insightface作者提供数据训练解读
1.下载源码:
开源代码地址:https://github.com/deepinsight/insightface
2.查看作者项目训练要求
(1)训练数据
训练数据使用作者提供并制作好的数据,如下图所示:
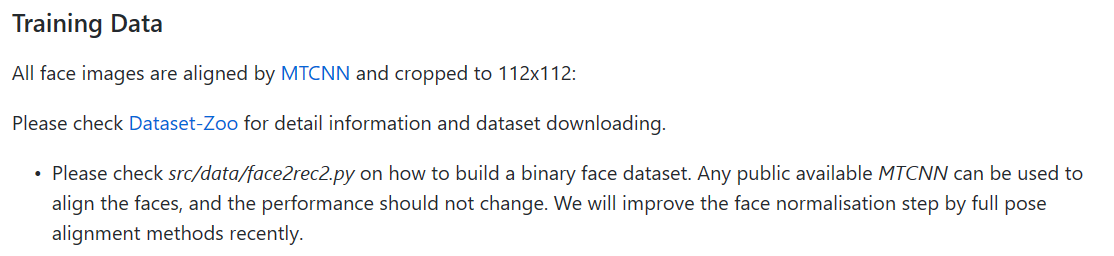
点击Dataset-Zoo进入数据下载中心,如下图所示:
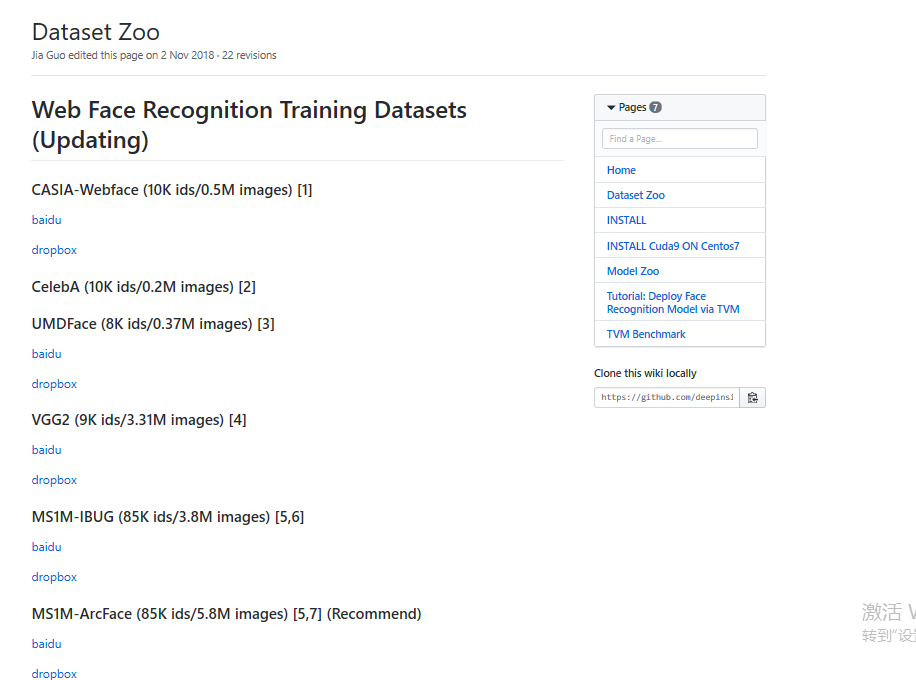
本人训练数据为MS1M-ArcFace,选择自己想要训练的数据都可以。
(2)训练要求如下图所示:
a.

由于在本地配置环境问题比较多,本人直接拉取mxnet-cu90镜像,省去好多麻烦事,可参考我的博客https://www.cnblogs.com/liuwenhua/p/11537696.html,有详细解读。
b.下载代码放到自己的目录下:

c.数据解读:
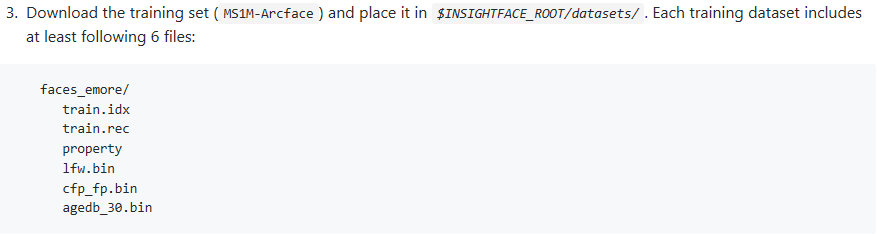
根据作者要求把下载数据放到datastes目录下,六个文件中前三个是训练数据需求,后三个是验证数据。
打开文件property,如下图:
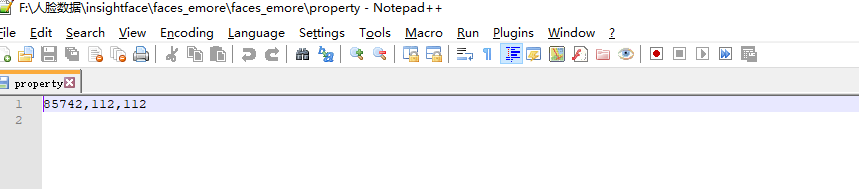
85742为类别数,根据不同数据需要更改代码,后续提到。112,112为图片大小。
d.ubuntu环境设置及代码编辑
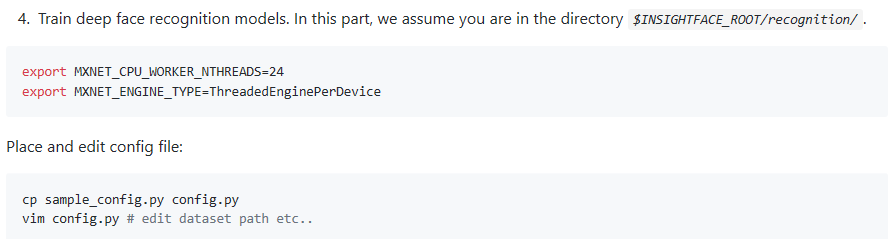
具体方法如下:
创建sh文件:进入到recognition,编辑
vim run_train.sh
编辑下面两行代码
export MXNET_CPU_WORKER_NTHREADS=24
export MXNET_ENGINE_TYPE=ThreadedEnginePerDevice
执行命令如下:
cp sample_config.py config.py
vim config.py
显示如下图所示:

根据自己的下载的数据或制作的数据需要添加代码在dataset =edict()下面
dataset.emore = edict()
dataset.emore.dataset = 'emore'
dataset.emore.dataset_path = '../datasets/faces_emore'
dataset.emore.num_classes = 85742
dataset.emore.image_shape = (112,112,3)
dataset.emore.val_targets = ['lfw', 'cfp_fp', 'agedb_30']
①更改的第一个就是上面的emore,根据自己的喜好
②更改dataset.emore.dataset_path路径
③dataset.emore.num_classes,训练数据的类别数
(3)开始训练

我的设备是两块RTX2080ti,运行代码如下:
CUDA_VISIBLE_DEVICES='0,1' python -u train.py --network r100 --loss arcface --dataset emore
由于在运行过程中提示显存不足,所以要设置bach_size,为了方便运行,我们添加下面代码到run_train.sh文件中
export MXNET_CPU_WORKER_NTHREADS=24
export MXNET_ENGINE_TYPE=ThreadedEnginePerDevice CUDA_VISIBLE_DEVICES='0,1' python -u train.py --network r100 --loss arcface --dataset emore --per-batch-size 36
保存退出,在终端运行
bash run_train.sh
模型开始训练,如下图:
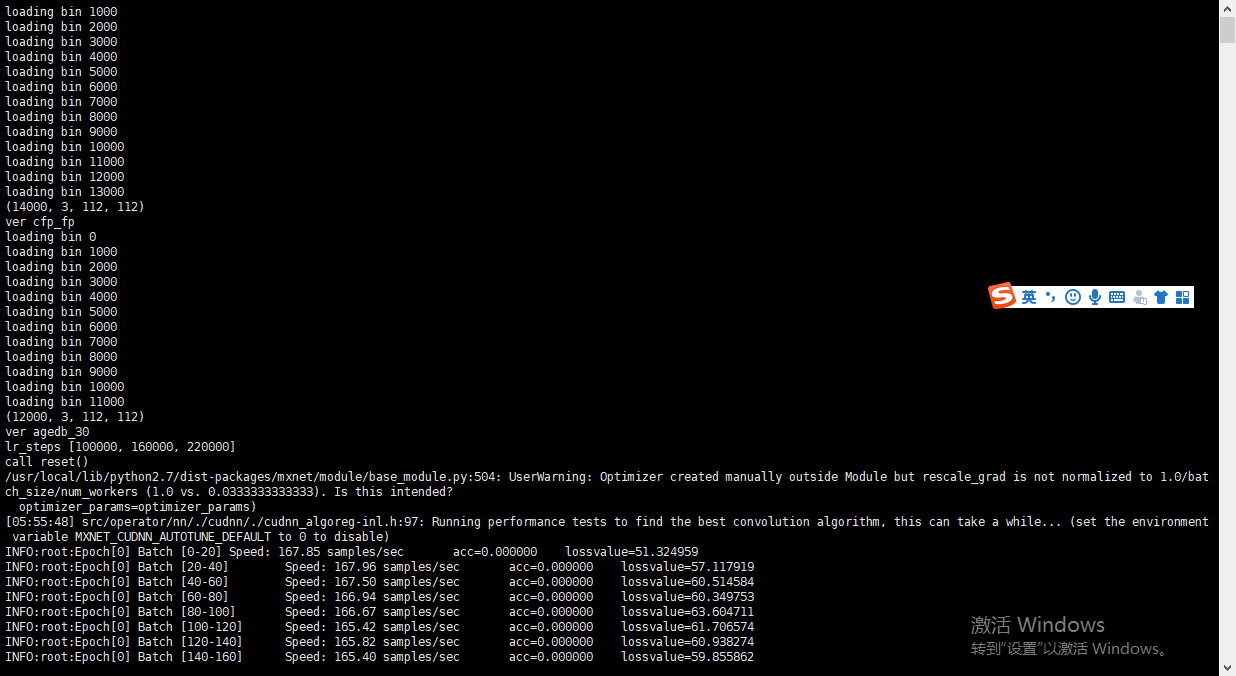
后续准备制作自己的训练数据,后续更新
insightface作者提供数据训练解读的更多相关文章
- 利用VGG19实现火灾分类(附tensorflow代码及训练集)
源码地址 https://github.com/stephen-v/tensorflow_vgg_classify 1. VGG介绍 1.1. VGG模型结构 1.2. VGG19架构 2. 用Ten ...
- 利用卷积神经网络(VGG19)实现火灾分类(附tensorflow代码及训练集)
源码地址 https://github.com/stephen-v/tensorflow_vgg_classify 1. VGG介绍 1.1. VGG模型结构 1.2. VGG19架构 2. 用Ten ...
- PSPnet:Pyramid Scene Parsing Network——作者认为现有模型由于没有引入足够的上下文信息及不同感受野下的全局信息而存在分割出现错误的情景,于是,提出了使用global-scence-level的信息的pspnet
from:https://blog.csdn.net/bea_tree/article/details/56678560 2017年02月23日 19:28:25 阅读数:6094 首先声明,文末彩蛋 ...
- BERT论文解读
本文尽量贴合BERT的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进行翻译,其中有一些论文没有解释清楚或者笔者未能深入理解的地方,都有放出原文,如有不当之处,请各位多多包含,并 ...
- 转 googlenet论文解读
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/u014061630/article/det ...
- NLP中的预训练语言模型(五)—— ELECTRA
这是一篇还在双盲审的论文,不过看了之后感觉作者真的是很有创新能力,ELECTRA可以看作是开辟了一条新的预训练的道路,模型不但提高了计算效率,加快模型的收敛速度,而且在参数很小也表现的非常好. 论文: ...
- InisghtFace 制作自定义数据集和模型训练评估
前言 本文以lfw数据集进行示例 lfw结果集下载地址:http://vis-www.cs.umass.edu/lfw/lfw.tgz insightface源码下载地址:https://github ...
- 重磅解读:K8s Cluster Autoscaler模块及对应华为云插件Deep Dive
摘要:本文将解密K8s Cluster Autoscaler模块的架构和代码的Deep Dive,及K8s Cluster Autoscaler 华为云插件. 背景信息 基于业务团队(Cloud BU ...
- 基于RNN的音频降噪算法 (附完整C代码)
前几天无意间看到一个项目rnnoise. 项目地址: https://github.com/xiph/rnnoise 基于RNN的音频降噪算法. 采用的是 GRU/LSTM 模型. 阅读下训练代码,可 ...
随机推荐
- Linux scp 免密码 传输文件
Linux scp 免密码 传输文件 背景介绍 最近项目是集群化部署(由 node1,node2,node3 三台 CentOS 7.4 的虚拟机构成). 但是,涉及到跨机器同步文件的问题,想通过写s ...
- 【D3D12学习手记】4.1.6 Resources and Descriptors
在渲染过程中,GPU将写资源(resources)(例如,后缓冲区,深度/模板缓冲区),读资源(例如,描述表面外观的纹理,存储场景中几何体3D位置的缓冲区).在我们发出绘图命令之前,我们需要将资源绑定 ...
- java:Linux(简单命令,远程ssh使用hostname访问,.免密钥登录配置)
1.临时关闭防火墙: service iptables stop 临时开启防火墙: service iptables start 查看防火墙状态: service iptables sta ...
- MybatisPlus使用代码篇
package spring.server.consumer; import com.baomidou.mybatisplus.annotation.DbType; import com.baomid ...
- QT5中编译存在的几个问题(LNK2019,构造函数不能有返回类型)
1. 自己构造新类,注意必须在头文件最后加上分号 写个c++类报“构造函数不能有返回类型”, 谷歌一下,才找到原因: 原来是我定义的类后面没有用“:”结尾,构造函数默认把整个类作为返回值了 2. 新建 ...
- Identification of Encryption Algorithm Using Decision Tree
本文主要做了两件事,一是提出了一种使用C4.5算法生成的决策树来识别密文所使用的加密算法的方法,二是为这一算法设计了一个特征提取系统提取八个特征作为算法的输入,最终实现了70%~75的准确率. 准备工 ...
- eclipse 导出jar 没有主清单属性的解决方法
eclipse编写导出的jar文件,运行出现了没有主清单属性,问题在哪里呢?有下面几种方法: 1. 导出jar文件的时候选择[可运行的jar文件]而不是[Jar文件]即可,如下图: 2. 在jar文件 ...
- 单机版的mysql安装
查是否安装了mysql:centos6:rpm -qa |grep mysqlcentos7:rpm -qa|grep mariadb或rpm -qa |grep mysql 有老的版本可以执行命令卸 ...
- mysql大数据量插入参考
Mysql 千万数据10秒批量插入只需三步第一步:配置my.ini文件文件中配置bulk_insert_buffer_size=120M 或者更大将insert语句的长度设为最大.Max_allowe ...
- [转帖] Linux下面计算文件数量的方法
Linux命令-查看目录下文件个数 2018年07月04日 10:37:07 sand_clock 阅读数 2002 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blo ...