循环神经网络(LSTM和GRU)(1)
循环神经网络的简单实现:
import tensorflow as tf
x=[1,2]
state=[0.0,0.0]
w_cell_state=np.array([[0.1,0.2],[0.3,0.4]])
w_cell_input=np.array([0.5,0.6])
b_cell=np.array([0.1,-0.1])
w_output=np.array([1.0,2.0])
b_output=0.1
for i in range(len(x)):
before_a=np.dot(state,w_cell_state)+x[i]*w_cell_input+b_cell #初始状态state默认为[0,0]
state=np.tanh(before_a) #当前层的状态state
final_out=np.dot(state,w_output)+b_output #得到输出层结果
print(before_a)
print('state:', state)
print('final_out:', final_out)
与单一tanh循环体结构不同,LSTM是一个拥有三个门结构的特殊网络结构。
LSTM靠一些门结构让信息有选择性的影响循环神经网络中每个时刻的状态,所谓的门结构就是一个使用sigmoid神经网络和一个按位做乘法的操作,这两个操作合在一起就是一个门结构。之所以该结构叫门是因为使用sigmoid作为激活函数的全连接神经网络层会
输出一个0到1之间的数值,描述当前输入有多少信息量可以通过这个结构。该结构功能就类似于一扇门,当门打开时(sigmoid神经网络输出为1时),全部信息都可以通过;当门关上时(sigmoid神经网络输出为0时),任何信息都无法通过。
LSTM单元结构示意图如下所示:
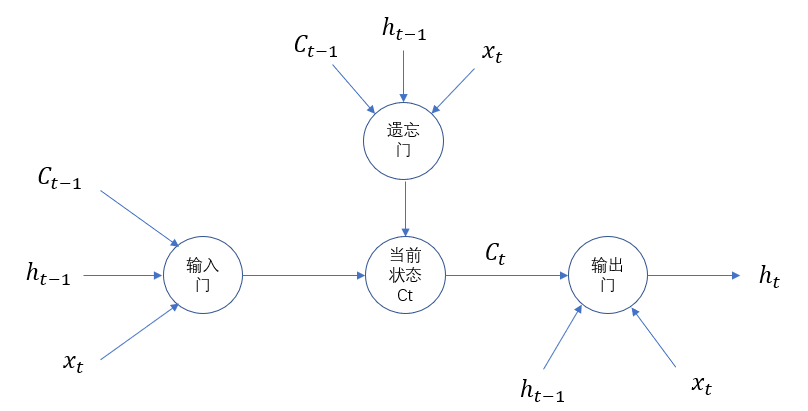
为了使循环神经网络更有效的保存长期记忆,遗忘门和输入门是LSTM核心,遗忘门的作用是让神经网络忘记之前没有用的信息,遗忘门会根据当前的输入xt、上一时刻状态ct-1和上一时刻输出ht-1共同决定哪一部分记忆需要被遗忘。
在循环神经网络忘记了部分之前的状态后,它还需要从当前的输入补充最新的记忆。这个过程就是输入门完成的,输入门会根据xt、ct-1和ht-1决定哪些部分进入当前时刻的状态ct。比如当看到文章中提到环境被污染之后,模型需要将这个信息写入
新的状态,通过遗忘门和输入门,LSTM可以更有效的决定哪些信息应该被遗忘,哪些信息应该得到保留。
LSTM结构在计算得到新的状态ct后需要产生当前时刻的输出,该过程通过输出门完成,输出门会根据最新的状态ct、上一时刻的输出ht-1和当前的输入xt来决定该时刻的输出ht。如下代码展示了tensorflow中实现LSTM结构的循环神经网络的前向传播过程:
#定义一个LSTM结构,通过一个简单的命令实现一个完整的LSTM结构
lstm=tf.contrib.rnn.BasicRNNCell(lstm_hidden_size)
#将LSTM中的状态初始化为全0数组,在优化循环神经网络时,每次也会使用一个batch的训练样本。
state=lstm.zero_state(batch_size,tf.float32)
loss=0.0
for i in range(num_steps):
#在第一个时刻声明LSTM结构中使用的变量,在之后的时刻都需要复用之前定义好的变量
if i>0:
tf.get_variable_scope().reuse_variables()
#每一步处理时间序列中的一个时刻,将当前输入(current_input)和前一时刻状态(state)传入定义的LSTM结构可以得到当前LSTM结构的输出lstm_output和更新后的状态state
lstm_output,state=lstm(current_input,state)
#将当前时刻LSTM结构的输出传入一个全连接层得到最后的输出
final_output=fully_connected(lstm_output)
#计算当前时刻输出的损失
loss+=calc_loss(final_output,expected_output)
LSTM为克服无法很好的处理远距离依赖而提出
一、传统的LSTM结构:
参考:https://blog.csdn.net/zhangxb35/article/details/70060295?locationNum=2&fps=1
参考:https://blog.csdn.net/u010751535/article/details/59536631
参考:https://www.cnblogs.com/taojake-ML/p/6272605.html
1、输入门:

2、遗忘门:
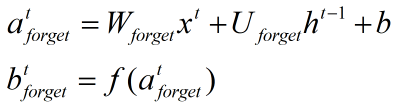
3、输出门:
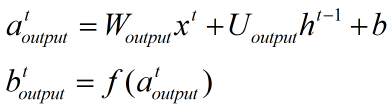
4、当前状态:
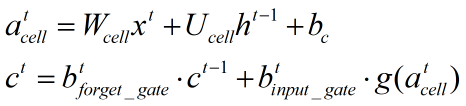 当前状态的计算过程和下面LSTM的变种的计算过程相同。
当前状态的计算过程和下面LSTM的变种的计算过程相同。
5、输出结果:
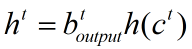 h()为激活函数,将当前状态经激活函数后和输出门结果乘积,得到最终结果
h()为激活函数,将当前状态经激活函数后和输出门结果乘积,得到最终结果
二、LSTM的变体公式如下(比传统的LSTM计算多了上一层的状态ct-1):
(参考:https://www.cnblogs.com/taojake-ML/p/6272605.html)
(参考:https://blog.csdn.net/zhangxb35/article/details/70060295?locationNum=2&fps=1)
(参考:https://zybuluo.com/hanbingtao/note/581764 好文)
1、输入门:
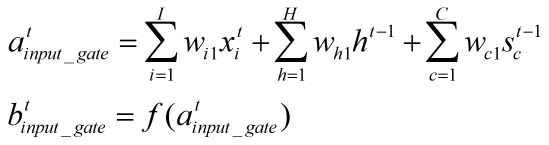 输入门根据xt,ht-1,st-1来决定哪些部分进入当前时刻的状态
输入门根据xt,ht-1,st-1来决定哪些部分进入当前时刻的状态
上一时刻的输出、上一时刻的状态、当前时刻的输入进行加权求和,再经激活函数得到输出结果(传统的LSTM的状态c在这里改成s)
其中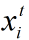 表示当前时刻的输入,ht-1表示上一时刻的输出,st-1表示上一时刻的状态(也即上一时刻的经过激活函数处理的门输出结果),c下标表示cell,f()表示激活函数。
表示当前时刻的输入,ht-1表示上一时刻的输出,st-1表示上一时刻的状态(也即上一时刻的经过激活函数处理的门输出结果),c下标表示cell,f()表示激活函数。
I表示输入层的神经元个数,K是输出层的神经元个数,H是隐藏层H的个数。wi1和wi2分别表示输入门、遗忘门的权重。
2、遗忘门:
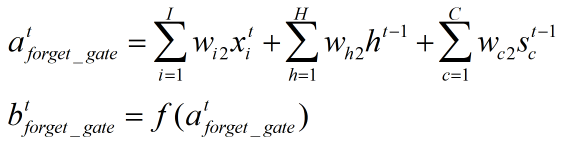 遗忘门根据xt,ht-1,st-1来决定哪些部分进入当前时刻的状态
遗忘门根据xt,ht-1,st-1来决定哪些部分进入当前时刻的状态
同样是上一时刻的输出、上一时刻的状态、当前时刻的输入进行加权求和,再经激活函数得到输出结果
3、当前状态:
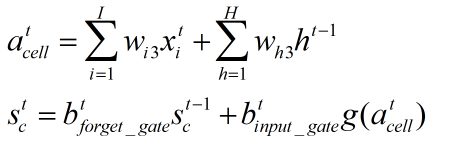
计算上一时刻的输出、当前时刻的输入进行加权求和,将遗忘门和输入门的结果作为权重,计算上一时刻状态和当前经激活函数处理的acell的加权和
4、输出门:
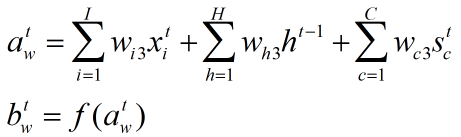
计算当前输入、上一时刻的输出、当前状态的加权和,并经激活函数得到输出结果
5、结果输出:
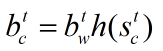
遗忘门和输入门经激活函数处理后返回结果在[0,1]区间,在计算当前状态的过程中,假若遗忘门结果取0,那么上一层的状态将不会对当前状态产生影响,也就表现为上一层的状态会被遗忘(这也就是门结构的由来)。然后则只关注这个时刻的输入,输入门决定了是否接受现在时刻的输入。
最后通过输出门的结果来决定是否输出当前状态。
变体LSTM图形如下:
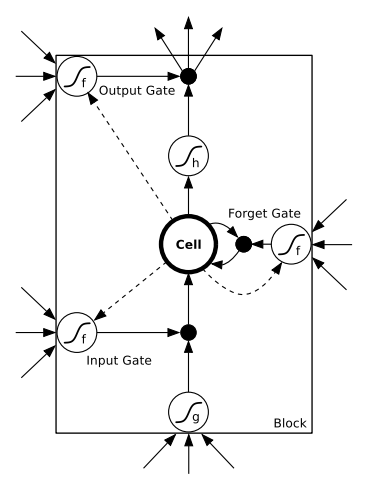
(资料来源:引自 Alex Graves 的论文 Supervised Sequence Labelling with Recurrent Neural Networks 中对 LSTM 的描述)
一个以LSTM为模型的实现的例子如下所示:
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets('MNIST_data',one_hot=True)
lr=0.001
training_iters=100000
batch_size=128
n_inputs=28 #mnist data input (img shape:28*28)
n_steps=28
n_hidden_units=128 #neurons in hidden layer
n_classes=10 #mnist classes x=tf.placeholder(tf.float32,[None,n_steps,n_inputs])
y=tf.placeholder(tf.float32,[None,n_classes])
weight={
'in':tf.Variable(tf.random_normal([n_inputs,n_hidden_units])) ,
'out':tf.Variable(tf.random_normal([n_hidden_units,n_classes]))
}
biases={
'in':tf.Variable(tf.constant(0,1,shape=[n_hidden_units,])),
'out':tf.Variable(tf.constant(0.1,shape=[n_classes,]))
}
def RNN(X,weight,biases):
X=tf.reshape(X,[-1,n_inputs])
X_in=tf.matmul(X,weight['in'])+biases['in'] #shape=[n_steps,n_hidden_units] biases_shape=[n_hidden_units]
X_in=tf.reshape(X_in,[-1,n_steps,n_hidden_units])
lstm_cell=tf.contrib.rnn.BasicLSTMCell(n_hidden_units,forget_bias=1.0,state_is_tuple=True)
init_state=lstm_cell.zero_state(batch_size,dtype=tf.float32)
outputs,final_state=tf.nn.dynamic_rnn(lstm_cell,X_in,initial_state=init_state,time_major=False)
results=tf.matmul(final_state[1],weight['out'])+biases['out']
return results
pred=RNN(x,weight,biases)
cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y))
train_op=tf.train.AdamOptimizer(lr).minimize(cost) correct_pred=tf.equal(tf.argmax(pred,1),tf.argmax(y,1))
accuracy=tf.reduce_mean(tf.cast(correct_pred,tf.float32))
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
step=0
while step*batch_size<training_iters:
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
batch_xs=batch_xs.reshape([batch_size,n_steps,n_inputs])
sess.run([train_op],feed_dict={x:batch_xs,y:batch_ys})
if step%20==0:
print(sess.run(accuracy,feed_dict={x:batch_xs,y:batch_ys}))
step+=1
三、GRU模型
参考:https://www.cnblogs.com/taojake-ML/p/6272605.html
相较于LSTM的三个门计算实现:遗忘门、输入门、输出门
GRU则只剩下两个门,分别为更新门和重置门。也就是zt和rt,更新门用于控制前一时刻的状态信息被带入当前状态的程度,更新门越大说明前一时刻被带入的信息越多。重置门用于控制忽略前一时刻状态信息的程度,重置门值越小说明忽略的信息越多。
其中GRU的图形如下所示:
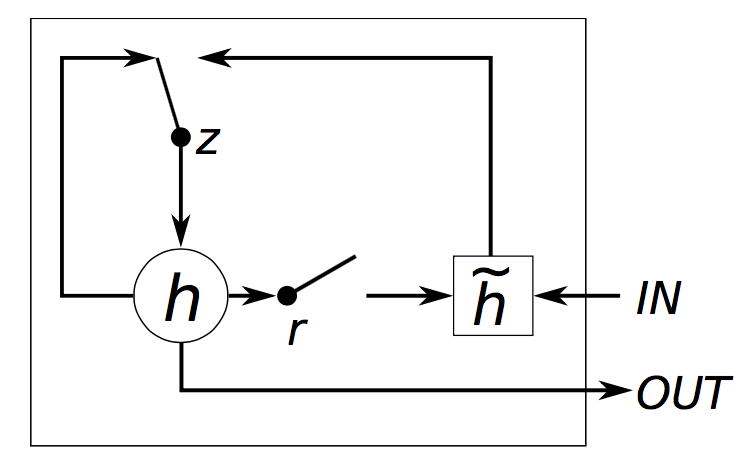
计算公式如下所示:
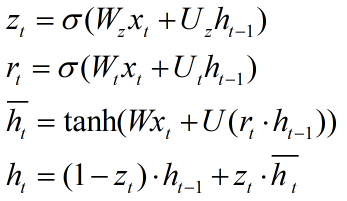
其中zt是更新门(update gate),用于更新activation时的逻辑门(表现在计算ht的时候,是否更新)。相较于LSTM,这里将遗忘门和输入门合成了一个更新门
rt是重置门(reset gate),用于决定candidate activation时,是否放弃以前的activation ht-1,在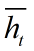 计算中,当rt趋向于0时,则表现为遗忘上一时刻的ht-1
计算中,当rt趋向于0时,则表现为遗忘上一时刻的ht-1
是candidate activation(所谓的候选即不直接将计算结果拿来用,而是用于进一步的计算),接收[xt,ht-1]
ht是activation,是GRU的隐层,接收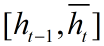
循环神经网络(LSTM和GRU)(1)的更多相关文章
- 十 | 门控循环神经网络LSTM与GRU(附python演练)
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习.深度学习的知识! 目录: 门控循环神经网络简介 长短期记忆网络(LSTM) 门控制循环单元(GRU) ...
- 循环神经网络LSTM RNN回归:sin曲线预测
摘要:本篇文章将分享循环神经网络LSTM RNN如何实现回归预测. 本文分享自华为云社区<[Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测 丨[百变AI秀]& ...
- Pytorch循环神经网络LSTM时间序列预测风速
#时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大 ...
- 循环神经网络-LSTM进阶
基础的LSTM模型,单隐层,隐层单神经元,而实际中一般需要更为复杂的网络结构, 下面借用手写数字的经典案例构造比较复杂的LSTM模型,并用代码实现. 单隐层,隐层多神经元 # -*- coding:u ...
- 循环神经网络-LSTM
LSTM(Long Short-Term Memory)是长短期记忆网络,是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件. LSTM能够很大程度上缓解长期依赖的问题. ...
- 深度学习 循环神经网络 LSTM 示例
最近在网上找到了一个使用LSTM 网络解决 世界银行中各国 GDP预测的一个问题,感觉比较实用,毕竟这是找到的唯一一个可以正确运行的程序. #encoding:UTF-8 import pandas ...
- 循环神经网络之LSTM和GRU
看了一些LSTM的博客,都推荐看colah写的博客<Understanding LSTM Networks> 来学习LSTM,我也找来看了,写得还是比较好懂的,它把LSTM的工作流程从输入 ...
- 机器学习(ML)九之GRU、LSTM、深度神经网络、双向循环神经网络
门控循环单元(GRU) 循环神经网络中的梯度计算方法.当时间步数较大或者时间步较小时,循环神经网络的梯度较容易出现衰减或爆炸.虽然裁剪梯度可以应对梯度爆炸,但无法解决梯度衰减的问题.通常由于这个原因, ...
- 深度学习四从循环神经网络入手学习LSTM及GRU
循环神经网络 简介 循环神经网络(Recurrent Neural Networks, RNN) 是一类用于处理序列数据的神经网络.之前的说的卷积神经网络是专门用于处理网格化数据(例如一个图像)的神经 ...
随机推荐
- c# 用DotNetZip来解压/压缩文件
//https://archive.codeplex.com/?p=dotnetzip //最新在Nuget 下载DotNetZip using Ionic.Zip; private void but ...
- 009-Spring Boot 事件监听、监听器配置与方式、spring、Spring boot内置事件
一.概念 1.事件监听的流程 步骤一.自定义事件,一般是继承ApplicationEvent抽象类 步骤二.定义事件监听器,一般是实现ApplicationListener接口 步骤三.启动时,需要将 ...
- jvm jstack log分析工具,在线分析
http://spotify.github.io/threaddump-analyzer Spotify提供的Web版在线分析工具,可以将锁或条件相关联的线程聚合到一起.
- c# Thread——1.为什么Abort中断线程是不可靠的
Thread.Abort 方法在c#中用作强制中断线程的执行,大多用于线程内部满足某个特定条件而自己调用关闭自身,比如下面的代码在i自增到3的时候就会停止打印. class Program { sta ...
- PHP上传文件到阿里云OSS,nginx代理访问
1. 阿里云OSS创建存储空间Bucket(读写权限为:公共读) 2. 拿到相关配置 accessKeyId:********* accessKeySecret:********* endpoint: ...
- C++笔记(6)——关于OJ的单点测试和多点测试
单点测试 PAT使用的就是单点测试(LeetCode应该也是单点测试).单点测试中系统会判断每组数据的输出结果是否正确,正确则通过测试并获得这则测试的分值.题目的总得分等于通过的数据的分值之和. 代码 ...
- 关于this在不同使用情况表示的含义
1. addEventListener 函数中的this 指向的是出发事件的事件源 obj.addEventListener('click',function(){ console.log(thi ...
- 剑指Offer编程题(Java实现)——替换空格
题目描述 请实现一个函数,将一个字符串中的每个空格替换成“%20”.例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy. 解题思路1 在字符串尾部填充任 ...
- RPC-基于原生java实现
一:什么是RPC 远程过程调用(Remote Procedure Call).就是调用其他业务方的方法的时候,就像是调用自己本地的方法一样. 二:java rpc实现简介 服务端(使用反射) (1)服 ...
- FZUOJ-2275 Game
Problem 2275 Game Accept: 159 Submit: 539 Time Limit: 1000 mSec Memory Limit : 262144 KB Pro ...