JAVA-ThreadPoolExecutor 线程池
一、创建线程池
/**
* @param corePoolSize 核心线程池大小
* 当提交一个任务到线程池时,如果当前 poolSize < corePoolSize 时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程
* 等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的 prestartAllCoreThreads() 方法,线程池会提前创建并启动所有基本线程。
*
* @param maximumPoolSize 最大线程池大小
* 线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。
* 值得注意的是,如果使用了无界的任务队列这个参数就没什么效果。
*
* @param keepAliveTime 线程活动保持时间
* 线程池的工作线程空闲后,保持存活的时间。所以,如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率。
*
* @param unit 线程活动保持时间的单位
* TimeUnit.DAYS:天
* TimeUnit.HOURS:小时
* TimeUnit.MINUTES:分钟
* TimeUnit.MILLISECONDS:毫秒
* TimeUnit.MICROSECONDS:微秒,千分之一毫秒
* TimeUnit.NANOSECONDS:纳秒,千分之一微秒
*
* @param workQueue 保存等待执行的任务的阻塞队列
* ArrayBlockingQueue:一个基于数组结构的有界阻塞队列,按FIFO(先进先出)进行排序
* LinkedBlockingQueue:一个基于链表结构的阻塞队列,按FIFO(先进先出)排序元素,吞吐量通常要高于ArrayBlockingQueue。
* SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于Linked-BlockingQueue。
* PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
*
* @param threadFactory 创建线程的工厂
* 使用开源框架 guava 提供的 ThreadFactoryBuilder 可以快速给线程池里的线程设置有意义的名字
* ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
*
* @param handler maxmumPoolSize + workQueue 都满了之后处理新提交任务的策略
* AbortPolicy:直接抛出异常(默认)。
* CallerRunsPolicy:只用调用者所在线程来运行任务。
* DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
* DiscardPolicy:不处理,丢弃掉。
* 也可实现 RejectedExecutionHandler 接口自定义策略,如记录日志或持久化存储不能处理的任务。
*/
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
二、使用线程池
2.1.提交无返回值任务 execute(),输入的任务是一个 Runnable 类的实例,无法判断任务是否被线程池执行成功
// 线程工厂,这里主要用来设置线程名字
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
// 创建线程池
ThreadPoolExecutor singleThreadPool = new ThreadPoolExecutor(
1,
1,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(1024),
namedThreadFactory,
new ThreadPoolExecutor.AbortPolicy());
// 向线程池提交任务
singleThreadPool.execute(() -> System.out.println(Thread.currentThread().getName()));
2.2.提交有返回值任务 submit(),输入的任务是一个 Callable 或 Runnable 类的实例,有返回值,且可抛出异常,可中断线程
// 线程工厂,这里主要用来设置线程名字
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
// 创建线程池
ThreadPoolExecutor singleThreadPool = new ThreadPoolExecutor(
1,
1,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(1024),
namedThreadFactory,
new ThreadPoolExecutor.AbortPolicy());
// 添加任务
Future<String> future = singleThreadPool.submit(new Callable<String>() {
@Override
public String call() {
return Thread.currentThread().getName();
}
}); // 获取结果,会阻塞当前线程,这里调用了有参方法,指定了阻塞时间,若在时间内未执行完则获取结果会报错
System.out.println("结果:" + future.get(1, TimeUnit.SECONDS));
System.out.println("是否执行完成:" + future.isDone());
2.3.关闭线程池 shutdown() 与 shutdownNow()
// 调用后,不可以再submit新的task,已经submit的将继续执行。会遍历已经在线程池中的工作线程,然后逐个调用线程的 interrupt 方法来中断线程
singleThreadPool.shutdown();
// 首先将线程池的状态设置成STOP,然后试图停止当前正执行或暂停的 task 的线程,并返回尚未(等待)执行的 task 的 list
List<Runnable> runnables = singleThreadPool.shutdownNow();
三、线程池处理流程
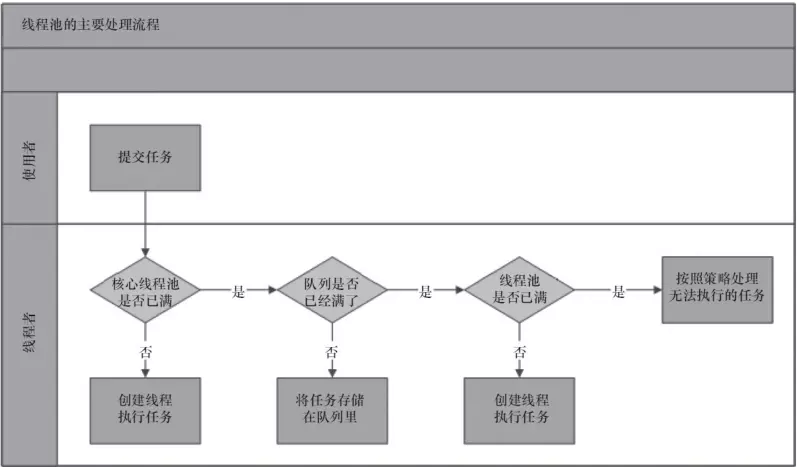
对应到代码中 ThreadPoolExecutor 的 execute() 方法
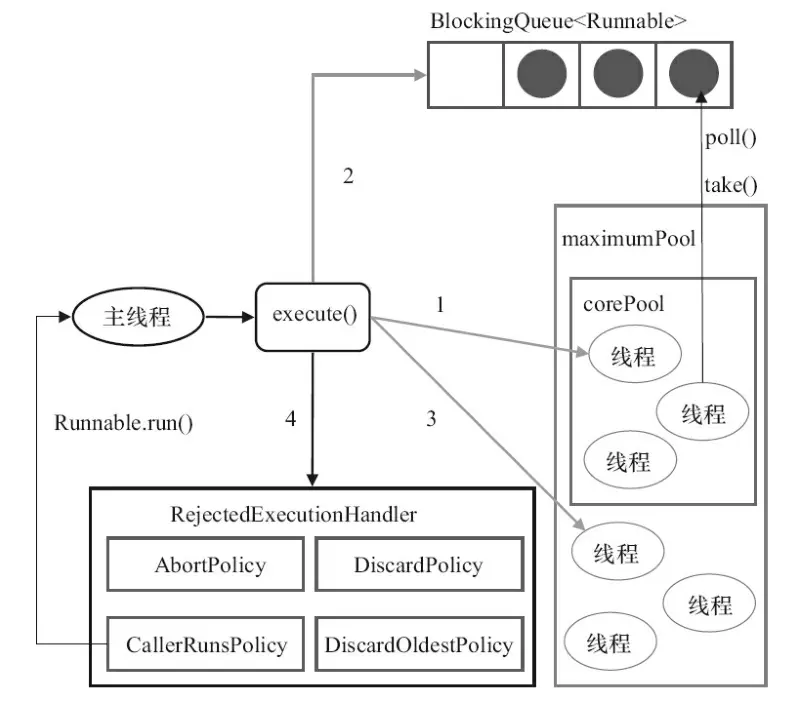
四、ThreadPoolExecutor 源码
execute 执行任务方法
public void execute(Runnable command) {
// 如果提交了空的任务则抛出异常
if (command == null)
throw new NullPointerException();
// 分三步
int c = ctl.get();
// 1.当前工作线程数量是否小于核心线程数量
if (workerCountOf(c) < corePoolSize) {
//启动新线程(核心),对 addWorker 的调用以原子方式检查 runState 和 workerCount
if (addWorker(command, true))
return;
// 如果提交失败 则二次检查状态
c = ctl.get();
}
// 2.如果线程池处于运行状态,则添加任务到阻塞队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 添加到队列成功,再检查一次线程池的状态,如果线程池关闭了,就将刚才添加的任务从队列中移除,并执行拒绝策略
if (!isRunning(recheck) && remove(command))
reject(command);
// 如果当前线程池线程空,则添加一个新线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3.尝试添加一个新线程(非核心),新增失败则已关闭或饱和,执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}
addWorker 添加任务方法
private boolean addWorker(Runnable firstTask, boolean core) {
// 大致分为两部分
// 1.增加线程池个数
retry:
for (; ; ) {
int c = ctl.get();
int rs = runStateOf(c);
// 检查当前线程池状态是否是 SHUTDOWN、STOP、TIDYING 或者 TERMINATED
// 且!(当前状态为SHUTDOWN,且传入的任务为null,且队列不为null)
// 条件都成立则返回 false
if (rs >= SHUTDOWN && !(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty()))
return false;
for (; ; ) {
int wc = workerCountOf(c);
// 如果当前的线程数量超过最大容量或者大于(根据传入的 core 决定)核心线程数 || 最大线程数,则返回 false
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 尝试修改线程数,cas 操作
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get();
// 判断线程池的状态是否改变
if (runStateOf(c) != rs)
continue retry;
}
}
// 2.将任务添加到 workers 里面并执行
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 新建一个线程
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
// 加锁
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
// 判断线程池的状态
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) {
// 检查线程是否已经启动
if (t.isAlive())
throw new IllegalThreadStateException();
// 将线程添加到线程池中
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
// 设置新增标志
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 如果 worker 是新增的,就启动该线程
if (workerAdded) {
t.start();
// 成功启动了线程,设置对应的标志
workerStarted = true;
}
}
} finally {
// 判断线程是否启动成功
if (!workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
t.start() 实际调用的是 runWorker()
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// 允许其他线程来中断自己
w.unlock();
boolean completedAbruptly = true;
try {
// 循环获取任务
while (task != null || (task = getTask()) != null) {
w.lock();
// 检查线程池状态
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted())
wt.interrupt();
try {
// 提供给继承类使用做一些统计之类的事情,在线程运行前调用
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 提供给继承类使用做一些统计之类的事情,在线程运行之后调用
afterExecute(task, thrown);
}
} finally {
task = null;
// 统计当前线程完成了多少个任务
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 整个线程结束时调用,线程退出操作。统计整个线程池完成的任务个数之类的工作
processWorkerExit(w, completedAbruptly);
}
}
getTask() 获取任务
private Runnable getTask() {
// 最后一次 poll() 是否超时
boolean timedOut = false;
for (; ; ) {
int c = ctl.get();
int rs = runStateOf(c);
// 仅在必要时检查队列是否为空,如果线程池已经关闭了,就直接返回 null
// SHUTDOWN 状态表示执行了 shutdown() 方法,STOP 表示执行了 shutdownNow() 方法
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
// 线程数量
int wc = workerCountOf(c);
// 核心 worker 是否超时,当前正在运行的 worker 数量超过了 corePoolSize
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 如果上一次循环从队列获取到的为 null,这时 timedOut 就会为 true 了
if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) {
// 通过 cas 来设置 WorkerCount,多个线程竞争,只有一个可以设置成功
// 没设置成功,进入下一次循环,可能下次 worker 的数量就没有超过 corePoolSize,也就不用销毁 worker
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 获取任务,超过 keepAliveTime 时间还没有任务进队列就会返回 null,worker 会销毁
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
https://www.jianshu.com/p/098819be088c
https://blog.csdn.net/u013332124/article/details/79587436
http://www.cnblogs.com/fixzd/p/9253203.html
JAVA-ThreadPoolExecutor 线程池的更多相关文章
- Java ThreadPoolExecutor线程池原理及源码分析
一.源码分析(基于JDK1.6) ThreadExecutorPool是使用最多的线程池组件,了解它的原始资料最好是从从设计者(Doug Lea)的口中知道它的来龙去脉.在Jdk1.6中,Thread ...
- Java并发——ThreadPoolExecutor线程池解析及Executor创建线程常见四种方式
前言: 在刚学Java并发的时候基本上第一个demo都会写new Thread来创建线程.但是随着学的深入之后发现基本上都是使用线程池来直接获取线程.那么为什么会有这样的情况发生呢? new Thre ...
- 深入理解Java之线程池
原作者:海子 出处:http://www.cnblogs.com/dolphin0520/ 本文归作者海子和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则 ...
- Java并发——线程池Executor框架
线程池 无限制的创建线程 若采用"为每个任务分配一个线程"的方式会存在一些缺陷,尤其是当需要创建大量线程时: 线程生命周期的开销非常高 资源消耗 稳定性 引入线程池 任务是一组逻辑 ...
- Java中线程池的学习
线程池的基本思想还是一种对象池的思想,开辟一块内存空间,里面存放了众多(未死亡)的线程,池中线程执行调度由池管理器来处理.当有线程任务时,从池中取一个,执行完成后线程对象归池,这样可以避免反复创建线程 ...
- 13.ThreadPoolExecutor线程池之submit方法
jdk1.7.0_79 在上一篇<ThreadPoolExecutor线程池原理及其execute方法>中提到了线程池ThreadPoolExecutor的原理以及它的execute方法 ...
- ThreadPoolExecutor 线程池的源码解析
1.背景介绍 上一篇从整体上介绍了Executor接口,从上一篇我们知道了Executor框架的最顶层实现是ThreadPoolExecutor类,Executors工厂类中提供的newSchedul ...
- ThreadPoolExecutor线程池
为什么使用线程池: 1.创建/销毁线程伴随着系统开销,过于频繁的创建/销毁线程,会很大程度上影响处理效率. 2.线程并发数量过多,抢占系统资源从而导致阻塞. 3.对线程进行一些简单的管理. 在java ...
- 深入理解Java之线程池(爱奇艺面试)
爱奇艺的面试官问 (1) 线程池是如何关闭的 (2) 如何确定线程池的数量 一.线程池销毁,停止线程池 ThreadPoolExecutor提供了两个方法,用于线程池的关闭,分别是shutdown() ...
- Java中线程池,你真的会用吗?
在<深入源码分析Java线程池的实现原理>这篇文章中,我们介绍过了Java中线程池的常见用法以及基本原理. 在文中有这样一段描述: 可以通过Executors静态工厂构建线程池,但一般不建 ...
随机推荐
- 07 Python之字典和集合
1. 什么是字典 字典是用{}表示,以key:value的形式来保存数据的,其查找效率比较高 坑: 字典存储数据时是用哈希值来存储的,算法不能变(python的) 数据必须是可哈希的(不可变的),字典 ...
- oracle创建表前校验是否存在
创建表前检查是否存在,并删除 --检查是否存在此表,存在则删除 declare num number; begin select count(1) into num from user_tables ...
- python-迭代器与生成器3
python-迭代器与生成器3 迭代器可以直接作用于for循环的数据类型有以下几种: 一类是集合数据类型,如list.tuple.dict.set.str等: 一类是generator,包括生成器和带 ...
- verilog分频模块设计
verilog设计: 分频器的设计: 分频器就是将一个时钟源的频率降低的过程(可以通过观察分频之后周期中包含几个原时钟周期来看是几分频),分频分为基数分频也分为偶数分频, 偶数分频的代码如下:(其中就 ...
- php socket如何实现长连接
长连接是什么? 朋友们应该都见过很多在线聊天工具和网页在线聊天的工具.学校内有一种熟悉的功能,如果有人回复你了,网站会马上出现提示,此时你并没有刷新页面:Gmail也有此功能,如果邮箱里收到了新的邮件 ...
- maven模块开发(转)
所有用Maven管理的真实的项目都应该是分模块的,每个模块都对应着一个pom.xml.它们之间通过继承和聚合(也称作多模块,multi-module)相互关联.那么,为什么要这么做呢?我们明明在开发一 ...
- Django学习系列13:Django ORM和第一个模型
ORM—对象关系映射器,是一个数据抽象层,描述存储在数据库中的表,行和列.处理数据库时,可以使用熟悉的面向对象方式,写出更好的代码. 在ORM的概念中,类对应数据库中的表,属性对应列,类的单个实例表示 ...
- usb四种传输模式bulk
当USB插入USB总线时,USB控制器会自动为该USB设备分配一个数字来标示这个设备.另外,在设备的每个端点都有一个数字来表明这个端点.USB设备驱动向USB控制器驱动请求的每次传输被称为一个事务(T ...
- string::find_first_of
string (1) size_t find_first_of (const string& str, size_t pos = 0) const noexcept; c-string (2) ...
- The Preliminary Contest for ICPC Asia Nanchang 2019 E. Magic Master
题目:https://nanti.jisuanke.com/t/41352 思路:约瑟夫环 由题意得第k张牌即求 k 为 第几个 报数为m+1 的单位 用队列模拟即可 #include<bits ...