nodejs爬虫编码问题
最近再做一个nodejs网站爬虫的项目,但是爬一些网站的数据出现了中文字符乱码的问题。查了一下,主要是因为不是所有的网站的编码格式都是utf-8,还有一些网站用的是gb2312或者gbk的编码格式。所以需要做一个处理来进行编码的解码。至于网站的编码怎么看,可以通过去检查中的network去看。
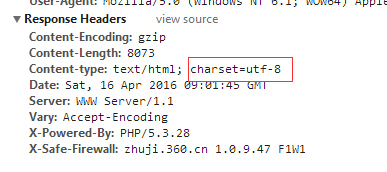
根据相应的编码格式,进行相应的设置。utf-8就不要说了,下面就以gbk为例,说一下解码的方式。
var request = require('request');
var cheerio = request('cheerio');
var iconv = require('iconv-lite');
request ({
url : 'http://www.taobao.com',
encodeing = null
},function(err,res,body){
if (err) throw err;
// decode the content of the website
body = iconv.decode(body,'gbk');
var $ = cheerio.load(body);
console.log($('head title').text());
})或者是使用一个gbk包,但我觉得还是上面的方式比较好。
nodejs爬虫编码问题的更多相关文章
- 【nodeJS爬虫】前端爬虫系列
写这篇 blog 其实一开始我是拒绝的,因为爬虫爬的就是cnblog博客园.搞不好编辑看到了就把我的账号给封了:). 言归正传,前端同学可能向来对爬虫不是很感冒,觉得爬虫需要用偏后端的语言,诸如 ph ...
- NodeJS 爬虫爬取LOL英雄联盟的英雄信息,批量下载英雄壁纸
工欲善其事,必先利其器,会用各种模块非常重要. 1.模块使用 (1)superagent:Nodejs中的http请求库(每个语言都有无数个,java的okhttp,OC的afnetworking) ...
- Nodejs爬虫进阶教程之异步并发控制
Nodejs爬虫进阶教程之异步并发控制 之前写了个现在看来很不完美的小爬虫,很多地方没有处理好,比如说在知乎点开一个问题的时候,它的所有回答并不是全部加载好了的,当你拉到回答的尾部时,点击加载更多,回 ...
- NodeJS爬虫系统初探
NodeJS爬虫系统 NodeJS爬虫系统 0. 概论 爬虫是一种自动获取网页内容的程序.是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上是针对爬虫而做出的优化. robots.txt是一个文本文 ...
- nodejs爬虫——汽车之家所有车型数据
应用介绍 项目Github地址:https://github.com/iNuanfeng/node-spider/ nodejs爬虫,爬取汽车之家(http://www.autohome.com.cn ...
- nodejs爬虫笔记(三)---爬取YouTube网站上的视频信息
思路:通过笔记(二)中代理的设置,已经可以对YouTube的信息进行爬取了,这几天想着爬取网站下的视频信息.通过分析YouTube,发现可以从订阅号入手,先选择几个订阅号,然后爬取订阅号里面的视频分类 ...
- nodejs爬虫笔记(二)---代理设置
node爬虫代理设置 最近想爬取YouTube上面的视频信息,利用nodejs爬虫笔记(一)的方法,代码和错误如下 var request = require('request'); var chee ...
- 简单实现nodejs爬虫工具
约30行代码实现一个简单nodejs爬虫工具,定时抓取网页数据. 使用npm模块 request---简单http请求客户端.(轻量级) fs---nodejs文件模块. index.js var ...
- 第一个nodejs爬虫:爬取豆瓣电影图片
第一个nodejs爬虫:爬取豆瓣电影图片存入本地: 首先在命令行下 npm install request cheerio express -save; 代码: var http = require( ...
随机推荐
- 微信小程序-tabBar-注意事项
tabBar.list[0].selectedIconPath 文件格式错误,仅支持 .png..jpg..jpeg 格式
- LTE系统时延及降低空口时延的4种方案
转载:https://rf.eefocus.com/article/id-LTE%20delay 对于移动通信业务而言,最重要的时延是端到端时延, 即对于已经建立连接的收发两端,数据包从发送端产生,到 ...
- 关于vs2019
一.vs2019中的MFC 在想创建一个基于对话的应用时找不着模版了,这下可慌了,试遍了已有的各个模版都没要,要么就是缺少头文件,我在想是不是少安装了什么选项.重装了相关模块,最后又核对了一遍,都对. ...
- Python3 面向对象-类的继承与派生
1.什么是继承? 继承是一种创建新类的方式,新建的类可以继承一个或多个父类(python支持多继承),父类可称为基类或超类,新建的类称为派生类和或子类. 子类会遗传父类的属性,从而解决代码重用问题. ...
- [思路题][LOJ2290][THUWC2017]随机二分图:状压DP+期望DP
分析 考虑状压DP,令\(f[sta]\)表示已匹配状态是\(sta\)(\(0\)代表已匹配)时完美匹配的期望数量,显然\(f[0]=1\). 一条边出现了不代表它一定在完美匹配内,这也导致很难去直 ...
- view组件
view标签的属性值: hover-class:按下的点击态 属性值:字符串 如果:hover-class="none" 按下就没有点击态 hover-stop-pro ...
- DAY 6 TEST
test T1 样例输入 样例输出 答案选择u,v作为关键点 暴力的话k^2枚举跑最短路,寻找最小值就行了 50pts 考虑优化枚举量 因为答案的两个点是不同的点,所以编号的二进制表示中至少一位不同 ...
- xml json mongo
w wuser@ubuntu:~/apiamzpy$ sudo pip install xmljson
- CSS - 视觉格式化模型(Visual formatting model)
几个概念 块:block,一个抽象的概念,块与块之间在垂直方向上按照顺序依次堆叠. 行内:inline,一个抽象的概念,行内与行内之间在水平方向上按照顺序依次堆叠(会有换行). 元素:element, ...
- python-加密(base64)
import base64 #base64也是用来加密的,但是这个是可以解密的 s = "username" byte类型print(base64.b64encode(s.enco ...