msyql join语句执行原理
首先,我建了一个表t2,里面有1000条数据,有id,a,b三个字段,a字段加了索引
然后我又建立一个t1表,里面有100条数据,和t2表的前一百条数据一致,也是只有id,a,b三个字段,a字段加了索引
如下图
然后我们看这条语句,为了不影响效果,这里我用了STRAIGHT_JOIN ,也就是在这条语句里会把t1当做驱动表
select * from t1 STRAIGHT_JOIN t2 on t1.a=t2.a
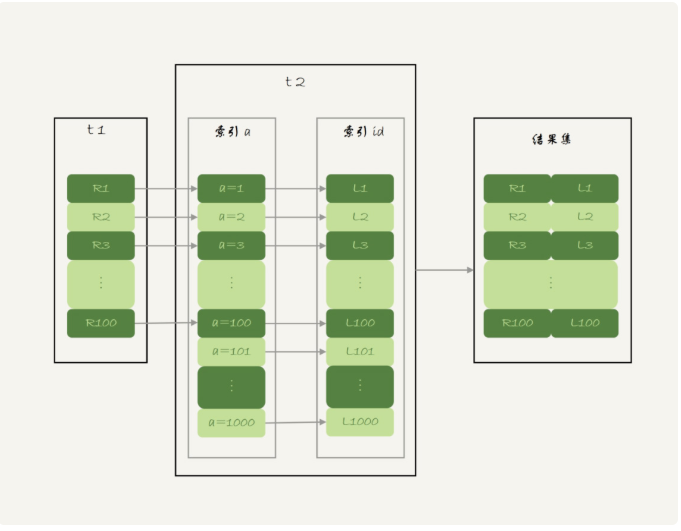
那么这条语句的执行流程就是这样的
1.从t1表查询出一行数据R
2.查出R这行数据的a字段的值到t2表中去查询
3.查询符合条件的数据和R组成一行,组装成结果集返回到客户端
4.重复执行步骤1-3,知道查到t1表的末尾
总结:由于我们在t2表上的a字段建立了索引,所以在第二步的时候不需要做全表扫描,也就是说,我们执行这条语句的扫描行数是200行,
首先t1表是扫描了100行,当和t2表每行去匹配的时候又扫描了t2表100行,所以这条语句总共扫描行数是200行,这种算法的扫描行数还是可以的。
对应的流程图如下图所示,这种算法叫作"Index Nested-Loop Join",简称NLJ
select * from t1 STRAIGHT_JOIN t2 on t1.a=t2.b
然后我们在看这条语句,由于b字段没有索引,所以在执行这条语句的时候,去t2表匹配的时候就要进行全表扫描
所以这条语句执行后的扫描行数就是100*1000=10万行
这个算法也有个名字叫做
Simple Nested-Loop Join
但是mysql没有使用这个算法,而是使用了另一种算法,叫做
Block Nested-Loop Join,简称BNL
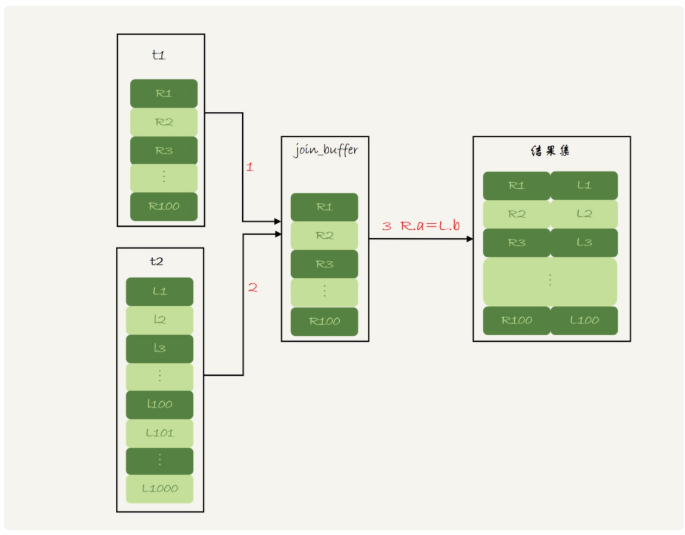
1.查询出t1的数据放入join_buffer中,由于这条语句是select *,因此是把整个表t1放入内存中
2.扫描表t2,将t2表的每一行数据和join_buffer中的数据进行匹配(全表扫描),符合条件的数据作为结果集的一部分返回
这里有个问题,如果join_buffer的大小不够存储t1表的数据怎么办呢?
其实也很简单,就是分成多部分查询放入join_buffer中
举个例子:
比如说join_buffer中只够存储50行数据,但是t1表有100行,那么就先查出t1表的50行数据放入join_buffer中,然后和t2表进行匹配
但是这样就带来了一个问题,也就是说我们要分两次放入join_buffer中,那么也就是说要对表t2进行两次全表扫描
这样扫描行数就是2200行了,不知道大家发现一个问题了没有,这个时候影响扫描行数的因素有哪些??
第一个因素就是这个join_buffer_size这个参数,如果他足够大,那么我们就只需要扫描表t2一次了,所以说有的时候我们发现了这个问题,
可以通过调大join_buffer_size这个参数来提高性能,当然不是说这个参数越大越好,要根据各方面情况来衡量。
第二个因素就是驱动表的大小,如果驱动表的数据小,那么要么不分段存入join_buffer中,那就只扫描了一次表t2,要么分段存入join_buffer中,这个时候,分段越少,那么扫描次数就越少
也就是说驱动表的数据越小越好
所以我们要使用小表来做驱动表,小表不是说某个表的真实的数据,而是说通过当前执行的语句中条件以及查询的字段而算出来的数据
例如
select t1.b,t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=100;
select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100;
在这个例子中表t1只查询出b字段放入join_buffer中
而表t2要把所有字段都放入join_buffer中,所以这个时候表t1是小表
这两种算法显然第一种算法也就是NLJ的性能要好,所以我们在写sql语句的时候要尽量让mysql使用这种算法
也就是要对连接的字段加上索引,如果该字段确实不适合加索引,没办法只能使用第二种算法,那么这个时候我们就要尽量使用小表来当做驱动表
了解更多:https://www.toutiao.com/c/user/83293539887/#mid=1633933053814798
msyql join语句执行原理的更多相关文章
- oracle-SQL语句执行原理和完整过程详解
SQL语句执行过程详解 一条sql,plsql的执行到底是怎样执行的呢? 一.SQL语句执行原理 第一步:客户端吧语句发个服务端执行 当我们在客户端执行select语句时,客户端会把这条SQL语句发送 ...
- mysql join语句的执行流程是怎么样的
mysql join语句的执行流程是怎么样的 join语句是使用十分频繁的sql语句,同样结果的join语句,写法不同会有非常大的性能差距. select * from t1 straight_joi ...
- SQL运行内幕:从执行原理看调优的本质
相信大家看过无数的MySQL调优经验贴了,会告诉你各种调优手段,如: 避免 select *: join字段走索引: 慎用in和not in,用exists取代in: 避免在where子句中对字段进行 ...
- SQL语句执行过程详解
一.SQL语句执行原理: 第一步:客户端把语句发给服务器端执行 当我们在客户端执行select语句时, 客户端会把这条SQL语句发送给服务器端,让服务器端的进程来处理这语句.也就是说,Oracle客户 ...
- [转]MySQL查询语句执行过程详解
Mysql查询语句执行原理 数据库查询语句如何执行?语法分析:首先进行语法分析,对使用sql表示的查询进行语法分析,生成查询语法分析树.语义检查:检查sql中所涉及的对象以及是否在数据库中存在,用户是 ...
- MySQL查询语句执行过程及性能优化(JOIN/ORDER BY)-图
http://blog.csdn.net/iefreer/article/details/12622097 MySQL查询语句执行过程及性能优化-查询过程及优化方法(JOIN/ORDER BY) 标签 ...
- mysql系列九、mysql语句执行过程及运行原理(分组查询和关联查询原理)
一.背景介绍 了解一个sql语句的执行过程,了解一部分都做了什么,更有利于对sql进行优化,因为你知道它的每一个连接.where.分组.子查询是怎么运行的,都干了什么,才会知道怎么写是不合理的. 大致 ...
- MySQL查询语句执行过程及性能优化-查询过程及优化方法(JOIN/ORDER BY)
在上一篇文章MySQL查询语句执行过程及性能优化-基本概念和EXPLAIN语句简介中介绍了EXPLAIN语句,并举了一个慢查询例子:
- Oracle sql语句执行顺序
sql语法的分析是从右到左 一.sql语句的执行步骤: 1)词法分析,词法分析阶段是编译过程的第一个阶段.这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构 ...
随机推荐
- ES6精解:变量的解构赋值
1.数组的解构赋值 我们知道以前我们给一个变量赋值要这样如下: let a = 1; let b = 2; let c = 3; 但是ES6出来之后,我们可以这样: let [a, b, c] = [ ...
- 构建CRD工程 - 程序员学点xx 43 k8s
目录 Kubernetes -3- 这是yann的第98篇分享 本日状态: 帮同事排了一天bug. Kubernetes -3- 这是yann的第98篇分享 第 1 部分 承前 昨天用视屏的方式演 ...
- 【新手向】一个超简单的基于jQuery ajax的天气预报Demo
<!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF-8&quo ...
- vue.js(15)--vue的生命周期
生命周期钩子 生命周期钩子=生命周期函数=生命周期事件 每个 Vue 实例在被创建时都要经过一系列的初始化过程——例如,需要设置数据监听.编译模板.将实例挂载到 DOM 并在数据变化时更新 DOM 等 ...
- Windows 好用的护眼软件
目录 1. 按 2. Windows10自带夜间模式 3. Iris Pro 3.1. 介绍 3.1.1. 保护用眼,改善睡眠 3.1.2. ×9 种不同的预设搭配 3.1.3. 计时器 3.1.4. ...
- git如何上传大文件,突破大小限制
Github中单个文件的大小限制是100MB,为了能突破这个限制,我们需要使用Git Large File Storage这个工具, git lfs install git lfs track &qu ...
- CS与BS的比较
对象 硬件环境 客户端要 求 软件安装 升级和维护 安全性 C/S 用户固定,并且处于相同区域, 要求拥有相同的操作系统. 客户端的计算机电脑配置要求较高. 每一个客户端都必须安装 ...
- Flutter-Boxdecoration邊框線, 圓角
decoration: BoxDecoration( borderRadius: BorderRadius.circular(8), border: Border( top: BorderSide( ...
- 关于pug的笔记
一.简介 Pug 是一款健壮.灵活.功能丰富的模板引擎,专门为 Node.js 平台开发.Pug 是由 Jade 改名而来,他可以帮助我们写html的时候更加的简单明了.安装.使用pug的过程打开cm ...
- js reduce用法
let books = [ 0, {bookName:"python",price:10,count:1}, {bookName:"Ruby",count:2, ...