Centos7.4 Storm2.0.0 + Zookeeper3.5.5 高可用集群搭建
想了下还是把kafka集群和storm集群分开比较好
集群规划:
| Nimbus | Supervisor | |
|---|---|---|
| storm01 | √ | √ |
| storm02 | √(备份) | √ |
| storm03 | √ |
准备工作
老样子复制三台虚拟机, 修改网络配置, host名及host文件, 关闭防火墙
- vim /etc/sysconfig/network-scripts/ifcfg-ens33 修改网络配置
# storm01
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.180.170 # 你的虚拟网卡VMNet8, 如果是桥接的改成桥接网卡VMNet1
PREFIX=24
GATEWAY=192.168.180.2
DNS1=114.114.114.114
IPV6_PRIVACY=no
# storm02
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.180.171 # 你的虚拟网卡VMNet8, 如果是桥接的改成桥接网卡VMNet1
PREFIX=24
GATEWAY=192.168.180.2
DNS1=114.114.114.114
IPV6_PRIVACY=no
# storm03
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.180.172 # 你的虚拟网卡VMNet8, 如果是桥接的改成桥接网卡VMNet1
PREFIX=24
GATEWAY=192.168.180.2
DNS1=114.114.114.114
IPV6_PRIVACY=no
vim /etc/hostname 将hostname分别修改为storm01, storm02, storm03
vim /etc/hosts 修改host文件
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
192.168.180.170 storm01
192.168.180.171 storm02
192.168.180.172 storm03
关闭防火墙: service firewalld stop
免密登录: ssh-keygen 生成RSA公钥私钥
ssh-keygen
# 然后enter, enter, enter 直到生成RSA, 默认会在当前用户的家目录下生成.ssh [root@storm01 ~]# ls -ah
. anaconda-ks.cfg .bash_logout .bashrc .config .dbus .pki .tcshrc .xauthEJoei0
.. .bash_history .bash_profile .cache .cshrc initial-setup-ks.cfg .ssh .viminfo .Xauthority
.ssh隐藏目录中有id_rsa(私钥) 和 id_rsa.pub(公钥)
cd ~/.ssh 创建authorized_keys,将三台虚拟机的公钥都存入其中:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDdS1NsbxsccW/6YMkUKZ4BUNYXnFw9Iapwl/xM/THaILWi3VyAVIOY1cT1BgfS01NxpcUI/aqBIwZvWgKEdJe8XL4fJgAHgkJklbP5LRd1eI6CprLTn0RJNaZuRDX2GqPkmsz+1pRZo6TBuzx1q1sPrUEeH6GYR/oQWm8JTLFs8ppXeu0prsNAehl1MvT0xEpegdc7CVGTHyZUuOV8/nxBHux0motRJpy0UpQCY/abazhy+CQ/TS8/VQu3mAsdK/5KIHwyR92NPnUP7w89f1BsEgywFMgOhbLmsqfaDXVvCB38AfzQOKqdXL2CExyKTAEDwU6+AIX6Clm/UCrn1hPN root@storm01 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDZ05EemLXkNiWXuM6WSHWhs9uGI5PVacNgI7KctAK1UgOZwcBOu2UZqk1nTvboIz0yYfFKBjvY2Ea4eBh5VzOqqJh7JmHm+58px34h+qmpdYvlnnmi2Bhu9vr9DO9EeqlmKxVDc9kqfjTWbLpLsrg+0K9KGVZwOXXvRtVRT2k88NbMegGRwsG03/H8uaBpOOUYyAe3vNqqgpg/5rnt824ZUWUaHKHGyQegIxejFrC5nhhejTPQ5PIDdxWIckhnvRASUXMEsoj7k7CKRD9HA4+o5XuzTyJ/tVYIheyK8k82LOoHKocXsbb5wJ7sLBuDaS2y63ZOc2AjoEtttkxvgjUB root@storm02 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDN3QLZWNzQRp/4G0vTIGWtD2vS11B7g0rGyaBYobR/JYMddJV7jeuu7lbb3wWxpJo/AdwrLJNBRG9uFmFBpHdbX6JUz5anz+tb4hWVUAzDN1oNt+ZL7F0SCeQGx1EBHCYeAT12S0U8wfOpeS8/92m4Bm2ngKxbPKO9r6cAfzI2xngJKQ1jEbejzOulE9BiIvdAkFza8e3voqb1QQaLUHfUbW/VGXe+f/LAzpeAk7oFMwvealnyckpwYbxFaTjMrKwyvx3Gpe0iXoFeiYdBJOQZmmpntQRrymyvWg9iqG69ynQlCaA6OU6PV324hzy77vxL+c3yQFn3IVXf7rNTnspR root@storm03
免密登录测试:
[root@storm01 ~]# ssh root@192.168.180.171
Last login: Sat Oct 19 22:35:56 2019 from storm01
[root@storm02 ~]#
ps: 第一次会提示是否将该秘钥保存, 保存后.ssh文件目录下会生成一个known_hosts,里面存有已知的主机sha(Security HashCode Algorithum)信息
jdk安装
本机上已经安装好了jdk, jdk安装和配置请参考:
Zookeeper安装
- 本机上已经安装好了Zookeeper, Zookeeper安装和配置请参考:
- https://www.cnblogs.com/ronnieyuan/p/11622315.html
- 区别就是集群名称不同
Storm的安装
上传tar包

解压tar包到指定目录并修改名称
tar -zxvf apache-storm-2.0.0.tar.gz -C /opt/ronnie/ mv apache-storm-2.0.0/ storm-2.0.0
修改配置文件
vim /opt/ronnie/storm-2.0.0/conf/storm.yaml
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License. ########### These MUST be filled in for a storm configuration
# 指定Zookeeper服务器
storm.zookeeper.servers:
- "storm01"
- "storm02"
- "storm03"
# 指定storm集群中的nimbus节点所在的服务器
nimbus.seeds: ["storm01", "storm02", "storm03"] # 指定文件存放目录
storm.local.dir: "/var/storm"
#
# 指定supervisor节点上, 启动worker时对应的端口号, 每个端口对应槽, 每个槽对应一个worker
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
# 指定web ui 的端口为9099
ui.port: 9099
#
# ##### These may optionally be filled in:
#
## List of custom serializations
# topology.kryo.register:
# - org.mycompany.MyType
# - org.mycompany.MyType2: org.mycompany.MyType2Serializer
#
## List of custom kryo decorators
# topology.kryo.decorators:
# - org.mycompany.MyDecorator
#
## Locations of the drpc servers
# drpc.servers:
# - "server1"
# - "server2" ## Metrics Consumers
## max.retain.metric.tuples
## - task queue will be unbounded when max.retain.metric.tuples is equal or less than 0.
## whitelist / blacklist
## - when none of configuration for metric filter are specified, it'll be treated as 'pass all'.
## - you need to specify either whitelist or blacklist, or none of them. You can't specify both of them.
## - you can specify multiple whitelist / blacklist with regular expression
## expandMapType: expand metric with map type as value to multiple metrics
## - set to true when you would like to apply filter to expanded metrics
## - default value is false which is backward compatible value
## metricNameSeparator: separator between origin metric name and key of entry from map
## - only effective when expandMapType is set to true
## - default value is "."
# topology.metrics.consumer.register:
# - class: "org.apache.storm.metric.LoggingMetricsConsumer"
# max.retain.metric.tuples: 100
# parallelism.hint: 1
# - class: "org.mycompany.MyMetricsConsumer"
# max.retain.metric.tuples: 100
# whitelist:
# - "execute.*"
# - "^__complete-latency$"
# parallelism.hint: 1
# argument:
# - endpoint: "metrics-collector.mycompany.org"
# expandMapType: true
# metricNameSeparator: "." ## Cluster Metrics Consumers
# storm.cluster.metrics.consumer.register:
# - class: "org.apache.storm.metric.LoggingClusterMetricsConsumer"
# - class: "org.mycompany.MyMetricsConsumer"
# argument:
# - endpoint: "metrics-collector.mycompany.org"
#
# storm.cluster.metrics.consumer.publish.interval.secs: 60 # Event Logger
# topology.event.logger.register:
# - class: "org.apache.storm.metric.FileBasedEventLogger"
# - class: "org.mycompany.MyEventLogger"
# arguments:
# endpoint: "event-logger.mycompany.org" # Metrics v2 configuration (optional)
#storm.metrics.reporters:
# # Graphite Reporter
# - class: "org.apache.storm.metrics2.reporters.GraphiteStormReporter"
# daemons:
# - "supervisor"
# - "nimbus"
# - "worker"
# report.period: 60
# report.period.units: "SECONDS"
# graphite.host: "localhost"
# graphite.port: 2003
#
# # Console Reporter
# - class: "org.apache.storm.metrics2.reporters.ConsoleStormReporter"
# daemons:
# - "worker"
# report.period: 10
# report.period.units: "SECONDS"
# filter:
# class: "org.apache.storm.metrics2.filters.RegexFilter"
# expression: ".*my_component.*emitted.*"将storm目录 递归发送给 其他虚拟机
scp -r /opt/ronnie/storm-2.0.0/ root@192.168.180.171:/opt/ronnie/
scp -r /opt/ronnie/storm-2.0.0/ root@192.168.180.172:/opt/ronnie/
创建storm启动和停止shell脚本
cd /opt/ronnie/storm-2.0.0/bin/ 进入bin目录
vim start-storm-all.sh
#!/bin/bash
#nimbus节点
nimbusServers='storm01 storm02' #supervisor节点
supervisorServers='storm01 storm02 storm03' #启动所有的nimbus
for nim in $nimbusServers
do
ssh -T $nim <<EOF
nohup /opt/ronnie/storm-2.0.0/bin/storm nimbus >/dev/null 2>&1 &
EOF
echo 从节点 $nim 启动nimbus...[ done ]
sleep 1
done #启动所有的ui
for u in $nimbusServers
do
ssh -T $u <<EOF
nohup /opt/ronnie/storm-2.0.0/bin/storm ui >/dev/null 2>&1 &
EOF
echo 从节点 $u 启动ui...[ done ]
sleep 1
done #启动所有的supervisor
for visor in $supervisorServers
do
ssh -T $visor <<EOF
nohup /opt/ronnie/storm-2.0.0/bin/storm supervisor >/dev/null 2>&1 &
EOF
echo 从节点 $visor 启动supervisor...[ done ]
sleep 1
done ~vim stop-storm-all.sh
!/bin/bash #nimbus节点
nimbusServers='storm01 storm02' #supervisor节点
supervisorServers='storm01 storm02 storm03' #停止所有的nimbus和ui
for nim in $nimbusServers
do
echo 从节点 $nim 停止nimbus和ui...[ done ]
ssh $nim "kill -9 `ssh $nim ps -ef | grep nimbus | awk '{print $2}'| head -n 1`" >/dev/null 2>&1
ssh $nim "kill -9 `ssh $nim ps -ef | grep core | awk '{print $2}'| head -n 1`" >/dev/null 2>&1
done #停止所有的supervisor
for visor in $supervisorServers
do
echo 从节点 $visor 停止supervisor...[ done ]
ssh $visor "kill -9 `ssh $visor ps -ef | grep supervisor | awk '{print $2}'| head -n 1`" >/dev/null 2>&1
done给予 创建的sh文件 执行权限
chmod u+x start-storm-all.sh
chmod u+x stop-storm-all.sh
vim /etc/profile 修改环境变量, 添加Storm路径
export STORM_HOME=/opt/ronnie/storm-2.0.0
export PATH=$STORM_HOME/bin:$PATH
将 启动 和停止配置文件转发给其他虚拟机(其实主要是主节点, 刚忘记了, 改的备用节点)
scp start-storm-all.sh root@192.168.180.170:/opt/ronnie/storm-2.0.0/bin/
scp start-storm-all.sh root@192.168.180.172:/opt/ronnie/storm-2.0.0/bin/
scp stop-storm-all.sh root@192.168.180.170:/opt/ronnie/storm-2.0.0/bin/
scp stop-storm-all.sh root@192.168.180.172:/opt/ronnie/storm-2.0.0/bin/
启动Zookeeper: zkServer.sh start
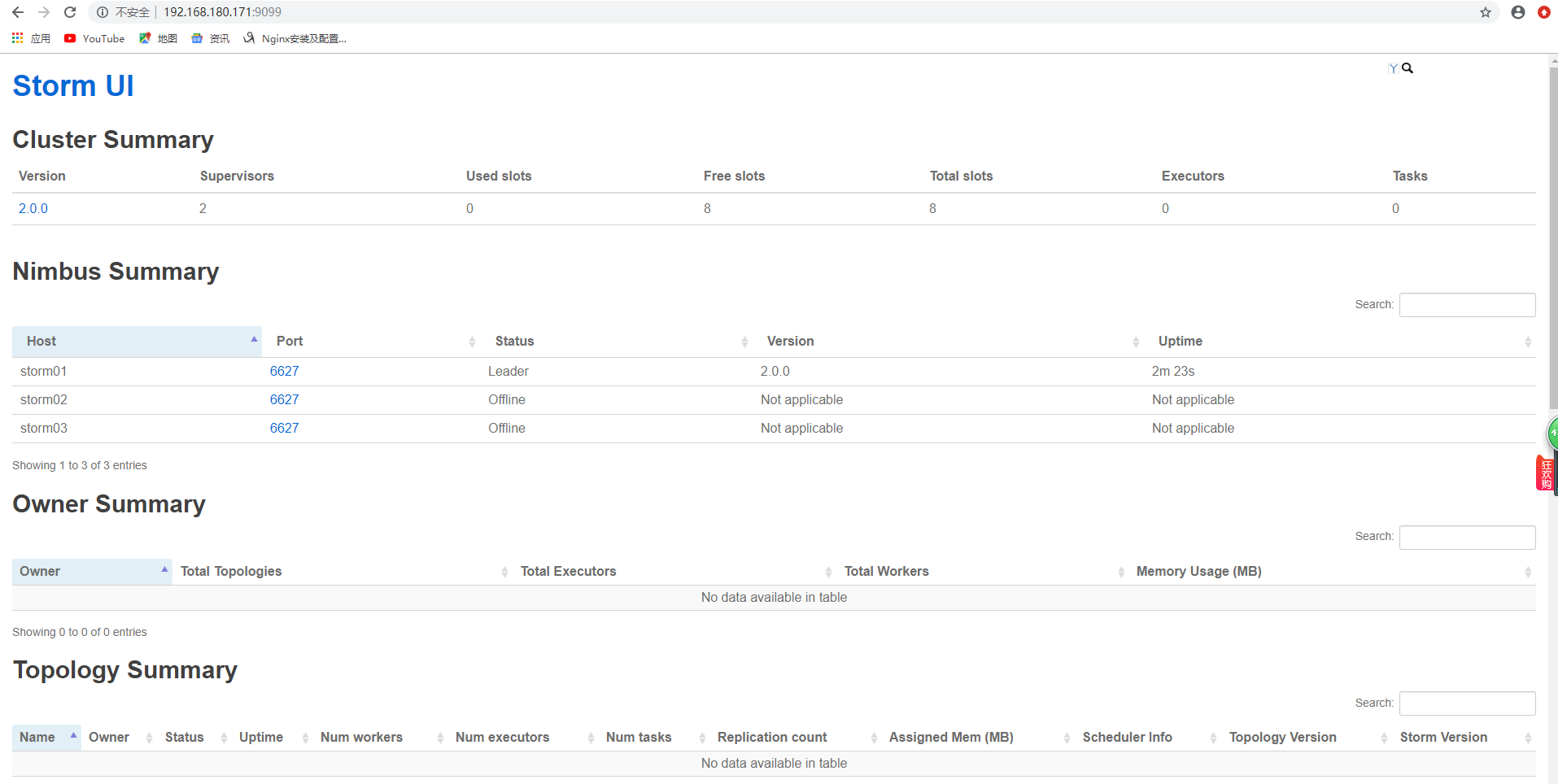
启动Storm:
start-storm-all.sh
# 关闭
stop-storm-all.sh
Centos7.4 Storm2.0.0 + Zookeeper3.5.5 高可用集群搭建的更多相关文章
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- .Net Core2.1 秒杀项目一步步实现CI/CD(Centos7.2)系列一:k8s高可用集群搭建总结以及部署API到k8s
前言:本系列博客又更新了,是博主研究很长时间,亲自动手实践过后的心得,k8s集群是购买了5台阿里云服务器部署的,这个集群差不多搞了一周时间,关于k8s的知识点,我也是刚入门,这方面的知识建议参考博客园 ...
- CentOS7/RHEL7 pacemaker+corosync高可用集群搭建
TOC \o "1-3" \h \z \u 一.集群信息... PAGEREF _Toc502099174 \h 4 08D0C9EA79F9BACE118C8200AA004B ...
- MySQL8.0 MIC高可用集群搭建
mysql8.0带来的新特性,结合MySQLshell,不需要第三方中间件,自动构建高可用集群. mysql8.0作为一款新产品,其内置的mysq-innodb-cluster(MIC)高可用集群的技 ...
- CentOS7 haproxy+keepalived实现高可用集群搭建
一.搭建环境 CentOS7 64位 Keepalived 1.3.5 Haproxy 1.5.18 后端负载主机:192.168.166.21 192.168.166.22 两台节点上安装rabbi ...
- Redis Cluster 4.0高可用集群安装、在线迁移操作记录
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- (七) Docker 部署 MySql8.0 一主一从 高可用集群
参考并感谢 官方文档 https://hub.docker.com/_/mysql y0ngb1n https://www.jianshu.com/p/0439206e1f28 vito0319 ht ...
- RabbitMQ从零到集群高可用(.NetCore5.0) -高可用集群构建落地
系列文章: RabbitMQ从零到集群高可用(.NetCore5.0) - RabbitMQ简介和六种工作模式详解 RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列 ...
- Centos7.5基于MySQL5.7的 InnoDB Cluster 多节点高可用集群环境部署记录
一. MySQL InnoDB Cluster 介绍MySQL的高可用架构无论是社区还是官方,一直在技术上进行探索,这么多年提出了多种解决方案,比如MMM, MHA, NDB Cluster, G ...
随机推荐
- COGS 2294. [HZOI 2015] 释迦
额,其实就是裸的三模数NTT,上一篇已经说过了 哦,还有一个就是对乘起来炸long long的数取模,用long double之类的搞一下就好,精度什么的,,(看出题人心情??) #include&l ...
- 「CF1039D」You Are Given a Tree
传送门 Luogu 解题思路 整体二分. 的确是很难看出来,但是你可以发现输出的答案都是一些可以被看作是关键字处于 \([1, n]\) 的询问,而答案的范围又很显然是 \([0, n]\),这不就刚 ...
- Python—网络通信编程之udp通信编程
服务端代码 import socket # 1.创建实例,即数据报套接字 server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 2.绑 ...
- Springboot项目的接口防刷(实例)
技术要点:springboot的基本知识,redis基本操作, 首先是写一个注解类: import java.lang.annotation.Retention; import java.lang.a ...
- sqlite帮助类
帮助类 using System; using System.Collections.Generic; using System.Data; using System.Data.SQLite; usi ...
- Python测试进阶——(6)Bash脚本启动Python监控程序并传递PID
用HiBench执行Hadoop——Sort测试用例,进入 /HiBench-master/bin/workloads/micro/sort/hadoop 目录下,执行命令: [root@node1 ...
- day02-Python运维开发基础
1. Number 数据类型 2. 容器数据类型-字符串 """ 语法: "字符串" % (值1,值2 ... ) 占位符: %d 整型占位符 %f ...
- 查看Python安装目录 -- 一个命令
pip --version
- 024、MySQL字符串替换函数,文本替换函数
#文本替换 ,,'); #520ABCDEFG ,,'); #520BCDEFG ,,'); #520CDEFG ,,'); #A520BCDEFG ,,'); #A520CDEFG ,,'); #A ...
- 模拟一次sql注入攻击
在你的web服务目录下 创建一个php文件如下 <?php $conn = db_connect(); $sql = sprintf('update users set password = & ...