245,级别 16,状态 1,第 1 行 在将 varchar 值 '2,8' 转换成数据类型 int 时失败。
错误问题: 消息 245,级别 16,状态 1,第 1 行在将 varchar 值 '2,8' 转换成数据类型 int 时失败. ps: 这是在后台分配菜单权限这个功能时出现的问题 一,解决方法: 将 ...
- k8s的快速使用手册
一.快速搭建文档 一.初始化kubernete kubeadm init --kubernetes-version=v1. --apiserver-advertise-address=192.168. ...