机器学习实战笔记-11-Apriori与FP-Growth算法
Apriori算法
优点:易编码实现;缺点:大数据集上较慢;适用于:数值型或标称型数据。
关联分析:寻找频繁项集(经常出现在一起的物品的集合)或关联规则(两种物品之间的关联关系)。
概念:支持度:数据集中包含某项集的记录所占的比例P(A);可信度(置信度):对某个关联规则\(A\rightarrow B\),\(\frac{P\left( \text{AB} \right)}{P(A)}\)表示。
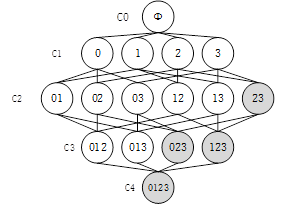
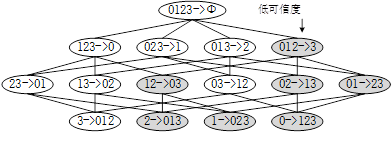
Apriori原理:频繁项集的子集一定是频繁项集,非频繁项集的超集一定是非频繁项集。
Apriori算法(目的:发现频繁项集),辅助函数”检查是否频繁项集”伪代码:
对数据集中每条交易记录transaction:
对每个候选项集can:
检查can是否是tran的子集:
如果是,则增加can项集的计数值
对每个候选项集can:
如果支持度不低于最小值(参数),则保留该项集
返回所有频繁项集列表,支持度词典
Apriori算法(目的:发现频繁项集),伪代码:
生成C1项集(只有1个元素的项集)
利用辅助函数过滤掉C1的非频繁项集
当项集列表$C_{k - 1}$中项集的个数大于0时:
构建候选项集的列表$C_{k}$(用$C_{k - 1}$构建$C_{k}$:$C_{k -1}$中项集两两比较,如果前$k -2$个元素均一样,则可以合并为一个大小为$k$的项集)
检查数据集以确认每个$C_{k}$的项集均为频繁的
保存该频繁项集列表$C_{k}$
K++
FP-growth算法(Frequency
Pattern-Growth):较Apriori更快,但实现较之困难,适用于标称型。第一次遍历数据集统计每个元素项的频率>>去掉小于最小支持度的元素项>>按频率(从大到小)对元素项进行排序>>按该顺序对数据集中各条数据进行排序>>|构建FP树|读入每个项集并将其添加到一条已存在的路径中,如果该路径不存在,则创建一条新路径>>抽取条件模式基(以所查元素为结尾的路径的集合)>>以条件模式基为每一个元素项创建一个条件FP树(每步进行最小支持度的检查)>>在该条件FP树中的两两组合项集挖掘条件FP树,即重复以上两步直到条件树没有元素为止。
机器学习实战笔记-11-Apriori与FP-Growth算法的更多相关文章
- 机器学习(十五)— Apriori算法、FP Growth算法
1.Apriori算法 Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策. Apriori算法采用了迭代的方法,先搜 ...
- 机器学习实战笔记-k-近邻算法
机器学习实战笔记-k-近邻算法 目录 1. k-近邻算法概述 2. 示例:使用k-近邻算法改进约会网站的配对效果 3. 示例:手写识别系统 4. 小结 本章介绍了<机器学习实战>这本书中的 ...
- FP—Growth算法
FP_growth算法是韩家炜老师在2000年提出的关联分析算法,该算法和Apriori算法最大的不同有两点: 第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率,用31646条测试记录, ...
- Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- 关联规则算法之FP growth算法
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- Frequent Pattern 挖掘之二(FP Growth算法)
Frequent Pattern 挖掘之二(FP Growth算法) FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断 ...
- 机器学习实战笔记(Python实现)-00-readme
近期学习机器学习,找到一本不错的教材<机器学习实战>.特此做这份学习笔记,以供日后翻阅. 机器学习算法分为有监督学习和无监督学习.这本书前两部分介绍的是有监督学习,第三部分介绍的是无监督学 ...
- 机器学习实战笔记(Python实现)-08-线性回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-06-AdaBoost
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
随机推荐
- GooglePlay
如何下载googlePLay的apk文件? 1.首先要知道apk的package名: 打开GooglePlay的页面,在地址栏里就会有https://play.google.com/store/app ...
- 搜索(DFS)---矩阵中的连通分量数目
矩阵中的连通分量数目 200. Number of Islands (Medium) Input: 11000 11000 00100 00011 Output: 3 题目描述: 给定一个矩阵,求 ...
- 27、前端知识点--webpack面试题(二)
webpack面试题总结 本文主要是对webpack面试会常被问到的问题做一些总结,且文章会不断持续更新 1.webpack打包原理 把所有依赖打包成一个 bundle.js 文件,通过代码分割成单元 ...
- lLinux的常用命令
命令基本格式: 命令提示符:[root@localhost ~]# root 代表当前的登录用户(linux当中管理员账号是root) @ 无实际意义 localhost ...
- 如何在Set集合中避免重复元素
文章翻译自 Avoiding near-duplicates in sets, 作者Paul Hudson @twostraws是一名优秀的Swifter. 这是我第一次翻译,可能有翻译不到位的地方, ...
- apache重写规则简单理解
1.前提:开启apache重写,并把httpd.conf里的相关的AllowOverride denied改为AllowOverride all 2.重写规则可写在项目根目录的.htaccess文件或 ...
- fastjson合并json数组中相同的某个元素
/** * @param array JSON数组 * @param array 需合并后的某个元素名 */ private static JSONArray mgreArray(JSONArray ...
- bzoj4002 [JLOI2015]有意义的字符串 特征根+矩阵快速幂
题目传送门 https://lydsy.com/JudgeOnline/problem.php?id=4002 题解 神仙题. 根据下面的一个提示: \[ b^2 \leq d \leq (b+1)^ ...
- 神仙dcx出的一道题
题目大意 \(\;\;\)在一个坐标系上, 以\((0, 0)\)为起点, 每走一步,可以从\((x,y)\)走到\((x+1,y),(x-1,y),(x,y+1),(x,y-1)\)中的一个点上, ...
- 对webpack的初步研究4
Mode string module.exports = { mode: 'production' }; webpack --mode=production The following string ...